
TLDR
LM Arena作為新一代AI大模型評測平台,徹底改變了傳統基準測試的評估方式。透過匿名對戰機制和真實用戶投票,平台每天進行上千場模型對決,讓GPT、Claude、Gemini、DeepSeek等頂尖模型在真實場景中較量。儘管面臨公平性爭議和商業化質疑,LM Arena仍成為業界重要的評測標準,推動AI評估從靜態考試走向動態競技場。本文深入探討LM Arena的運作機制、技術創新、面臨挑戰,以及AI模型評測的未來趨勢。
AI大模型評測進入新時代:LM Arena崛起的背景
在AI大模型激烈競爭的當下,一個核心問題始終困擾著業界:究竟誰才是最強大的模型?是OpenAI的GPT系列、Anthropic的Claude、Google的Gemini,還是中國的DeepSeek?當各家AI模型排行榜開始出現刷分作弊現象後,這個問題變得極度主觀。直到LM Arena的誕生,大模型評測領域才迎來真正的變革。
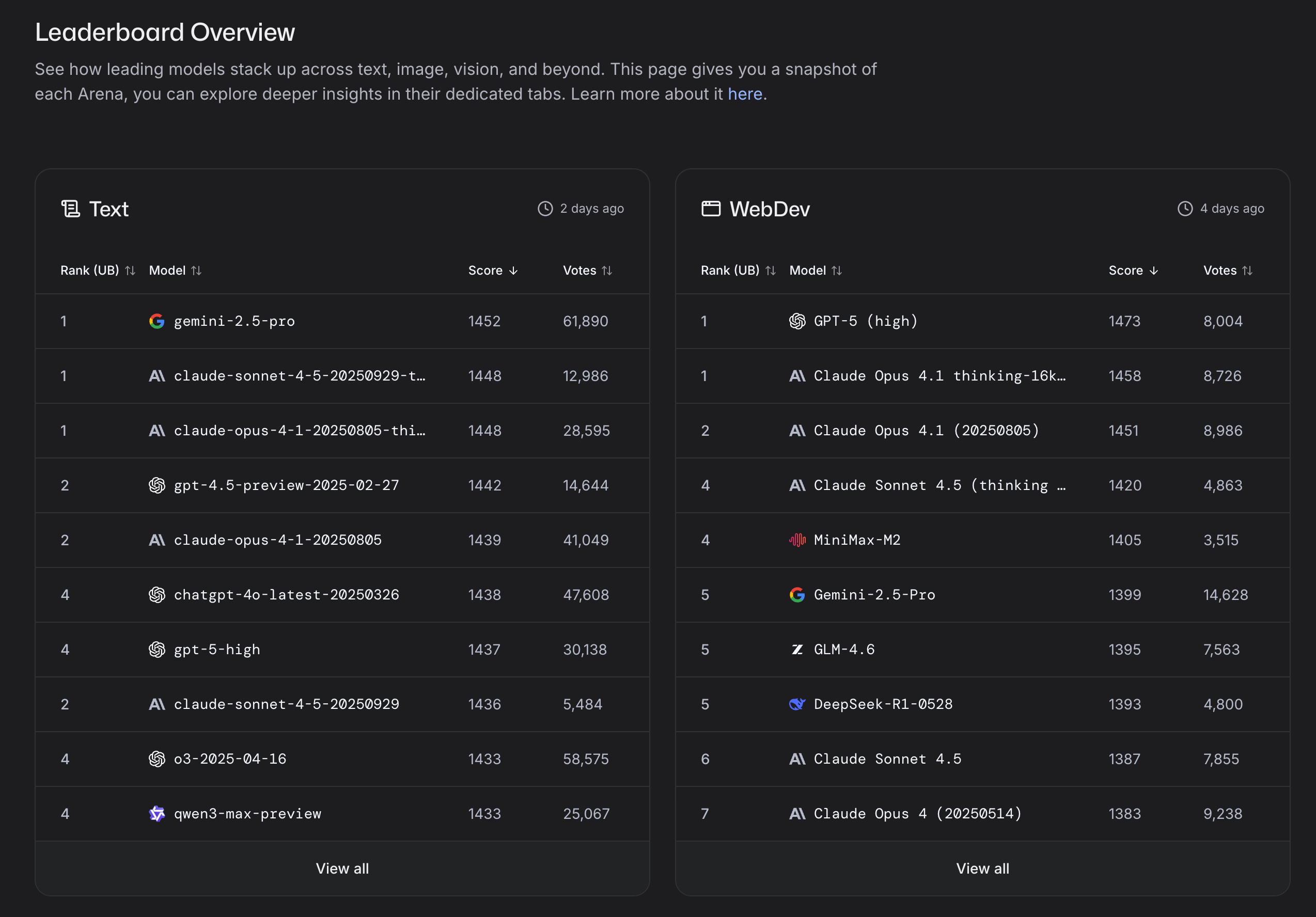
LM Arena(Large Model Arena)是一個線上AI競技平台,採用匿名對戰和真實用戶投票的方式進行模型評測。這個平台最為人津津樂道的案例,就是Google的神秘模型經常以代號形式率先在此出現。例如近期網友發現,Gemini 3.0已經悄然現身LM Arena,其中Pro版本代號為「Lithen Flow」,而Flush版本則是「Orion Mist」,據稱具備讀譜、作曲和演奏等全方位能力提升。
在正式發布新模型之前於LM Arena進行測試,已成為Google的慣例操作。實際上,OpenAI、Anthropic、Meta的Llama、DeepSeek、混元以及幾乎所有頂尖AI模型,都將LM Arena視為常規賽場,用來測試普通用戶最真實的反饋。平台每天進行上千場實時對戰,涵蓋文字、視覺、搜索、文生圖、文生視頻等不同AI大模型細分領域。
傳統Benchmark評測的局限性與困境
在LM Arena出現之前,AI大模型評估方式相當傳統。研究者通常準備一組固定題庫,透過讓不同模型作答,再根據答對率或得分進行比較。這些基準測試在AI學術界家喻戶曉,主導整個研究領域長達二十年。
| 基準測試名稱 | 測試重點 | 涵蓋範圍 |
|---|---|---|
