
GPT-Image-2 於 2026 年 4 月 21 日正式推出,文字渲染準確率達 99%,生成速度是前代 GPT-Image-1.5 的兩倍,最高支援 2K 標準輸出(API beta 版支援 4K)。對於長期受困於 AI 圖像「中文字亂碼」問題的設計師和行銷人員而言,這次升級不是迭代,是一條分水嶺。
從 iOS UI 草稿到工程三視圖,從菜市場帳本到蘇州園林門票,本文根據真實使用場景對 GPT-Image-2 進行系統性評測,並對其在 2026 年當前 AI 圖像競爭格局中的定位給出獨立判斷。
技術規格速覽
GPT-Image-2(官方模型 ID:gpt-image-2,快照版本 gpt-image-2-2026-04-21)是 OpenAI 自 2025 年 3 月推出 GPT-Image-1 以來最大幅度的架構重建。研究主責 Boyuan Chen 在發布說明中明確指出,這不是在 GPT-4o 的影像管線上疊加改進,而是從零搭建的獨立架構——他稱之為「generalist model for images」,類比文字領域的 GPT。
| 項目 | GPT-Image-1.5(前代) | GPT-Image-2(現行) |
|---|---|---|
| 發布日期 | 2025 年 12 月 16 日 | 2026 年 4 月 21 日 |
| 文字渲染準確率 | 約 90–95% | 約 99%(官方數據) |
| 最大解析度 | 1024×1024 | 2K 標準;4K API beta |
| 生成速度 | 基準 | 約 2 倍提升 |
| 長寬比支援 | 1:1、3:2、2:3 | 最高 3:1 至 1:3,含 16:9 和 9:16 |
| 知識截止日期 | 不明 | 2025 年 12 月 |
| Thinking 模式 | 不支援 | 支援(可搜尋網路、單次 prompt 最多 8 張) |
| API 定價 | — | 輸入 $8 / 輸出 $32(每百萬 token,約 NTD 256 / 1,024) |
| 訂閱存取 | ChatGPT Plus+ | ChatGPT 所有方案;API 預計 2026 年 5 月開放 |
非拉丁語系支援是這次升級的核心之一。GPT-Image-2 明確強化了中文、日文、韓文(CJK)、印地語和孟加拉語的字符渲染,字形筆畫清晰、版面整合度高。TechCrunch 的早期評測用「像素完美」(pixel-perfect)形容其文字表現。
中文渲染:AI 圖像最難啃的骨頭
AI 圖像模型長年的罩門是文字——拼字錯誤、字形扭曲、排版錯位在過去幾乎是常態。GPT-Image-1 在 2025 年 3 月推出時已有明顯改進,但 CJK 文字仍不穩定。GPT-Image-2 把這塊從「偶爾可用」推到「可進量產」的水準。
從實際測試看,幾個場景特別能驗證這一點:
- 漫畫框格。生成附有中文對白框的網格紙漫畫,九宮格佈局無錯字,紅色批註文字正確,手寫感真實。這類場景在 Midjourney 上幾乎不可能一次到位。
