
2026 年 2 月 11 日,智譜 AI(Z.ai)正式發布第五代大型語言模型 GLM-5。這家從清華大學分拆出來的北京新創公司,在農曆新年前交出了一份技術規格頗具野心的成績單:744 億總參數的 MoE 架構、完全基於華為昇騰晶片的訓練流程,以及 MIT 授權的開源策略。GLM-5 的發布時機與定位,讓它同時承載了技術突破與地緣政治宣示的雙重意涵。
本文將從架構設計、效能基準、半導體自主化、商業定位四個維度,拆解 GLM-5 對開發者與企業決策者的實際意義。
GLM-5 的技術架構:MoE 規模翻倍
GLM-5 採用 Mixture of Experts(MoE)架構,總參數量從前代 GLM-4.5 的 355B 躍升至 744B,其中每次推論僅啟用約 40B 的活躍參數。模型內含 256 個專家網路,每個 token 路由至 8 個專家,稀疏率約為 5.9%。
訓練資料規模同步擴張。GLM-5 使用了 28.5 兆(trillion)token 進行預訓練,較 GLM-4.5 的 23 兆有明顯增幅。上下文窗口支援 200K token,最大輸出長度達 131K token,後者在當前主流模型中屬於頂段。
架構層面的另一項特點是整合了 DeepSeek 首創的 Dynamically Sparse Attention(DSA)機制。DSA 允許模型在處理長上下文時,以動態稀疏注意力取代傳統的密集注意力運算,藉此在不犧牲品質的前提下降低計算開銷。
| 規格項目 | GLM-4.5 | GLM-4.7 | GLM-5 |
|---|---|---|---|
| 總參數量 | 355B | 368B | 744B |
| 活躍參數量 | 32B | 約 32B | 40B |
| 訓練資料量 | 23T tokens | — | 28.5T tokens |
| 上下文窗口 | 128K | 200K | 200K |
| 最大輸出長度 | — | — | 131K |
| 授權方式 | MIT | MIT | MIT |
後訓練階段,智譜 AI 開發了名為「Slime」的非同步強化學習基礎設施,用以提升 RL 訓練的吞吐量與效率。根據 Hugging Face 上的技術說明,Slime 解決的是大規模 LLM 強化學習部署中常見的訓練效率瓶頸,使團隊能進行更細粒度的後訓練迭代。