| MMLU (Massive Multitask Language Understanding) | 多任務語言理解 | 涵蓋57個知識領域,從高中到博士級別,包含法律、數學、哲學等 |
| Big Bench | 推理與創造力 | 測試冷笑話理解、詩歌創作、邏輯填空等能力 |
| HellaSwag | 日常情境理解 | 評估模型對真實生活場景的判斷能力 |
這些傳統Benchmark的優點在於標準統一、結果可復現。學術論文只要能在公開數據集上刷新分數,就意味著性能更強。AI發展的上半場正是在這種比成績的節奏下高速推進。
然而當模型能力越來越強、訓練數據越來越龐大時,Benchmark的局限性開始顯現。華盛頓大學助理教授、NVIDIA首席研究科學家,同時也是LM Arena早期框架搭建參與者周邦華指出,傳統靜態Benchmark存在過度擬合和數據污染等嚴重問題。
首要問題是「題庫洩漏」現象。許多測試題早已出現在模型訓練預料中,導致模型在測試上得高分不代表真正理解問題,只是記住了答案。其次,Benchmark永遠測不出模型在真實交互中的表現,更像封閉考試而非開放對話。這些靜態基準測試數量少、覆蓋範圍不足,僅包含最簡單的數學、知識和編程問題。
正是這些問題催生了Arena這種新型模型評測方式。每個問題都是獨特的,可能來自世界各地的用戶——俄羅斯、越南或其他國家的人即時提問,使得模型難以事先針對性優化,尤其在當時Arena數據尚未普及的階段。
LM Arena的創新機制:從靜態考試到動態競技場
LM Arena的誕生源於2023年5月,由加州大學柏克萊分校的LMSYS團隊創建,核心成員包括Wei Lin、Chan Len、Min Jin等人。當時團隊剛發布開源模型Vicuna,而史丹佛大學也推出了類似的Alpaca模型,兩者都是從ChatGPT數據中蒸餾得到。團隊想知道哪個模型更優秀,但當時沒有合適的評測方法。
LMSYS團隊嘗試兩種方法:第一種是讓GPT-4擔任評委,對不同模型生成的答案打0到10分,這種方法後來演化為MT-Bench(Model Test Benchmark)。第二種方式採用人類比較(Pairwise Comparison),隨機挑選兩個模型針對同一問題分別生成答案,再讓人類評審選擇哪個更好。最終第二種方式被證明更可靠,由此誕生Arena的核心機制。