- 菜單類印刷品。重現 80 年代台灣的菜單,中文菜名、價格排版、舊式印刷質感均有效呈現。同一場景用 Grok 生成時出現明顯版面錯誤(空白方框和文字缺位),對比明顯。
- 積木玩具包裝。產品特色介紹、拼搭步驟說明均以繁中呈現,文字可辨率高,但圖片預設下載尺寸約 2–3MB,清晰度低於 Midjourney 輸出,細節文字在放大後偶有模糊。


GPT-Image-2 的中文渲染在二維平面場景表現突出。3D 效果(如空間透視燈籠排列)仍是弱項——越往遠處的文字越模糊,說明模型對 2D 字符渲染的優化深度尚未完全移轉到具備 3D 空間邏輯的場景。
5 個代表性設計場景實測
場景一:UI 設計稿轉高保真頁面
給定「生成 iOS 風格 Tinder App,Mix with Google UI Design Guideline 」的提示詞,GPT-Image-2 輸出了設計一致性很強的多畫面版面,包含首頁、發現、收藏等分頁,整體 UI 邏輯和視覺風格跨畫面保持連貫。
這對前端開發流程有直接意義:設計師可以把 GPT-Image-2 的高保真 UI 截圖直接交給 Claude 或其他 AI coding 工具進行元件轉換,省去 Figma 中間步驟。這個組合——GPT-Image-2 生成 UI → Claude 編程——比先前「Grok 生成 → Claude 轉換」的流程在視覺一致性上更有優勢,因為 GPT-Image-2 對 UI 細節的掌握度更高。
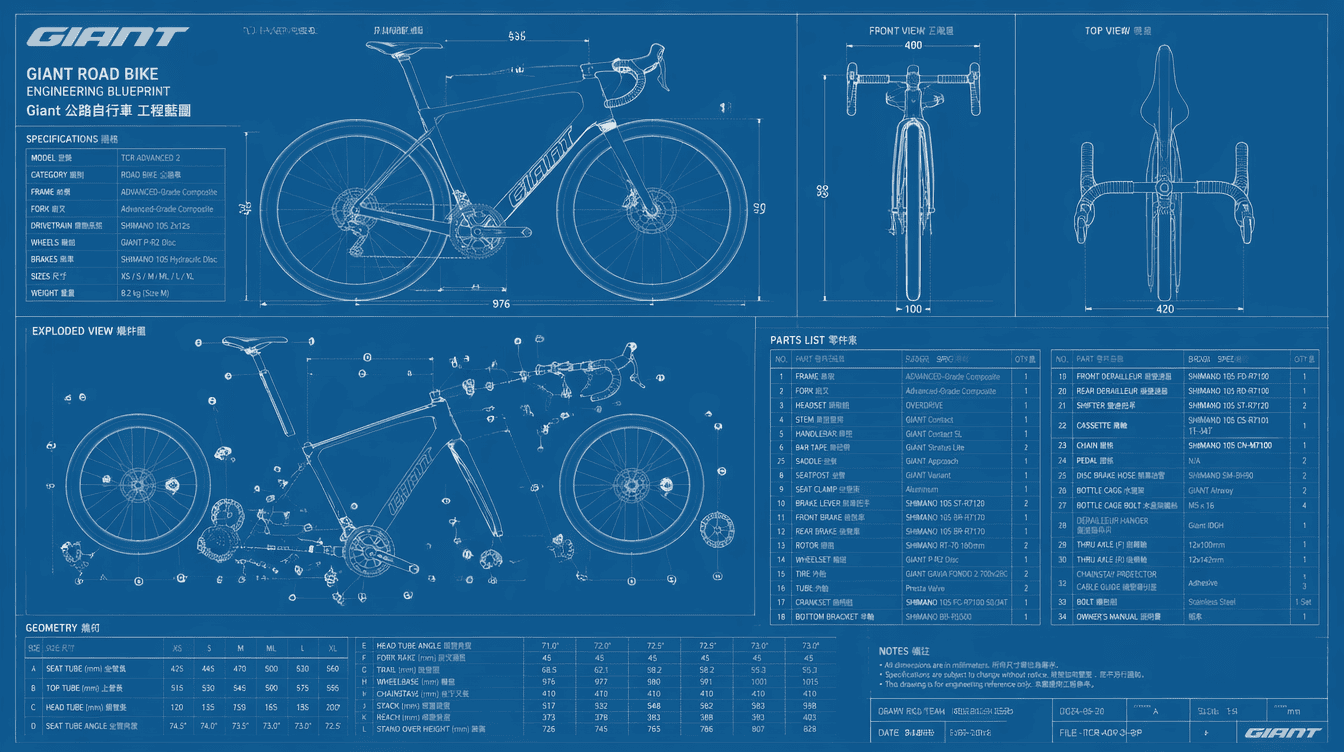
場景二:工程技術圖面
「Giant Road Bike 自行車工程藍圖,青藍底白線,三視圖加爆炸圖」——模型輸出了包含零件明細表(01 到 19 號)的完整工程圖樣式。爆炸圖的零件標示總體清晰,個別標示存在對應偏差,但整體視覺上接近專業工程藍圖的呈現。
對於需要生成技術說明書草稿、產品展示用工程圖的場景,GPT-Image-2 可作為 0 到 1 階段的參考素材,不建議直接用於精密零件的工程核對。
場景三:教學與資訊圖表
Thinking 模式下,GPT-Image-2 能夠「先搜尋、先規劃、後渲染」。測試中以「Token 的工作原理,一句概括」為題,模型先查詢知識、輸出概念架構,再繪製出白底藍字的解說圖——風格偏向 OpenAI 自家的教學風格,與 Midjourney 的藝術感截然不同,但在知識傳達的準確性和清晰度上有優勢。
教學與資訊圖表 teaching How to Read Number for a 3 years old kid, Drawing illustration in Style of dr.seuss


同樣在 Thinking 模式下,提供論文連結後可直接生成 9:16 比例的長圖解讀,適合社群平台直接使用。
場景四:生活感物件還原
這個場景最能體現 GPT-Image-2 的「世界知識」深度。膠片相機沖印記錄的老化質感、人教版小學練習冊的批改畫面,這些高脈絡化的中文生活場景,GPT-Image-2 都還原得相當到位。整體文本密度和真實感明顯優於市面上其他模型。

