
OpenClaw 記憶外掛實戰:MemOS Plugin 如何將 Token 消耗砍掉七成
OpenClaw 用戶最常遇到的兩個問題,一是 Token 燒得太快,二是記憶靠不住。MemOS 團隊針對這兩個痛點推出的 OpenClaw Plugin,在 LOCOMO 長對話記憶基準測試中實現了 70% 的 Token 消耗降幅,模型呼叫頻率也減少了近六成。這篇文章拆解這套方案的運作原理、安裝流程與實際效果,幫你判斷它是否值得導入。
OpenClaw 的記憶困境
OpenClaw 作為一款 7×24 小時運行的 AI Agent 框架,在螢幕監控、定時任務、工作流自動化等場景中,Token 消耗速度遠超一般對話使用。根本原因在於它的記憶機制:每次對話都會把先前的對話歷史附帶上去。
一位開發者的實測案例頗具代表性:讓 AI 撰寫 Python 程式碼,每輪對話都要附帶完整程式碼上下文,單次對話直接消耗 15 萬 Token。按 Claude Opus 的定價計算,這相當於每次對話花費約 NTD 200 左右。
記憶品質同樣成問題。OpenClaw 的原生記憶存放在本地 .md 檔案中,分為全域記憶和每日記憶兩層。實際使用會碰到三個狀況:記憶依賴 AI 主動寫入,該記的常常沒記住;上下文壓縮(compaction)觸發時,重要記憶可能被裁剪掉;Session 重啟後,先前的上下文直接消失。
這些問題的根源在於 OpenClaw 將「記憶等同於上下文」——狀態靠 Token 堆疊維持,長期能力靠上下文累積。這套範式在短對話中可行,但在長時間運行的 Agent 場景中,成本和品質都會失控。

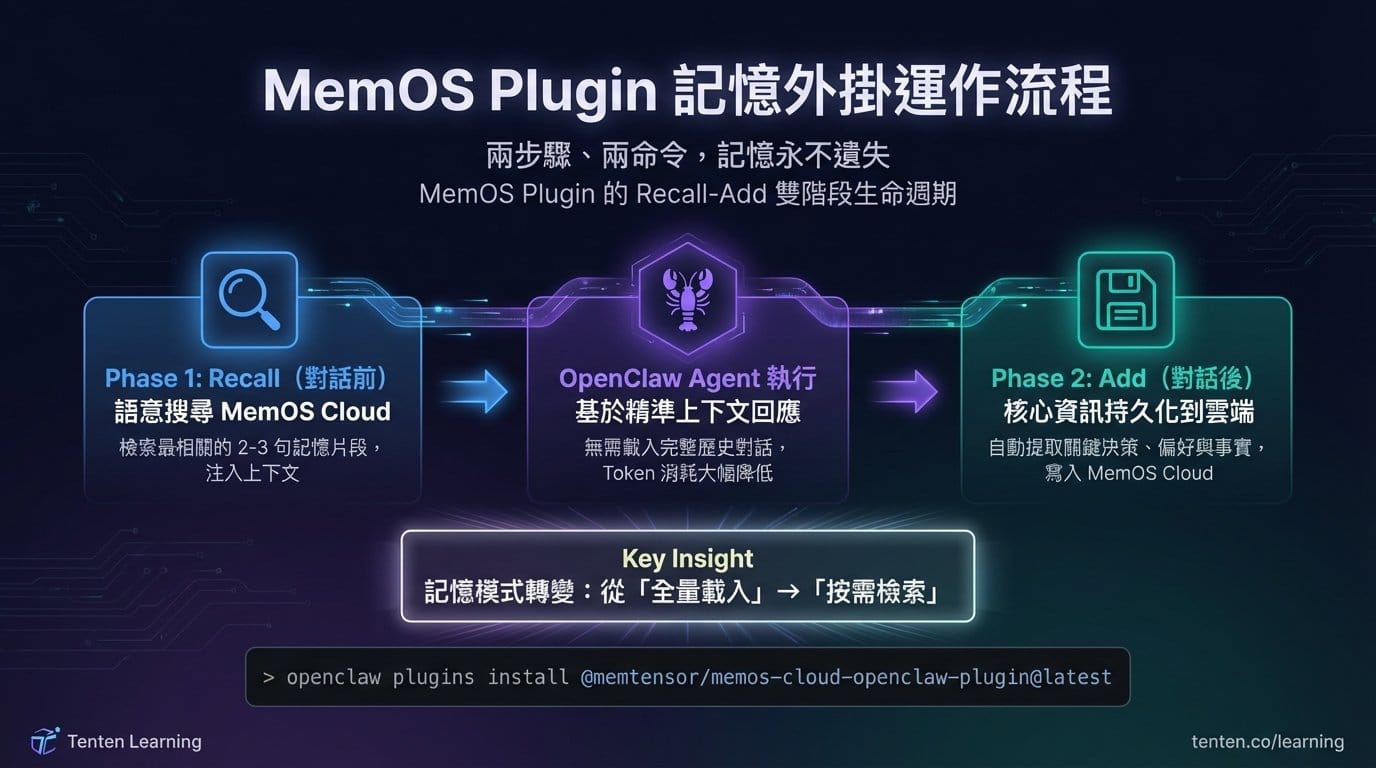
MemOS Plugin 的解法
MemOS 的核心思路是將記憶從上下文窗口中抽離,變成獨立的系統層。Plugin 的工作流程分為兩個階段:
對話前(Recall 階段),Plugin 向 MemOS Cloud 發送語意搜尋請求,根據當前問題檢索最相關的記憶片段,注入到上下文中。對話後(Add 階段),Plugin 提取本輪對話的核心資訊,持久化到 MemOS Cloud。
這個設計帶來的改變是:OpenClaw 不再需要把所有歷史對話塞進上下文。系統只載入與當前任務相關的記憶,通常只有 2-3 句話的精準片段,而非整段歷史。MemOS 官方在 LOCOMO 資料集上的測試結果顯示,Token 消耗從 1,560 萬降到 440 萬,降幅達 72%;記憶精準率從 23.73% 提升到 31.68%。
與另一個熱門方案 QMD(Shopify 創辦人 Tobi Lütke 開發的本地語意搜尋引擎)相比,MemOS Plugin 走的是雲端路線。QMD 完全本地運行、零 API 成本,但需要自行維護索引和模型。MemOS Plugin 安裝更簡單(兩條命令),支援跨裝置、跨 Session 的記憶共享,且提供多 Agent 協作的共享記憶池。