效能基準:接近 Claude Opus 4.5,領先開源陣營
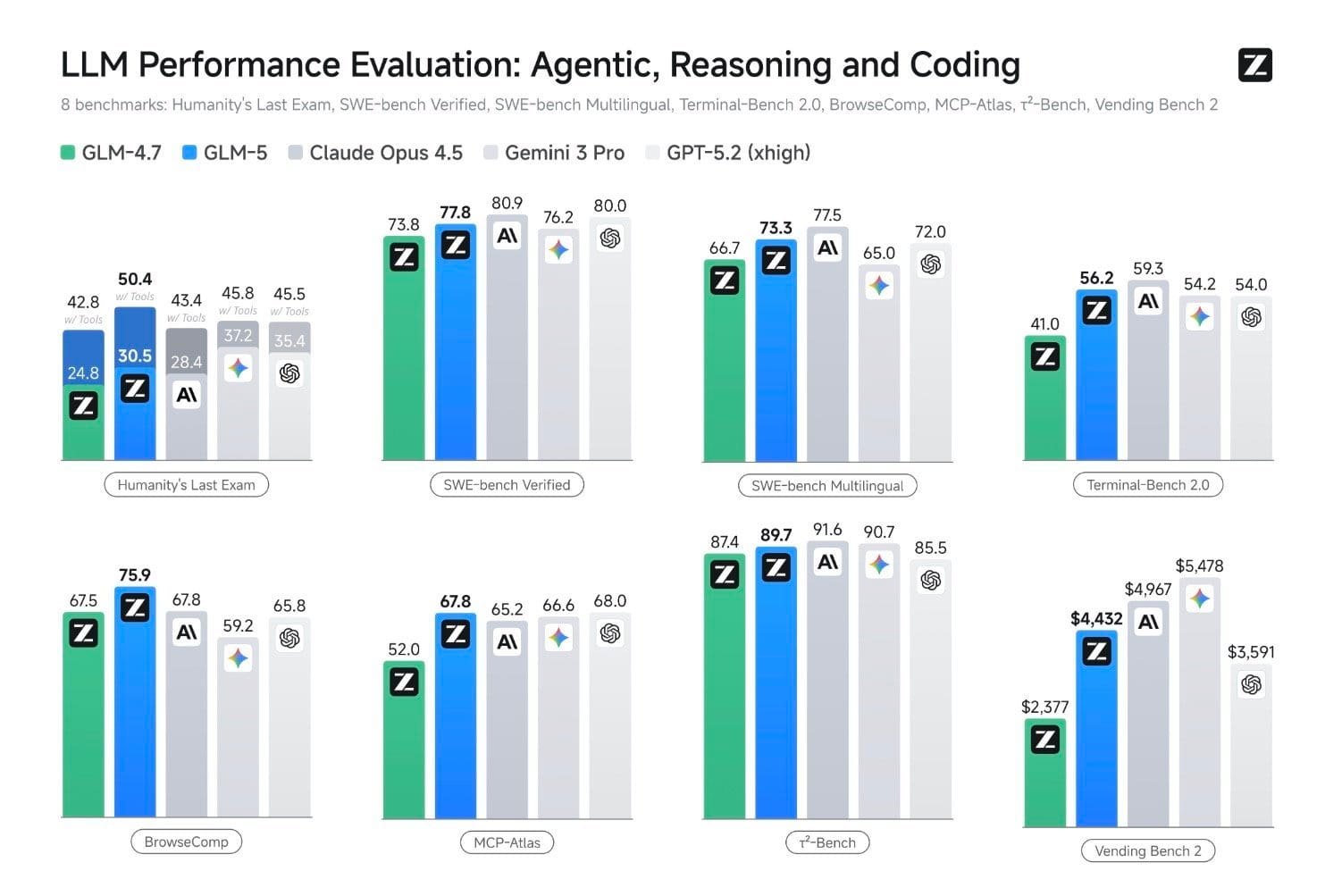
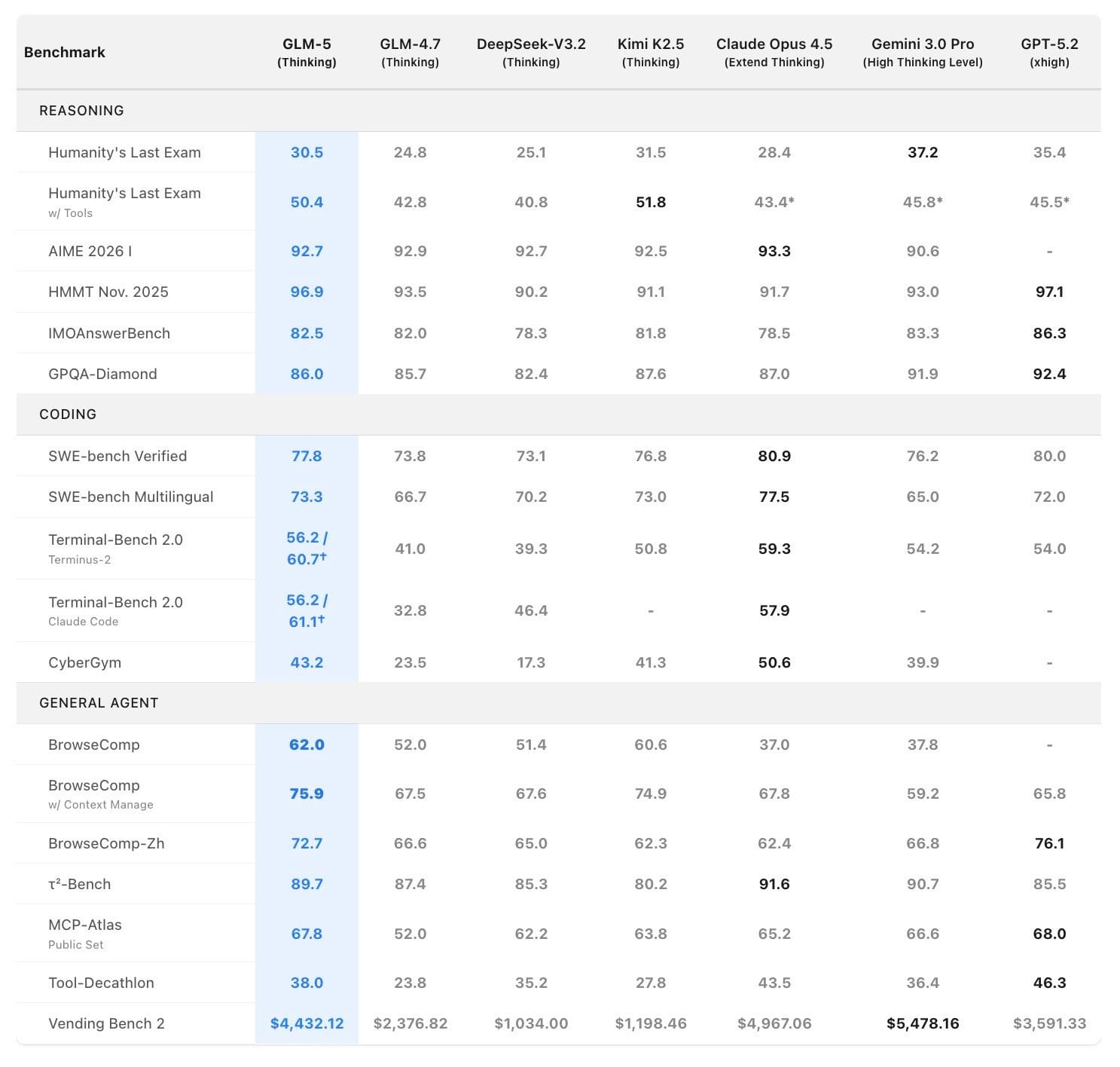
智譜 AI 公布的基準測試結果顯示,GLM-5 在多項評估中位居開源模型首位,並在部分指標上接近 Anthropic 的 Claude Opus 4.5 等閉源前沿模型。
| 基準測試 | GLM-5 | Claude Opus 4.5 | 說明 |
|---|---|---|---|
| SWE-bench Verified | 77.8% | 80.9% | 軟體工程任務解決率 |
| BrowseComp | 75.9(所有模型最高) | — | 網頁瀏覽代理能力 |
| τ²-Bench | 89.7 | — | 互動式工具呼叫 |
| HLE(含工具) | 50.4 | — | Humanity's Last Exam |
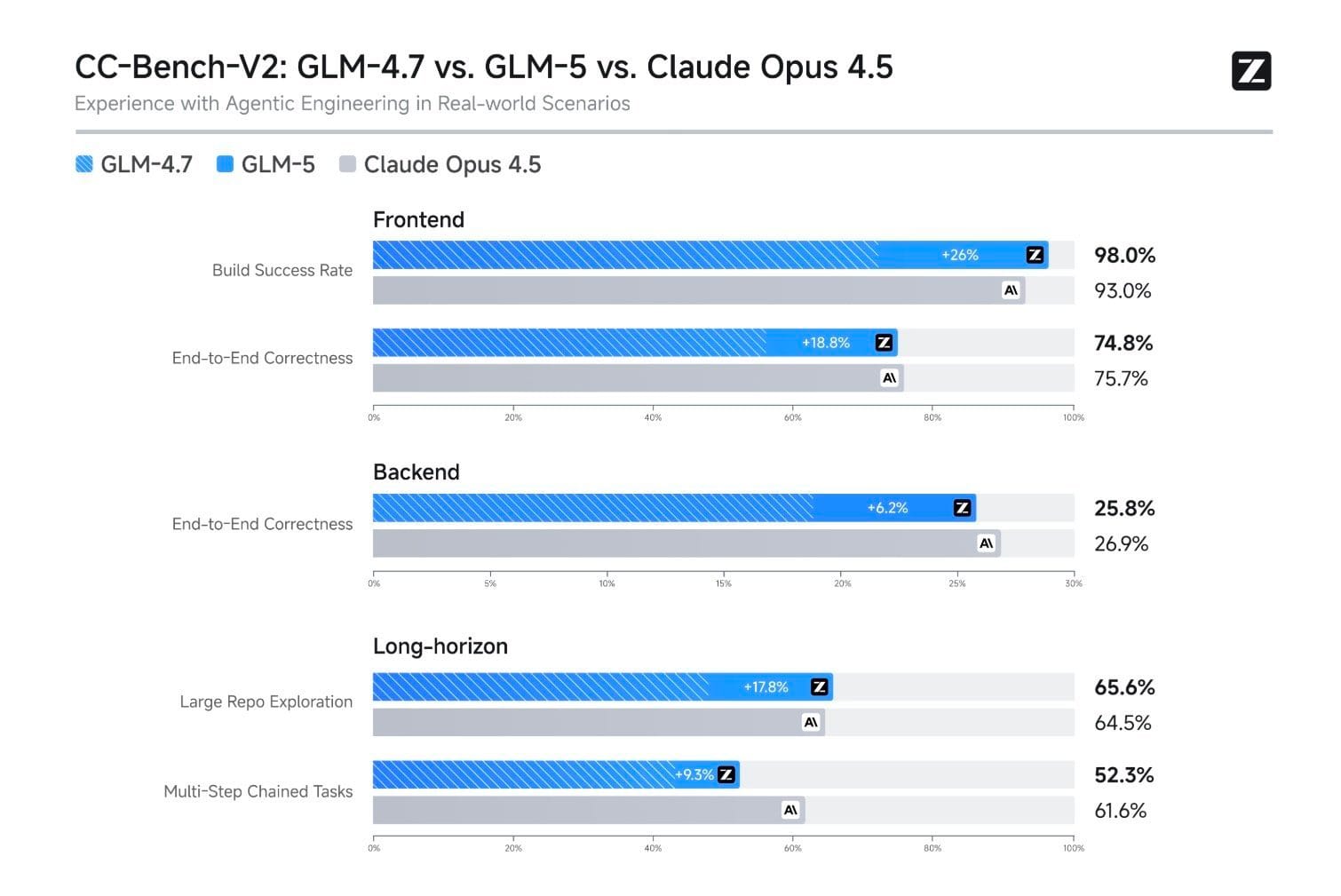
| CC-Bench-V2 前端建構成功率 | 98% | — | 前端生成品質 |
值得注意的是,GLM-5 與 Claude Opus 4.5 在 SWE-bench Verified 上的差距已縮小至 3.1 個百分點。路透社的報導也確認,GLM-5 在部分基準上超越了 Gemini 3 Pro。智譜 AI 自身也坦承,在編碼基準的全面表現上,GLM-5 仍落後於 Claude 系列。
從 Vibe Coding 到 Agentic Engineering 的定位轉變,是 GLM-5 行銷敘事的核心。智譜 AI 強調 GLM-5 的重點已從單點程式碼生成,轉向系統工程層面的多步驟任務執行。這在 CC-Bench-V2 的 98% 前端建構成功率上有所體現——相較 GLM-4.7 提升了 26 個百分點。
GLM-5 也針對 AI Agent 場景進行了優化,支援與 OpenClaw 等代理框架的整合,並推出了 Agent Mode(Beta),能自動拆解任務、調度工具並執行工作流。