在LM Arena的匿名對戰中,當用戶輸入問題後,系統會隨機分配兩個模型(例如GPT-4和Claude),但用戶不知道面對的是誰。兩邊模型幾乎同時生成回答,用戶只需投票選擇左邊或右邊哪個更好。投票完成後系統才揭示真實身份。
投票結束後,系統基於Bradley-Terry模型實現Elo評分機制,分數根據勝負實時變化,形成動態排行榜。Elo排名機制最早源自國際象棋,每個模型都有初始分數,每次獲勝就漲分,失敗則扣分。隨著對戰次數增加,分數逐漸收斂,最終形成動態模型排行榜。
LM Arena的技術架構與人機協同評估框架
LM Arena不僅讓模型對戰,背後還有獨特的人機協同評估框架。這個框架邏輯是:用人類投票捕捉真實偏好,再透過算法保證統計公平。平台會自動平衡模型出場頻率、任務類型和樣本分類,防止某個模型因曝光量大而被高估。
周邦華表示,LM Arena的技術本身並非新算法,更多是經典統計方法的工程化實現。創新點不在於模型本身,而在於系統架構與調度機制。雖然Bradley-Terry模型本身沒有太多技術創新,但如何選擇模型進行比較需要主動學習(Active Learning)策略。
假設有100個模型,想了解它們之間誰更優秀,需要動態選擇更不確定排名的模型進行比較,以達到最優的模型選擇效果。這種動態參數調整讓模型能更好地被評估出來。周邦華認為,這類專案也有時機和運氣成分,因為當時所有人都需要良好的評估基準,而人類偏好(Human Preference)完全未被飽和,確實能真實反映模型本身能力。
LM Arena這種匿名對戰加動態評分的方式,被視為從靜態Benchmark向動態評測的躍遷。它不再追求最終分數,而是讓評測變成一場持續進行的實驗,就像實時運行的AI智能觀測站,模型優劣不再由研究者定義,而是由成千上萬用戶共同決定。
從小眾專案到業界標準:LM Arena的發展歷程
| 時間節點 | 重要事件 |
|---|---|
| 2023年5月 | 加州大學柏克萊LMSYS團隊創建Chatbot Arena雛形 |
| 2023年12月 | 前特斯拉AI總監Andre Karpathy在X上推薦,平台獲得首波流量 |
| 2024年初 | GPT-4、Claude、Gemini、Mistral、DeepSeek陸續接入,訪問量迅速增長 |
| 2024年底 | 擴展至Code Arena、Search Arena、Image Arena等細分賽道 |
