

DeepSeek:AI界的東方神秘力量崛起 ,挑戰傳統AI巨頭。本文解析DeepSeek的技術優勢與發展潛力。
DeepSeek:AI界的「東方神秘力量」崛起
在人工智能快速發展的時代,一個新的重量級選手悄然崛起。DeepSeek,這個由中國 Deepseek ( 杭州深度求索人工智能基础技术研究有限公司) 開發,幻方量化基金孵化的大型語言模型,正在以驚人的性價比挑戰行業巨頭。作為幻方量化旗下的產品,DeepSeek的出現不僅震撼了AI圈,更為整個產業帶來新的思考。
關於幻方
DeepSeek的故事要從幻方說起。在量化投資領域,幻方是一個特立獨行的存在 —— 這是一家完全由本土班底起家的量化基金,在2021年就達到了千億規模。
「我們做大模型,其實跟量化和金融都沒有直接關係,」創辦人梁文鋒解釋道,「當時我們嘗試了很多場景,最終切入了足夠複雜的金融,而通用人工智能可能是下一個最難的事之一,所以對我們來說,這是一個怎麼做的問題,而不是為什麼做的問題。」
堅守技術研究:為什麼不做產品?
在中國7家大模型創業公司中,DeepSeek是唯一一家至今堅持不做toC應用的公司。這個選擇讓許多人感到不解,畢竟在當前階段,快速商業化似乎是一個更務實的選擇。
DeepSeek的卓越表現
最新發布的DeepSeek 3.0版本展現出令人矚目的實力。在與OpenAI的ChatGPT、Anthropic的Claude以及Meta的Llama等頂級模型的對比中,DeepSeek表現出色。特別是在數學運算和程式設計領域,DeepSeek更是展現出領先優勢:
- 在MMLU-Pro、GPQA-Diamond等知識理解測試中名列前茅
- 於MATH 500、AIME 2024等數學推理測試中大幅領先
- 在Codeforces和SWE-bench Verified等程式編寫測試中表現優異
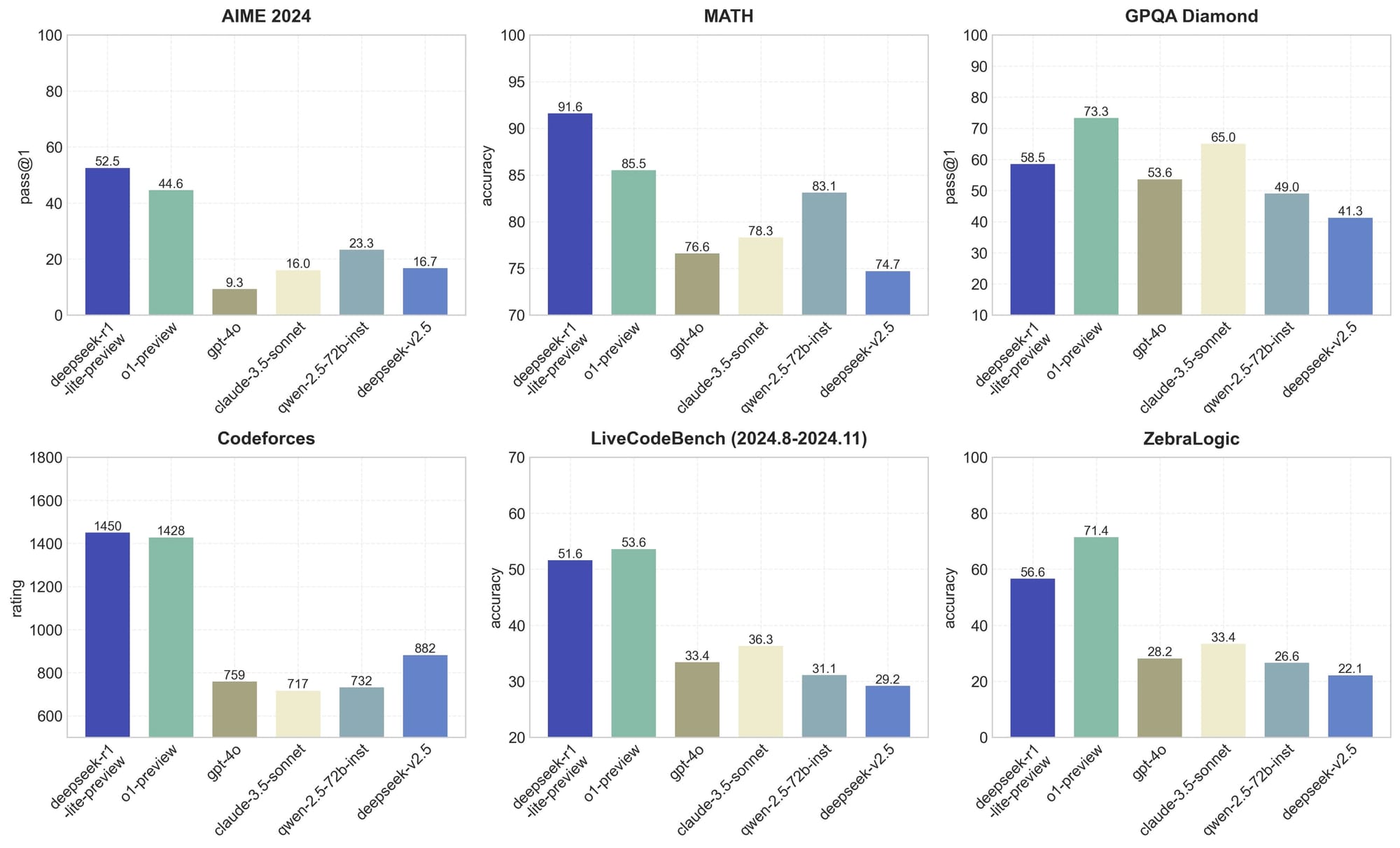
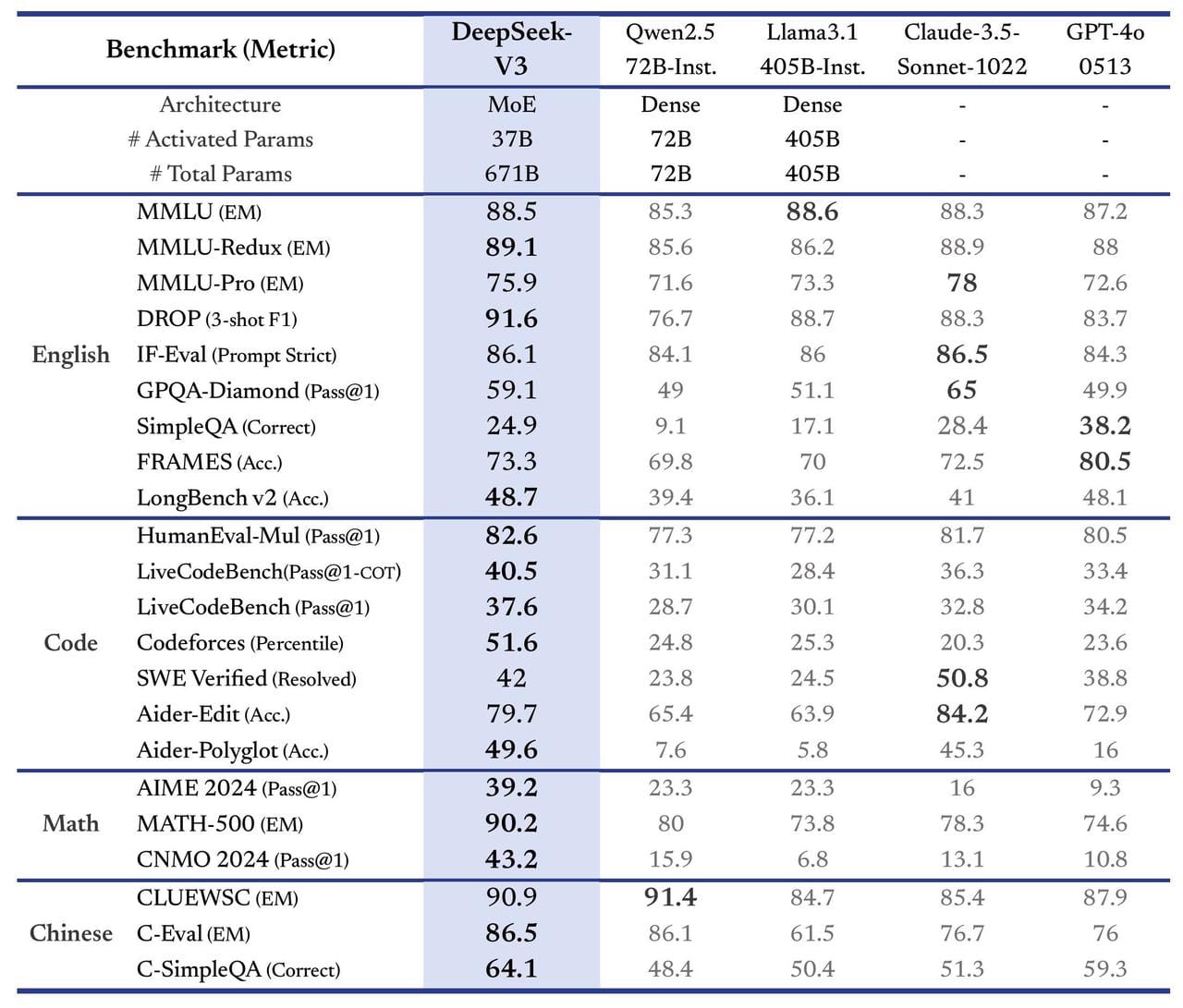
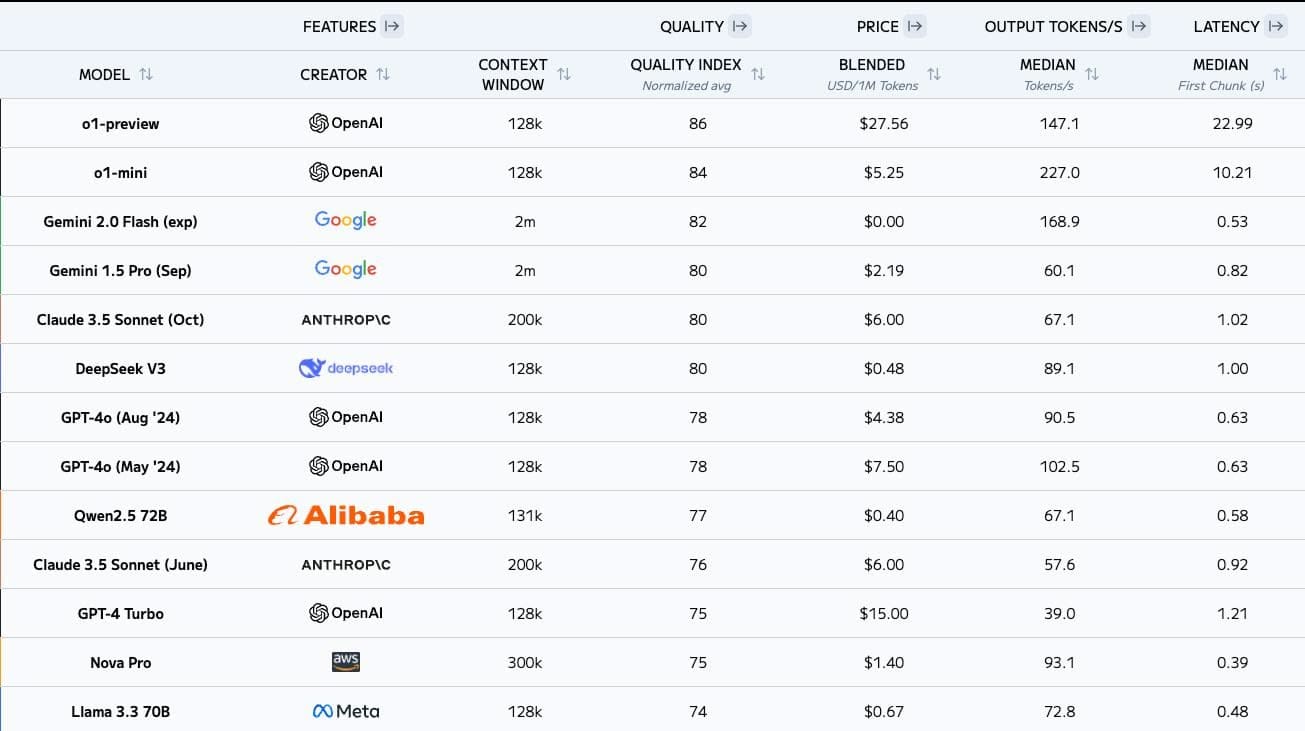
DeepSeek 的卓越能力:與 ChatGPT 等模型的比較
首先,讓我們看看 DeepSeek 在能力方面取得了哪些成就。下圖展示了六個大型語言模型在多個指標上的比較:DeepSeek 最新發布的 V3 版本及其 2.5 版本、阿里巴巴的千問、Meta 的 Llama 3.1-405B、OpenAI 的 GPT-4o 以及 Claude 3.5。
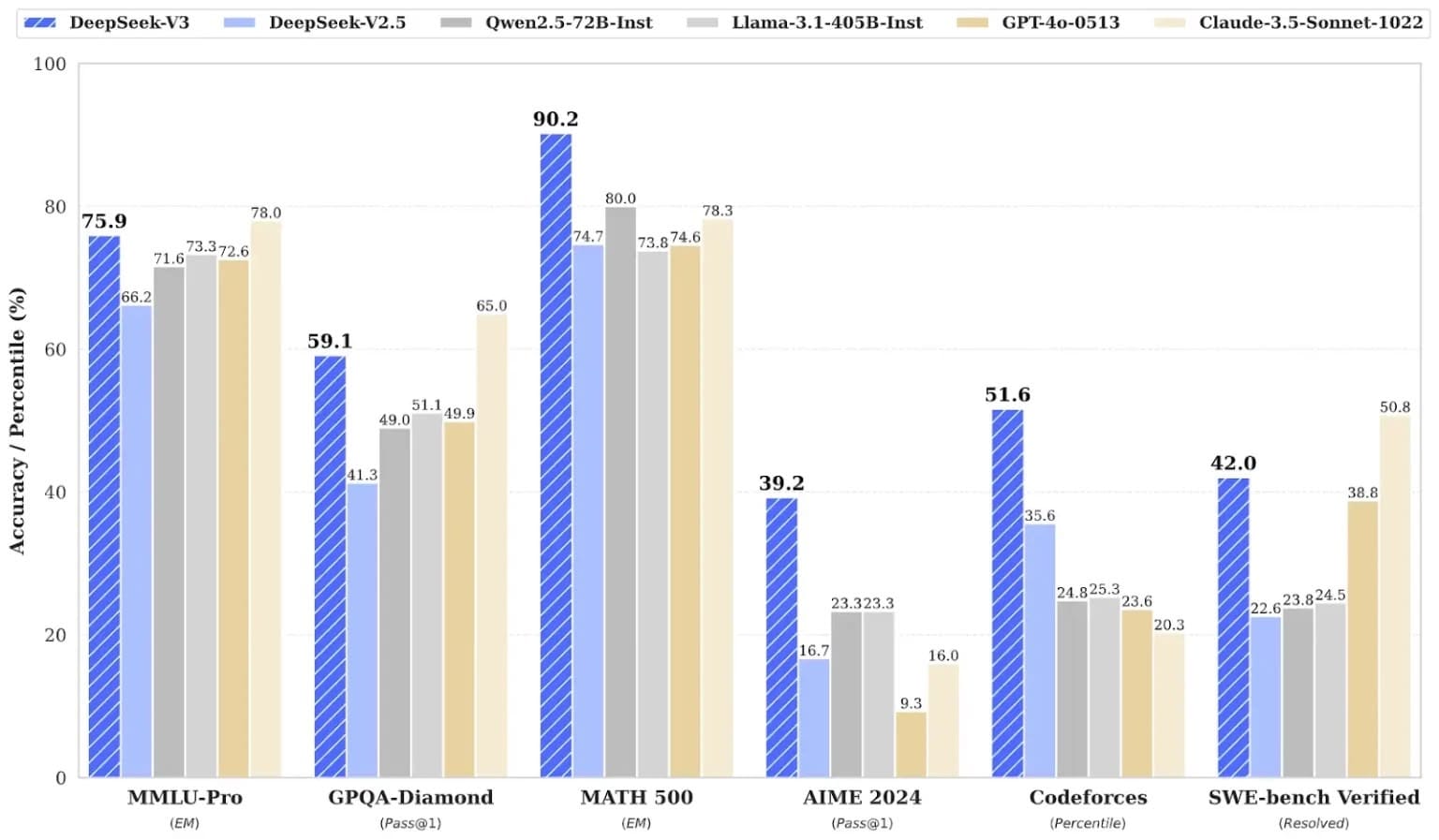
從圖表中可以明顯看出,DeepSeek(最左側的藍色柱狀)在各項任務中的表現都相當出色。尤其在 MATH 500、AIME 2024 和 Codeforces 這三項測試中,DeepSeek 的表現更是名列前茅。MATH 500 測試的是模型解決 500 道數學題目的能力,評估其數學推理能力;AIME 2024 則是美國的一項數學競賽,同樣著重於評估數學推理能力;而 Codeforces 則是用來評估模型的程式設計能力。