華為昇騰晶片:半導體自主化的里程碑
GLM-5 的戰略意義,有一半來自它的訓練硬體選擇。智譜 AI 明確表示,GLM-5 的完整訓練流程——從資料預處理到大規模訓練——全部在華為昇騰(Ascend)晶片上完成,使用的是 Ascend Atlas 800T A2 伺服器搭配 MindSpore 框架,完全未依賴美國製造的半導體硬體。
這項宣示的背景是:智譜 AI 已被美國商務部列入實體清單,實質上切斷了該公司取得 NVIDIA H100 和 A100 GPU 的管道。在此限制下,智譜 AI 轉向與華為合作,先前已在 GLM-Image 模型上驗證了昇騰晶片的可行性,GLM-5 則是將此路線推進到前沿語言模型的規格。
根據產業分析,華為昇騰 910C 晶片的單顆訓練效能約為 NVIDIA H100 的 60% 至 80%。智譜 AI 團隊透過多項工程優化來彌補效能差距,包括動態圖多級流水線部署、針對昇騰架構的高效能融合算子,以及多流並行技術以重疊通訊與計算操作。

除華為外,GLM-5 的推論端也支援其他中國國產晶片商的產品,包括摩爾執行緒(Moore Threads)、寒武紀(Cambricon)和崑崙芯(Kunlunxin),進一步強化了中國 AI 產業「全棧國產化」的敘事。
對台灣半導體產業而言,這是一個值得密切觀察的發展方向。昇騰晶片尚未達到與 NVIDIA 最新 Blackwell 系列的效能對等,但其透過叢集化策略(華為 CloudMatrix 384 系統可將近 400 顆昇騰晶片組成單一邏輯單元,提供約 300 PetaFLOPS 的算力)來彌補單晶片差距的做法,展示了一條不同於西方硬體路線的可行路徑。
商業定位:開源、低成本、港股上市
GLM-5 的商業策略建立在三個支柱上:
第一,開源開放。GLM-5 的模型權重已在 Hugging Face 上以 MIT 授權發布,允許自由商業使用、微調與社群驅動的研究。這延續了 GLM 系列一貫的開源傳統,也使 GLM-5 成為目前參數量最大的 MIT 授權開源模型之一。