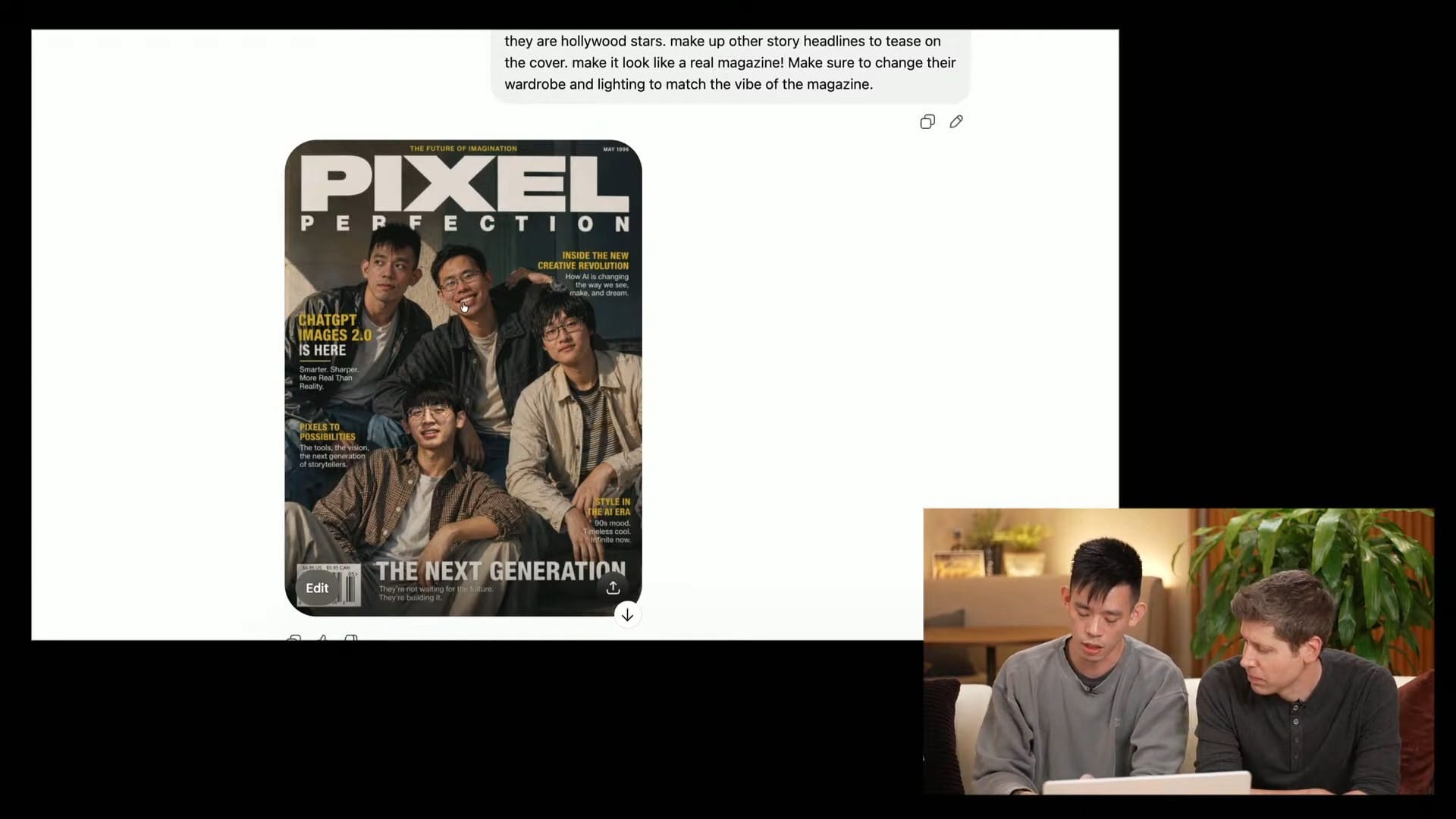
場景五:視頻封面與行銷素材
16:9 比例的視頻封面現在可以直接生成。測試中把既有圖片交給 GPT-Image-2 做封面優化,改版後的整體視覺層次和吸睛度確實提升。這個使用場景在行銷工作流中的價值很直接:社群行銷人員可以在 ChatGPT 裡完成草稿生成、版面調整、文字加入三個動作,不需要切換工具。

與 Grok 及 Midjourney 的定位差異
| 維度 | GPT-Image-2 | Grok Imagine(xAI) | Midjourney v7 |
|---|---|---|---|
| 中文字渲染 | 99% 準確率,CJK 全支援 | 多處錯別字,表現不穩定 | 中文字渲染弱,字形失真 |
| 版面指令遵循 | 強,尤其多物件場景 | 中等,複雜版面易崩 | 強(限藝術風格) |
| 生活感 / 真實感 | 高,世界知識廣 | 高(攝影感強) | 中(偏藝術渲染) |
| 圖片下載解析度 | 2–3MB,略低 | 相似水準 | 高清,適合輸出用途 |
| 16:9 / 9:16 支援 | 完整支援 | 支援 | 支援 |
| Thinking 推理模式 | 支援(付費方案) | 無 | 無 |
| 價格(API) | $0.01–$0.41 / 張(fal.ai) | 有免費額度 | 訂閱制,$10–$120/月 |
Grok Imagine 2 預計近期推出,屆時中文渲染表現應有大幅改進,但目前差距仍明顯。Midjourney v7 在藝術風格和高清輸出上仍有優勢,但它的強項是美學,不是工程圖和資訊視覺化。GPT-Image-2 填補的恰好是這塊空白:大量文字、複雜版面、高指令遵循度的設計場景。
已知限制與注意事項
解析度:GPT-Image-2 標準輸出約 2–3MB,清晰度低於 Midjourney。如果需要高清輸出,可搭配 fal.ai 的 upscaler 管線——以 quality=low 生成後再上採樣,可以用更低成本達到 4K 輸出。
3D 透視中的文字:模型對 2D 平面的文字渲染已近乎完美,但涉及 3D 空間透視的文字(如長廊燈籠、曲面包裝的側面文字)仍會在遠景處模糊失真。
複雜結構邏輯:折疊屏產品的折疊方式、積木拼圖的零件對應,這類需要空間邏輯推演的場景仍有錯誤。模型參考了大量市場素材,有時會直接套用已有海報的設計語言。
白平衡偏黃問題已修正:GPT-Image-1.5 的輸出常出現暖黃色偏,GPT-Image-2 已解決這個問題,色彩還原更準確。
版權與水印:OpenAI 在 GPT-Image-2 中內建了 C2PA 元資料和數位水印,但截圖或圖片重新壓縮後水印會消失,官方也承認這不是「萬無一失的解法」。企業用途需留意生成內容的商業使用條款。
定價與訂閱方案