由此可見,DeepSeek 在數學計算和程式設計方面的能力超越了其他模型。此外,在多任務理解和複雜問題處理這兩項測試中,DeepSeek 的表現也相當亮眼,僅次於 Claude,位居第二。
儘管 DeepSeek 在各方面都取得了不錯的成績,但真正令人驚豔的是其極短的訓練時間和極低的訓練成本。訓練 DeepSeek V3 版本僅使用了 2,048 張 GPU,耗時兩個月,換算下來約為 278 萬個 GPU 小時。相較之下,訓練 Meta 的 LLAMA 3.1 模型則耗費了 3,080 萬個 GPU 小時,訓練成本高出一個數量級。
更值得一提的是,由於中國面臨美國的晶片管制,DeepSeek 只能使用 H800 晶片進行訓練,而 Llama 3.1 使用的則是更先進的 H100 晶片。這意味著,DeepSeek V3 使用了相對落後的晶片,僅用了十分之一的訓練時間,就訓練出了表現卓越的模型。
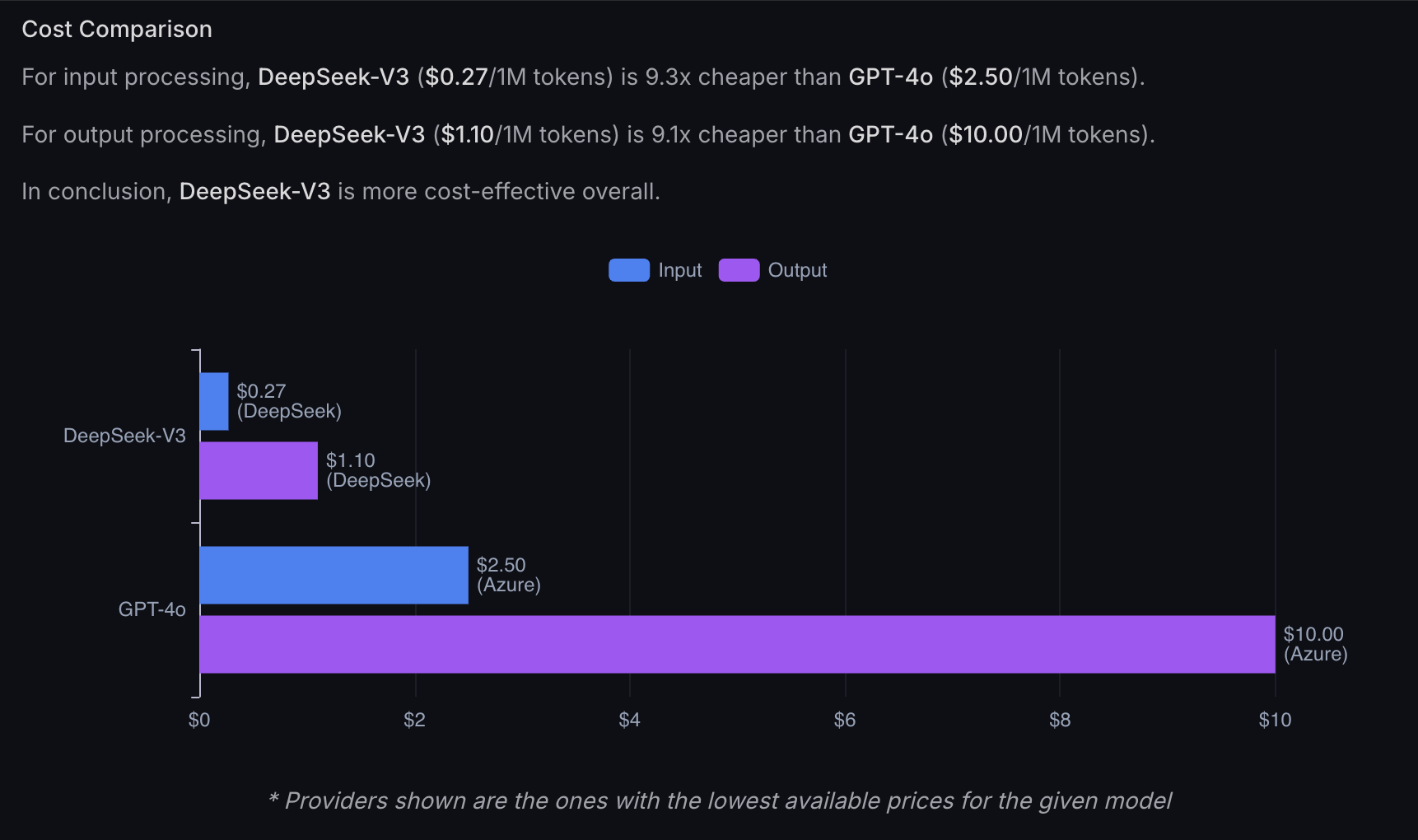
從整體成本來看,訓練 DeepSeek 總共花費了 557 萬美元,而訓練 OpenAI GPT-4o、Meta 的 LLAMA3 和 Claude 等大型模型的成本都在數億美元的級別。因此,若以訓練成本而言,DeepSeek 的訓練成本僅為其他同級模型的 1%,但其效果卻能與之媲美。
此外,DeepSeek 還是一個開源模型。所謂開源模型,指的是其程式碼和訓練方式都是公開的,任何人都可以存取和使用。相較之下,GPT-4o 和 Claude 屬於閉源模型,其程式碼和訓練方法不對外公開。開源模型對於使用者而言,最大的好處是可以免費使用相關技術,並能根據自身需求進一步優化程式碼。同時,對於 DeepSeek 而言,由於其程式碼公開透明,大眾對其工作原理的信任度也可能更高。
創新架構設計
MLA 機制
DeepSeek V3採用創新的MLA架構,具備以下特點:
- KV壓縮維度設定為512
- Query壓縮維度達1536
- 解耦Key的頭維度為64
這種設計顯著降低了記憶體佔用,同時保持了模型的高性能表現。
DeepSeekMoE專家系統
創新的混合專家系統包含:
- 1個共享專家與256個路由專家
- 每個Token可選擇8個路由專家
- 最多可路由至4個節點
動態負載平衡
採用創新的偏置項調整策略:
- 訓練前期偏置更新速率為0.001
- 後期500B個Token中調整為0.0
- 序列級平衡損失因子維持在0.0001
工程優化創新
DualPipe雙向流水線
- 實現雙向微批次處理
- 顯著減少流水線氣泡
- 提升GPU使用效率
通訊優化策略
DeepSeek V3實現了多項突破:
- 節點限制路由技術
- 客製化All-to-All通訊核心
- Warp專業化處理機制
訓練策略與資料處理
預訓練創新
- 總訓練數據量達14.8萬億Token
- 提升數學與程式相關數據比例
- 採用Document Packing技術
- 實施Fill-in-Middle代碼訓練策略
分詞器優化
- 採用字節級BPE技術