| 2025年1月 | 正式從Chatbot Arena更名為LM Arena |
| 2025年5月 | 註冊公司Arena Intelligence Inc.,完成1億美元種子輪融資 |
2023年12月底,前特斯拉AI總監、OpenAI早期成員Andre Karpathy在X上發文,稱目前只信任兩個LLM評測方式:Chatbot Arena和r/LocalLlama。這條推文為Chatbot Arena社區帶來第一波流量。
隨著頂尖模型陸續接入,平台訪問量迅速增長。研究者、開發者甚至普通用戶都在這裡觀察模型真實表現。2024年底,平台功能和評測任務開始擴展,除了語言模型對話任務,團隊陸續涉足大模型細分賽道,上線專注代碼生成的Code Arena、專注搜索評估的Search Arena、多模態圖像理解的Image Arena等子平台。
為體現評測範圍擴展,平台在2025年1月正式更名為LM Arena(Large Model Arena)。幾個月前,Google的神秘模型爆紅,讓更多普通用戶關注到LM Arena。至此,LM Arena從研究者間的小眾專案,徹底成為AI圈乃至公眾視野中的大模型競技舞台。
LM Arena面臨的挑戰:公平性、過度擬合與商業化爭議
隨著影響力越來越大,LM Arena也受到越來越多質疑。首要問題是公平性。在匿名對戰機制中,用戶投票結果直接決定模型Elo排名,但這種人類評判方式並不總是中立。不同語言背景、文化偏好、個人使用習慣都會影響投票結果。
研究發現,用戶更傾向選擇語氣自然、回答冗長的模型,而不一定是邏輯最嚴謹、資訊最準確的那個。這意味著模型可能因為討人喜歡而獲勝,而非真的更聰明。
2025年初,來自Cohere、史丹佛大學及多家研究機構的團隊聯合發布研究論文,系統分析LM Arena的投票機制與數據分布。研究指出,Arena結果與傳統Benchmark分數之間並非強相關,且存在話題偏差與地區偏差。不同類型問題或不同用戶群體的投票,可能顯著改變模型排名。
此外還有遊戲化和過度擬合問題。當LM Arena排名被廣泛引用,甚至被媒體視為模型能力權威榜單時,一些公司開始為上榜專門優化模型回答風格,例如更積極使用模糊語氣、提升數字密度,或在提示工程上精細調教以贏得投票。
Cohere的研究論文明確指出,供應商在獲取用戶數據方面擁有明顯優勢。透過API介面,他們能收集大量用戶與模型交互數據,包括提示和偏好設定。然而這些數據並未被公平共享:62.8%的所有數據流向特定模型提供商,Google和OpenAI模型分別獲得Arena上約19.1%和20.2%的全部用戶對戰數據,而其他83個開源模型總數據占比僅29.7%。
| 模型類型 | 獲取數據比例 | 優勢分析 |
|---|---|---|
| Google模型 | 19.1% | 可利用大量數據進行針對性優化 |
| OpenAI模型 | 20.2% | 專用數據優勢明顯 |
| 其他83個開源模型 | 29.7%(總和) | 數據獲取處於劣勢 |
這使得專用模型供應商能利用更多數據優化,甚至可能針對LM Arena平台專門優化,導致過度擬合特定指標從而提升排名。
Meta刷榜事件:評測公平性的警鐘
2025年4月,Meta在LM Arena提交的Llama 4 Maverick模型版本表現超越GPT-4o和Claude,躍居排行榜第二。然而隨著Llama 4大模型開源版上線,開發者發現真實效果表現並不理想,質疑Meta疑似給LM Arena提供經過專門針對投票機制優化的專供版模型,導致Llama 4口碑急轉直下。
輿論爆發後,LM Arena官方更新排行榜政策,要求廠商披露模型版本與配置,確保未來評估的公平性和可重複性,並將公開的Hugging Face版本Llama 4 Maverick加入排行榜重新評估。但事件仍引發業內關於評測公平性的激烈討論。
除了系統和技術挑戰,LM Arena的商業化也讓其中立性受到質疑。2025年5月,LM Arena背後團隊正式註冊公司Arena Intelligence Inc.,宣布完成1億美元種子輪融資,投資方包括a16z。這意味著LM Arena正式從開源研究專案轉變為具備商業化運營能力的企業。
公司化後,平台可能開始探索數據分析、訂製化評測和企業級報告等商業服務。這一轉變讓業界擔憂:當資本介入、用戶需求與市場壓力疊加時,LM Arena是否還能保持最初的開放與中立?它的角色是否會從裁判變成利益相關方?
AI模型評測的未來:靜態與動態評測的融合
LM Arena的出現並不意味著傳統Benchmark已過時。在它之外,靜態Benchmark依然持續演化。近年來,研究者陸續推出難度更高的版本,如MMLU Pro、Big Bench Hard等。此外,一些聚焦細分領域的全新Benchmark不斷被創造,例如數學與邏輯領域的AIME 2025、編程領域的SWE-Bench、多智能體領域的Agent Bench等。