ChatGPT 所有方案(包含免費版)從 2026 年 4 月 22 日起可存取 GPT-Image-2 基礎模型。Thinking 模式(含網路搜尋和多圖生成)保留給付費訂閱用戶。API 存取預計 2026 年 5 月開放,官方定價為輸入 $8 / 輸出 $32(每百萬 token,即約 NTD 256 / 1,024)。
以 fal.ai 的 per-image 計費為參考:低品質 1024×768 約 $0.01 / 張(NTD 320),高品質 4K 約 $0.41 / 張(NTD 13,120)。
DALL-E 2 和 DALL-E 3 已確認將於 2026 年 5 月 12 日停用,GPT-Image-2 是 OpenAI 官方指定的接班方案。
常見問題
GPT-Image-2 的中文字渲染真的比 Midjourney 好嗎?
在需要大量中文文字的設計場景(資訊圖表、產品包裝、UI 介面、菜單),GPT-Image-2 明顯優於 Midjourney。後者的字符生成不穩定,錯字率高。如果優先考慮的是藝術風格和高解析度輸出,Midjourney 仍有競爭力。
GPT-Image-2 現在就可以在 ChatGPT 免費版使用嗎?
基礎功能已對所有用戶開放。但生成更複雜、需要推理的圖像(Thinking 模式、多圖輸出)需要付費方案。
GPT-Image-2 的圖片可以直接用於商業用途嗎?
OpenAI 的使用條款允許商業使用,但需留意:生成圖片中若包含知名人物、品牌商標或受版權保護的設計元素,使用前應做法律確認。內建的 C2PA 水印在截圖後會消失,企業建議保留原始生成記錄。
生成品質和 API 的 quality 參數有關係嗎?
有。quality=low 生成 1024px 圖,速度最快、成本最低;quality=high 最高支援 4K,成本顯著增加。搭配 upscaler(如 fal.ai 的管線)可以用低品質生成後上採樣,在成本和清晰度之間取得平衡。
GPT-Image-2 可以接受圖片輸入再做編輯嗎?
支援。模型接受圖片輸入,可以針對指定區域進行修改、風格轉換或版面重組。這個功能對行銷團隊批量調整素材特別有用。
參考資料
- TechCrunch — ChatGPT's new Images 2.0 model is surprisingly good at generating text
- OpenAI API Docs — GPT Image 2 Model
Author Insight
我們看到最直接的價值,是「GPT-Image-2 生成 UI 截圖 → Claude Code 轉換元件」這條管線。過去 Grok 或 Midjourney 生成的 UI 圖,Claude 在轉換時常需要花大量 prompt 來糾正細節;GPT-Image-2 的高指令遵循度讓這個環節的摩擦明顯降低。
如果你正在評估如何把 AI 圖像生成整合進品牌內容或產品設計流程,歡迎跟 Tenten 團隊預約諮詢,我們可以根據你的使用場景和現有工具組合給出具體建議。