- 建立128K詞表
- 引入標點符號組合機制
模型配置
- 61層Transformer架構
- 7168維隱藏層
- 128個注意力頭
- 每個注意力頭維度為128
後訓練優化
監督式微調(SFT)
- 使用150萬條高質量指令響應對
- 涵蓋多樣化任務領域
- 採用DeepSeek-R1生成推理數據
強化學習(RL)創新
- 結合規則型與模型型獎勵機制
- 採用GRPO(組相對策略優化)算法
- 實現更優質的人類偏好對齊
突破性的成本效益
DeepSeek最令業界震驚的是其極具競爭力的開發成本。僅需557萬美元的訓練成本,就達到了其他動輒數億美元大模型的效果。具體來說:
- 使用2,048個GPU進行為期兩個月的訓練
- 總計僅耗時278萬GPU小時,相較於Llama 3.1的3,080萬GPU小時大幅節省
- 即使使用較為基礎的H800晶片,仍達到出色效果
開源優勢
DeepSeek採用開源模式,這意味著:
- 程式碼和訓練方法完全公開透明
- 使用者可以免費使用並根據需求優化
- 提高了模型的可信度和透明度
現存挑戰
儘管表現亮眼,DeepSeek仍面臨一些待改進的領域:
- 首次回應時間約為1.1秒,略慢於競爭對手的1秒以內
- 每秒生成87.5個Token,低於GPT-4和Claude的90-100個Token
- 上下文理解限制在13萬個Token,遠不及其他模型的200萬個Token
商業模式衝擊
- API調用費用僅為競爭對手的十分之一,甚至百分之一
- 每百萬Token的輸入成本僅0.1-1元人民幣
- 輸出成本維持在2元人民幣,遠低於GPT-4的15美元標準
技術發展啟示
- 證明較基礎的硬體配置也能實現優秀效果
- 可能影響高端AI晶片的定價策略
- 為企業提供更多元的AI應用選擇
了解更多關於 Deepseek
結論: 那麼,我們從 DeepSeek v3 中學到了什麼?
我們應該更新的概念是除了 OpenAI 的 ChatGPT, Anthropic 的 Claude, Meta 的Llama, Google 的 Gemini 之外,來自中國的 AI 新創 DeepSeek 也展現出了強大的潛力,接近 Clause Sonnet 3.5 與 ChatGPT 4o 的水準,解決困難問題並最佳化成本的 AI 大語言模型。
對於專家模型和所採用的其他技術的組合來說,這是一個令人印象深刻的表現。就訓練成本和主動推理標記而言,相對較小的模型的產出質量以比我們想像的做得更好。
很明顯,缺乏運算能力是 DeekSeek 的重要限制。他們不得不使用數量有限的 NVIDIA H800 (Nvidia H800是專門為中國、香港和澳門市場設計的版本)。是的,這意味著他們在美國對中國的 GPU 出口管制下竟然還能夠解決優化和效率方面比其他新創都做得更好,
如果你只花 550 萬美元就能得到的這樣的結果,不僅展示了中國AI技術的進步,更為全球AI行業帶來新的可能性。透過降低開發成本、提供開源方案,DeepSeek正在重新定義AI的發展方向。儘管仍有改進空間,其創新無疑為AI技術的普及化邁出了重要一步。然而,其上下文記憶限制與生成速度仍是未來需要優化的領域。如果能克服這些短板,DeepSeek將進一步提升市場競爭力,並有可能重塑AI行業格局。
DeepSeek的故事還在繼續,我們將持續關注這款突破性模型的發展與影響。如果您有更多問題,歡迎在我們的 Threads 下方留言!
FAQ
- Q: DeepSeek 是什麼樣的 AI 模型?
- A: DeepSeek 是由中國杭州深度求索人工智能基础技术研究有限公司開發的大型語言模型,以其高性價比和優異的數學運算、程式設計能力聞名。
- Q: DeepSeek 的主要技術優勢是什麼?
- A: DeepSeek 採用創新的多頭潛在注意力(MLA)架構,具備高效的記憶體使用率,並運用 DualPipe 雙向流水線技術提升 GPU 使用效率。
- Q: DeepSeek 的訓練成本是多少?
- A: DeepSeek 的訓練成本僅需 557 萬美元,使用 2,048 個 GPU 進行為期兩個月的訓練,總計耗時 278 萬 GPU 小時。
- Q: DeepSeek 的使用成本如何?
- A: DeepSeek 的 API 調用費用極具競爭力,每百萬 Token 的輸入成本僅 0.1-1 元人民幣,輸出成本維持在 2 元人民幣,遠低於競爭對手。
- Q: DeepSeek 目前有什麼限制?
- A: DeepSeek 的首次回應時間約為 1.1 秒,每秒生成 87.5 個 Token,上下文理解限制在 13 萬個 Token,這些指標相較其他頂級模型仍有改進空間。