多 Agent 協作:共享記憶池的實戰價值
MemOS Plugin 更值得關注的功能是多 OpenClaw 實例間的記憶共享。傳統的多 Agent 架構中,Agent A 產出的內容需要透過對話傳遞給 Agent B,B 的輸出再手動複製給 C。所有資訊在各 Agent 之間重複傳遞,Token 消耗成倍增長。
MemOS 的解法是透過統一的 user_id 將多個 Agent 連接到同一個記憶池。具體運作方式如下:
| 架構要素 | 傳統方式 | MemOS 方式 |
|---|---|---|
| 資訊傳遞 | 手動複製貼上 | 統一記憶池自動同步 |
| Token 消耗 | 每個 Agent 重複載入全部上下文 | 各 Agent 按需檢索相關片段 |
| 記憶隔離 | 無法區分 | 支援共享記憶 + 私有記憶分層 |
| 跨裝置存取 | 依賴本地檔案 | 雲端儲存,任何裝置可存取 |
實測案例:在虛擬機中告訴 OpenClaw A 自己喜歡的食物和偏好,切換到本機的 OpenClaw B,B 依然能準確回憶這些資訊。記憶不再綁定於單一裝置或 Session。
這對正在搭建「數位員工團隊」的企業來說,意義尤其明確。一個辦公室裡的多個 AI Agent,各自處理不同任務(選題推送、社群運營、行程提醒等),透過共享記憶層實現資訊無縫流通,避免重複溝通帶來的 Token 浪費。
安裝與設定
整個安裝流程只需要兩步:
第一步:前往 MemOS Dashboard 註冊並取得 API Key。
第二步:在終端執行安裝命令並重啟:
openclaw plugins install @memtensor/memos-cloud-openclaw-plugin@latest
openclaw gateway restart
確認 ~/.openclaw/openclaw.json 中已啟用:
{
"plugins": {
"entries": {
"memos-cloud-openclaw-plugin": {
"enabled": true
}
}
}
}
Windows 用戶如遇到 Error: spawn EINVAL 錯誤,需採用手動安裝方式:從 NPM 下載 .tgz 包後解壓到本地目錄。
進階設定方面,Plugin 支援多項環境變數調整:MEMOS_USER_ID 預設為 openclaw-user,多個 OpenClaw 實例使用相同的 user_id 即可共享記憶;MEMOS_RECALL_GLOBAL 預設為 true,啟用全域記憶搜尋;memoryLimitNumber 建議設為 6,這是社群測試出的資訊密度最佳值。
記憶方案的選擇比較
目前 OpenClaw 社群主要有三種記憶優化方案,各有適用場景:
| 方案 | 部署方式 | Token 節省幅度 | 多 Agent 協作 | 適合對象 |
|---|---|---|---|---|
| MemOS Plugin | 雲端 | 60-72% | 支援(核心功能) | 重視跨裝置/多 Agent 協作 |