第二,價格競爭力。雖然智譜 AI 尚未公布 GLM-5 的正式 API 定價,但 GLM 系列向來以成本效益見長。GLM-5 目前可透過 Z.ai 平台和 OpenRouter(先前以「Pony Alpha」名稱匿名上線進行測試)存取。在農曆新年前的中國 AI 競賽中,低價策略是各家廠商的共同選擇。
第三,資本市場背書。智譜 AI 於 2026 年 1 月 8 日在香港交易所上市,募資約 43.5 億港元(約 5.58 億美元,折合約 NTD 18,000,000,000),成為全球首家上市的基礎模型公司。上市以來股價已上漲超過 80%。Bloomberg 的報導指出,GLM-5 的發布是在 DeepSeek 預期推出新產品之前搶先亮相。
模型家族與生態系
GLM-5 並非單一模型,而是一個模型家族的核心。除語言模型外,智譜 AI 同步推出了相關變體:
GLM-Image 採用混合「自迴歸 + 擴散解碼器」架構進行高品質圖像生成,API 每張圖片定價 0.1 人民幣(約 NTD 0.5)。GLM-4.6V 和 GLM-4.5V 則專注於視覺語言多模態推理,在 MMMU 和 MathVista 等基準上表現突出。
在開發者工具整合方面,GLM-5 支援透過 vLLM 和 SGLang 進行本地部署,並相容於 Claude Code、Roo Code、Cline 和 Kilo Code 等主流 AI 編碼框架。對使用這些工具的開發者而言,GLM-5 提供了一個成本更低的模型選項,尤其適合需要持續運行代理任務的場景。
實際使用觀察與限制
早期使用者的回饋提供了一些基準數據之外的參考。WaveSpeed 的測試報告指出,GLM-5 在短提示的首 token 延遲一般低於 1 秒,複雜的多部分指令則約 1-2 秒。持續生成的吞吐量在 30-60 tokens/秒的範圍。
已知的限制方面,GLM-5 的吞吐量(17-19 tok/s)在部分測試中低於競爭對手的 25-30+ tok/s。英文效能基準仍在建立中,這對需要英文優先的國際用戶可能是考量因素。此外,作為中國公司產品,GLM-5 在中國境外的存取延遲和可用性可能因提供商而異。
對企業與開發者的實務建議
GLM-5 的定位使其特別適合三類使用情境。成本敏感的 AI 應用——如果企業的 AI Agent 工作流需要大量 API 呼叫,GLM-5 的開源授權加上較低的定價,可能比 GPT-5.2 或 Claude Opus 4.5 節省可觀費用。需要自行託管的場景——對資料安全有嚴格要求、不願使用第三方 API 的組織,可下載 MIT 授權的權重進行獨立部署和微調。中文優先的應用——GLM 系列在中文理解與生成上有歷史優勢,對面向中文市場的產品具備天然適配性。
對已在使用 Claude Code 或 Cursor 等工具的開發者來說,GLM-5 可作為模型路由中的備選項。透過 Claude Code Router 等工具,將低複雜度任務路由至 GLM-5、高複雜度任務保留給 Claude Opus 4.5,是一種兼顧成本與品質的實務策略。
引用來源
- Hugging Face - GLM-5 模型頁面
- Reuters - Chinese AI startup Zhipu releases new flagship model GLM-5
- Bloomberg - China's Zhipu Unveils New AI Model, Jolting Race With DeepSeek
- South China Morning Post - China's Zhipu AI launches new major model GLM-5
- Stanford HAI - AI Index Report
- SWE-bench 官方排行榜
本文由 Tenten AI Research 團隊撰寫。
作者觀點: GLM-5 的發布標誌著開源前沿模型的門檻正在降低,但「開源」與「好用」之間仍有距離。對多數企業而言,模型選擇的決定性因素從未是參數量或基準分數,而是在特定任務上的穩定性、生態系成熟度,以及持續迭代的速度。智譜 AI 在一個月內連續發布 GLM-4.7 和 GLM-5,展示了高速迭代的能力。接下來的觀察重點,是 GLM-5 在實際生產環境中的可靠度,能否匹配其基準數據所呈現的潛力。
若您正在評估企業 AI 模型選型策略,或規劃 AI Agent 工作流的架構設計,歡迎與 Tenten 團隊預約諮詢,探討最適合您組織需求的技術方案。