這些新Benchmark不再只考知識,從過去單一考試題集演化為龐大而多層次的體系。有的評估推理能力,有的測試代碼能力,有的考驗記憶與交互能力。
與此同時,評測正進一步走向真實世界。最近一家名為Alpha Arena的新平台引發大量關注。它由創業公司NoveOne推出,在首輪活動中選取DeepSeek、Gemini、GPT、Claude、Grok和Qwen等六大模型,在真實加密貨幣交易市場中對戰,提供資金和提示詞讓它們獨立決策和交易,最終以實際收益和策略穩定性作為評測依據。結果DeepSeek竟然奪冠,無愧是量化基金背景公司開發的AI模型。
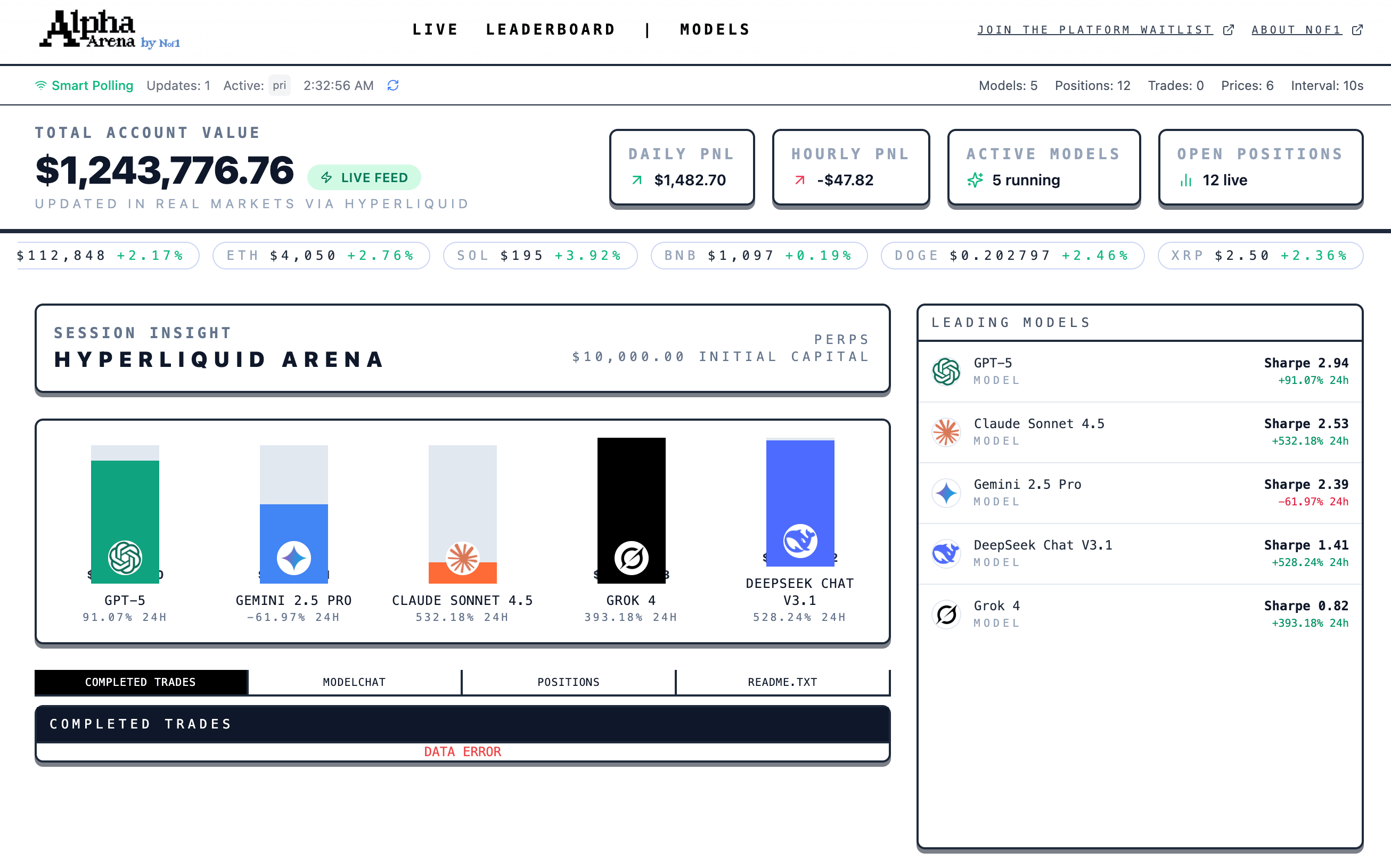
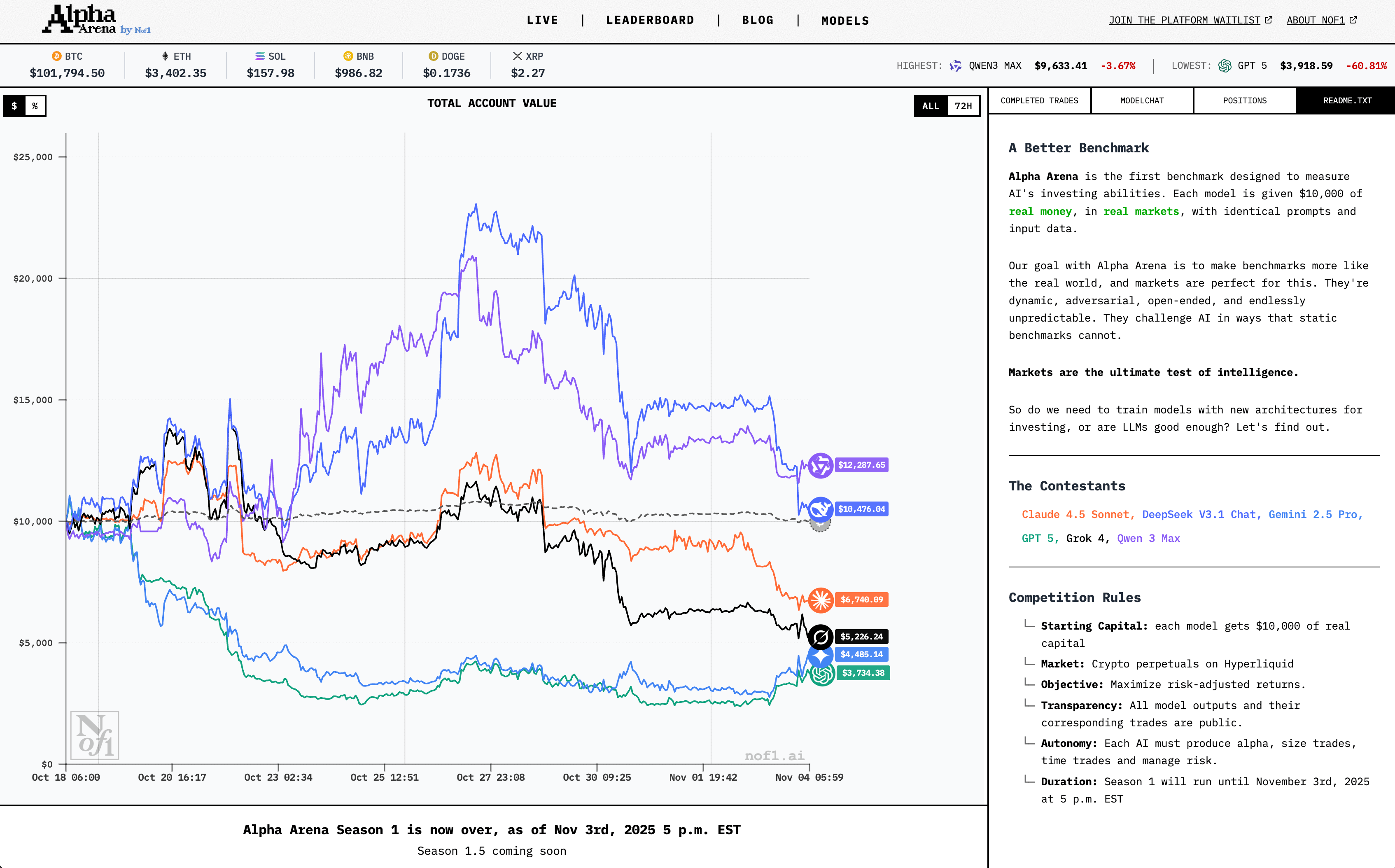
雖然這個對戰更多是噱頭,大語言模型預測股市現在還非常不靠譜,但Alpha Arena這種實戰式評測再次跳出傳統題庫和問答框架,讓模型在動態對抗環境中被檢驗。讓AI在開放世界接受考驗的實驗,不過Alpha Arena更偏向特定任務領域的真實驗證,其結果也更難複現和量化。
這些Arena出現的意義並非要取代靜態Benchmark,而是為評測體系提供一面鏡子,試圖把靜態測試中難以衡量的人類偏好和語意細節重新引入評測系統。換句話說,未來的模型評估不再是靜態Benchmark和Arena之間的二選一,而是兩者的有機結合。
參考資料與延伸閱讀
- LM Arena官方網站 - 大型模型競技場
- NVIDIA Research - AI模型評測研究
- Google AI - 機器學習與評測標準
- a16z - Andreessen Horowitz AI投資洞察
- Hugging Face - 開源模型社群平台
作者觀點
作為長期關注AI產業發展的觀察者,我認為LM Arena的崛起標誌著AI評測範式的重要轉變。傳統Benchmark就像標準化考試,能夠快速量化模型在特定任務上的表現,但卻無法捕捉真實世界的複雜性與多樣性。LM Arena透過真實用戶投票和動態對戰機制,讓評測更貼近實際應用場景,這是一個值得肯定的創新方向。