| QMD | 本地 | 60-97% | 不支援 | 重視隱私和零成本 |
| Mem0 Plugin | 雲端/本地可選 | 未公開基準數據 | 支援 | 重視長短期記憶分離 |
三種方案都解決了同一個核心問題:把記憶模式從「全量載入」改成「按需檢索」。差異在於部署偏好和功能側重。
需要注意的是,MemOS Plugin 依賴雲端服務,這意味著對話資料會傳送到 MemOS 伺服器。對數據隱私要求較高的場景,QMD 的純本地方案可能更合適。MemOS 也提供自建部署選項,但需要額外的基礎設施維護。

對 OpenClaw 生態的啟示
OpenClaw 在 2026 年初的爆發式成長,讓「AI Agent 記憶系統」成為開發者社群最熱門的議題之一。arXiv 上的研究論文〈Memory in the Age of AI Agents〉指出,記憶已成為基礎模型 Agent 的核心能力,但現有的長短期記憶分類法已不足以描述當代 Agent 記憶系統的多樣性。
Gartner 預測,到 2026 年底將有 40% 的企業應用嵌入 AI Agent,較 2025 年的不到 5% 大幅成長。在這個趨勢下,記憶系統的品質將直接決定 Agent 能否從「聊天工具」進化為「可靠的數位員工」。
Anthropic 的 MCP 協議和 Claude Code 的 CLAUDE.md 檔案,都在嘗試解決類似問題。MemOS 則提出了更激進的主張:記憶應該被視為獨立的作業系統層,而非 Prompt 的附屬品。這個方向是否會成為主流,取決於成本效益和開發者體驗的持續優化。
引用來源
- MemOS GitHub Repository — MemTensor
- MemOS Cloud OpenClaw Plugin — MemTensor
- Memory in the Age of AI Agents: A Survey — arXiv
- OpenClaw Memory Documentation — OpenClaw
- Stanford CS329A: Self-Improving AI Agents — Stanford University
- MIT 2025 AI Agent Index — MIT MATS Research
關於作者
本文由 Tenten 技術內容團隊撰寫。在 AI Agent 快速普及的當下,記憶系統正從技術細節演變為決定 Agent 能否投入生產的關鍵瓶頸。對於已經在使用 OpenClaw 或計劃導入 AI Agent 的團隊,選擇合適的記憶方案——並理解每種方案背後的取捨——比單純追求最新工具更為重要。
若您正在規劃 AI Agent 導入策略,或需要優化現有的 AI 工作流程架構,歡迎與 Tenten 團隊預約諮詢,我們將根據您的業務場景提供具體建議。
原始內容來源:lxfater(鐵鎚人)X.com 貼文
延伸閱讀:








