

OpenAI 最新推出的 O3 模型,為人工智慧領域帶來前所未有的變革。本文深入解析 O3 模型的關鍵技術、以及它如何重新定義 AI 的可能性。
近年來,AI 產業突飛猛進,許多專家都在討論「AGI(Artificial General Intelligence)何時降臨」。而今,OpenAI 正式揭露全新模型 O3,一舉在重要的 ARC Benchmark 上超越人類水準,或許意味著 AGI 時代正悄然來臨。
OpenAI 的新 O3 模型的推出改變了一切
近期 AI 的發展讓我們懷疑 LLM 的進步是否已經到了瓶頸。然而前幾天 OpenAI 推出的全新 O3 模型,徹底推翻了這種說法,並為整個產業帶來衝擊。在各項測試與實務應用上,OpenAI O3 模型展現出了跳躍式的成長,不僅在程式碼生成、數學推理以及科學運算方面大幅超前,其在 AGI(通用人工智慧)相關的評估基準也達到了前所未見的高度。以下將為您梳理 OpenAI O3 模型的核心進步與未來影響。

O3 模型的顯著突破
1. ARK AGI 測試得分刷新紀錄
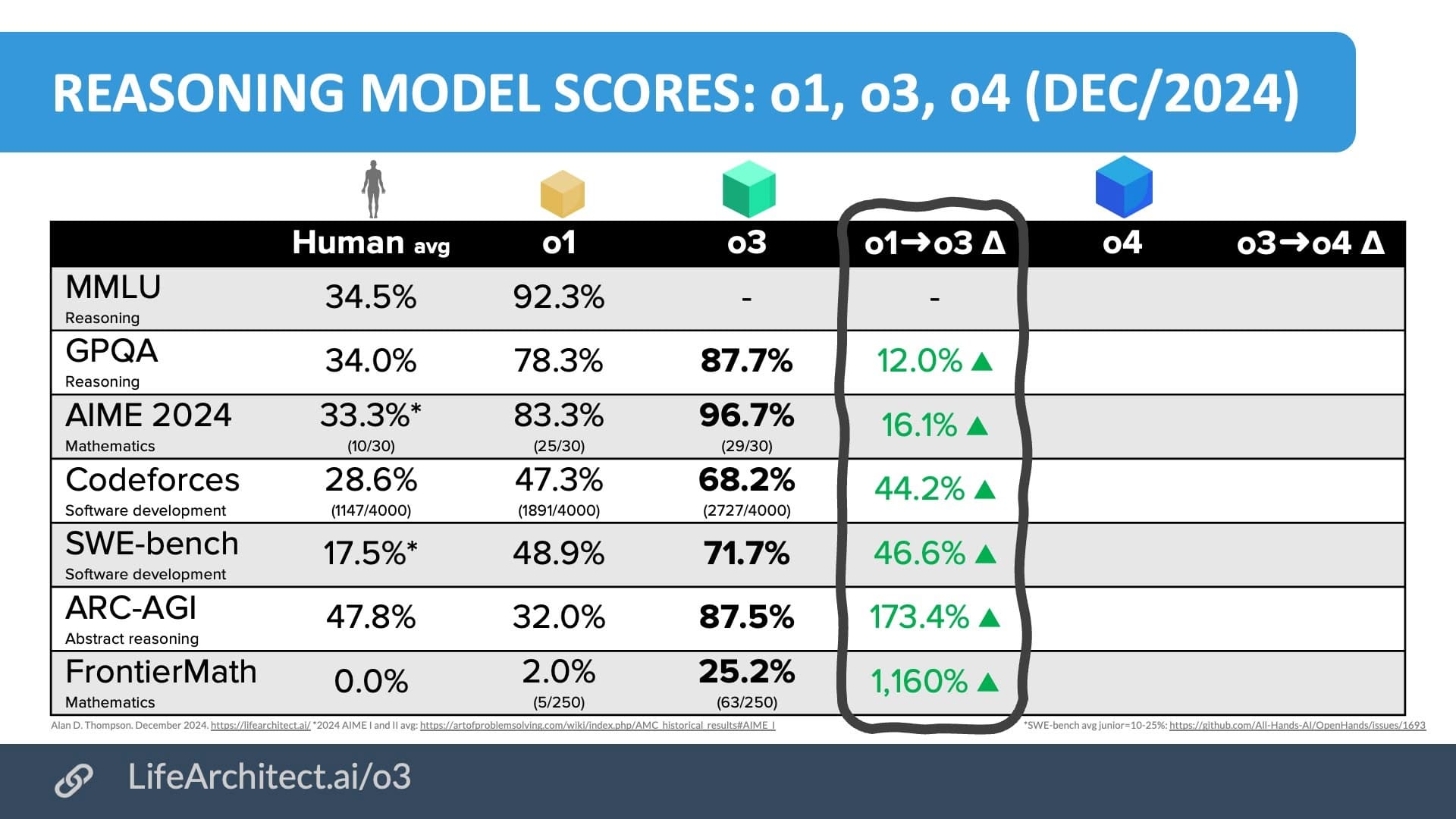
OpenAI O3 模型最令人震撼的一點,是在極具挑戰性的 ARK AGI 測試上取得了突破性的高分。過去大多數模型在這項測試中僅能達到 5% 以下的表現,但 O3 的低算力版本已經有 75.7% 的成績,高算力版本更飆破 85.7%,這幾乎可與人類的平均水準相抗衡。ARK AGI 測試特別考驗 AI 在面對全新問題時,能否理解抽象規則並進行推理,而 OpenAI O3 模型成功展現出難以置信的通用能力。
FrontierMath解題測試 (o3 可解 25%)
99.99% 的人無法理解 FrontierMath 有多瘋狂。以下這些問題都是由數學教授精心設計的,沒有任何訓練資料。
數學傳奇人物 Terry Tao 曾說:「這些問題極具挑戰性。我認為它們至少可以抵抗人工智能幾年。
OpenAI o3 在 FrontierMath 測試取得了 25% 的成績。

2. 成本與硬體限制
雖然 OpenAI O3 模型的能力極具吸引力,但也不可忽視其高昂的運行成本。測試顯示,執行 O3 所需的硬體資源與計算量都是前所未見的,一次大型測試的花費可能高達數千甚至數萬美元。這表示即使 AI 技術在演算法上有長足進步,能否負擔起如此高負載的硬體需求,成為了新一波競賽的關鍵因素。
3. 從程式碼生成到科學研究
從程式碼生成到複雜科學問題的解題能力上,OpenAI O3 模型都遠勝前一代的版本。它不但能自行創建程式碼、啟動伺服器、呼叫 API,甚至能編寫並執行能再次呼叫自己的腳本,讓整個流程自動化程度達到新高度。這種自我評估與自我生成的概念,代表 AI 代理可以自行發展解決方案,減少人類工程師在開發流程中的反覆介入。
何謂 ARC Benchmark?為何與 AGI 息息相關?
ARC Benchmark 是專為 AI 設計的「IQ 測驗」,也是評估 AGI 能力的一大指標。它與一般測驗不同之處在於「抗記憶化能力」。大多數語言模型(LLM)都依賴龐大資料量來進行學習,透過記憶和比對網路上無數案例來解決問題。然而,ARC Benchmark 的題目刻意避免重複形式,並僅需「核心常識」即可回答。這些題目對人類而言輕而易舉,但對 AI 來說,一直是重大挑戰。
在過去五年裡,各家頂尖模型在 ARC 的表現始終無法逼近人類平均水準。然而,OpenAI 的 O3 模型如今創下 75.7% 的高分,遠遠領先先前所有版本,甚至超越大部分人類在相同測驗中的成績。許多專家視這次突破為邁向 AGI 的重要里程碑。
OpenAI 03 Model:全新時代的程式設計與 AI 潛能
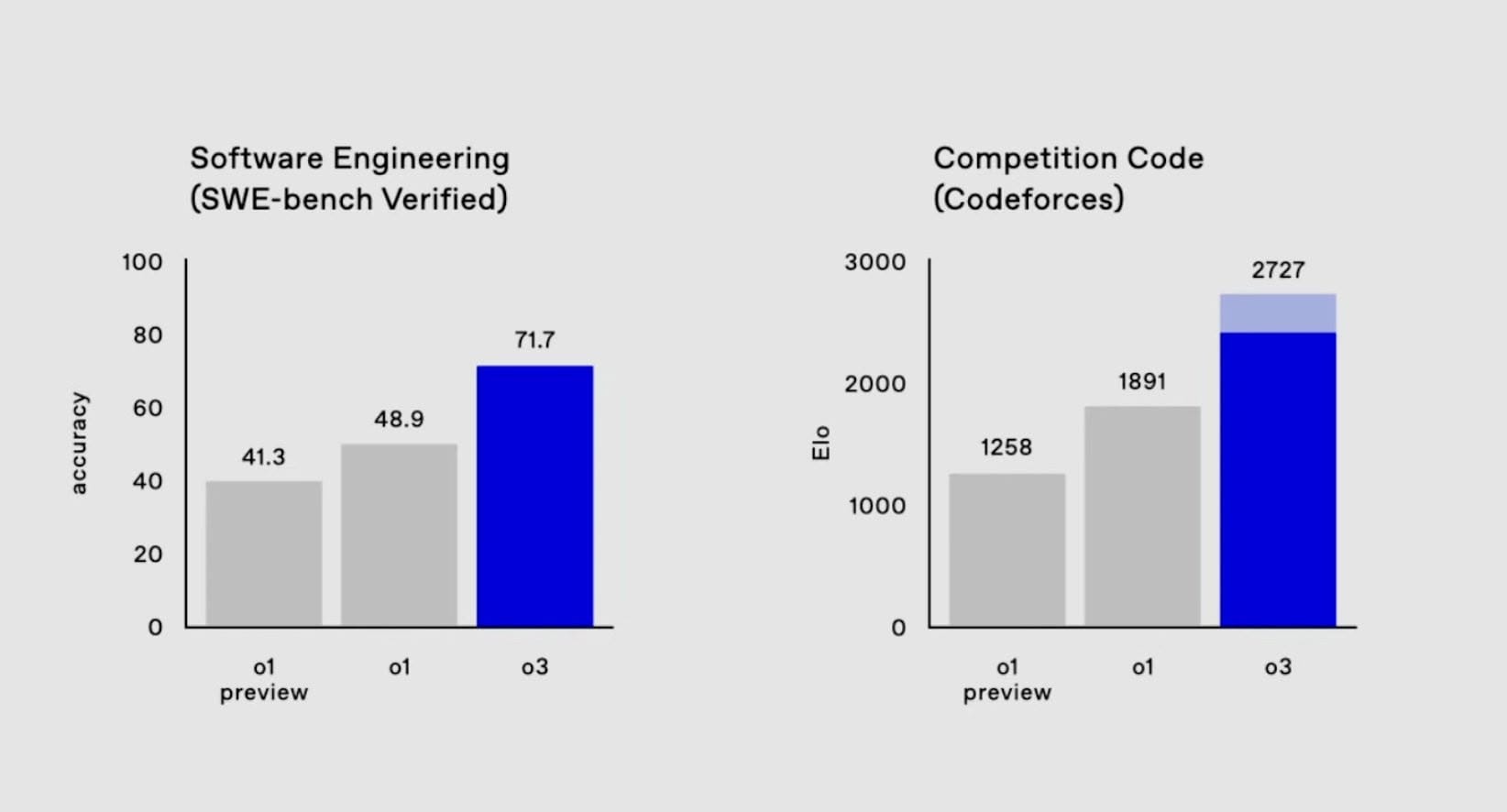
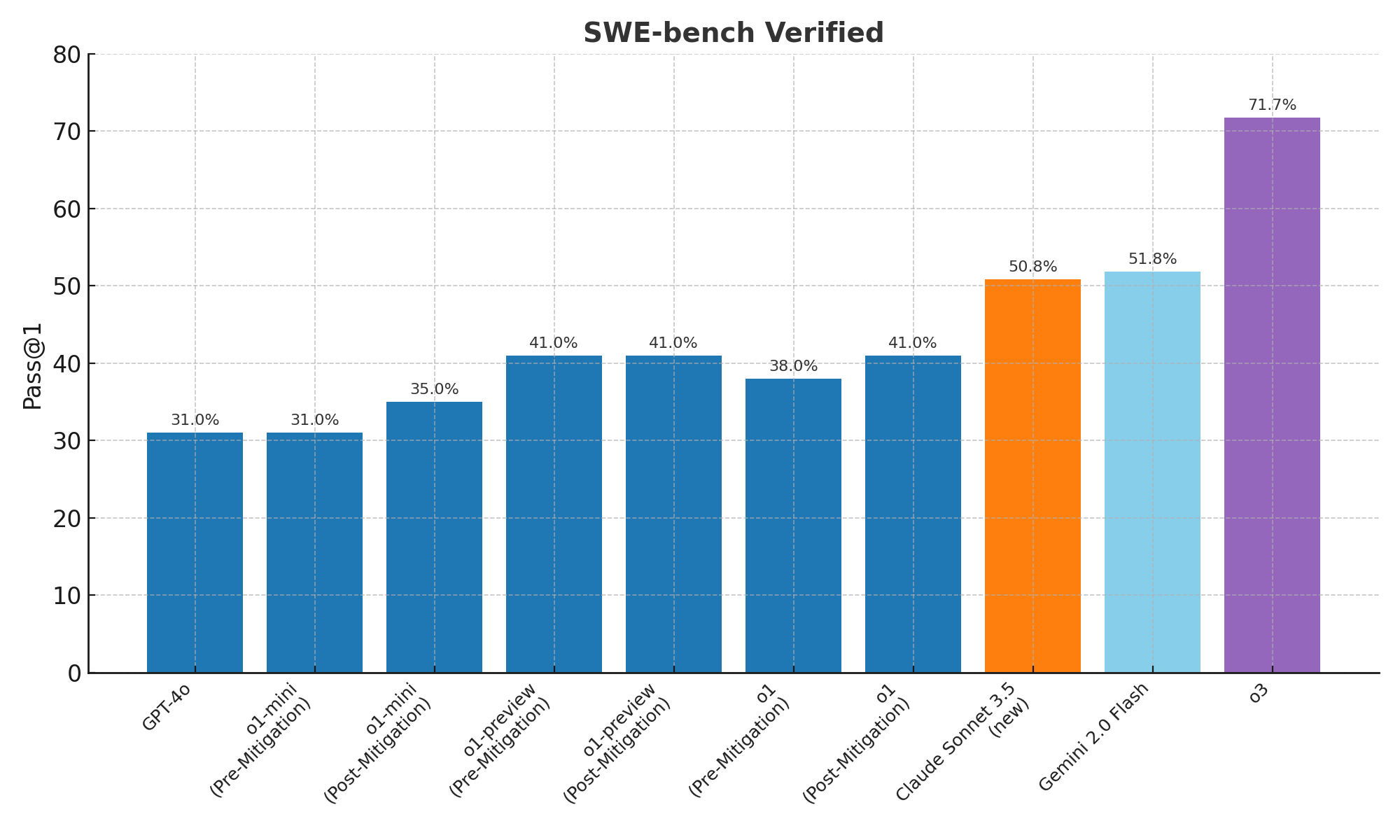
o3 的程式實力已超越絕大多數的開發者,甚至在 Codeforces 的排名中達到全球第 175 名,如此優異的成績不僅改寫了人們對 AI 寫碼的想像,更預示著未來軟體開發模式將進入全新階段。本文將深入探討 OpenAI 03 Model 的突出特點、潛在影響以及後續發展走向。
從「AI 程式碼很糟」到「全球頂尖」的重大轉變
在 OpenAI 03 Model 出現以前,許多人對 OpenAI 的模型生成的程式碼並不抱太大期望,認為「GPT4o 寫的 code 的表現不如 Claude」,反而認為 Claude 的 Sonnet 3.5 或是 Alibaba Qwen-2.5 code 的程式生成的表現較佳。然而,OpenAI 03 Model 透過大規模訓練與演算法優化,徹底顛覆了過去的刻板印象。它不但能生成冗長且複雜的程式碼,更能執行高難度的數學運算與邏輯推理,讓人驚嘆於 AI 已可在寫程式領域達到前所未見的高度。
特別值得關注的是,OpenAI 03 Model 的表現已躍居 Codeforces 排名前 200,這對任何想用 AI 輔助寫程式的人而言,都是一個巨大的里程碑。當前若有人還認為 AI 程式碼「不夠好」,恐怕得重新審視此一認知。
過去我們以前從未見過 LLM 直接成長 20% 的情況。這不是“好”或“非常好”而已,而是 o3 的推出讓我們重新考慮 AI 的進步曲線。 之前的 GPT-4o, Gemini 2.0 Flash 和 3.6 Sonnet 的進步曲線很接近。 GPT-4o 於 2024 年 5 月發布!但從 OpenAI o1 正式發布 o1 到 o3 的發布時間間隔僅為 57 天。
以下是有關 Codeforces 結果的一些背景資訊。 o3 的 ELO 為 2727,躋身全球200 名最具競爭力的程式設計師之列。高於OpenAI自己首席科學家的2665分。
OpenAI o3 is 2727 on Codeforces which is equivalent to the #175 best human competitive coder on the planet.
— Deedy (@deedydas) December 20, 2024
This is an absolutely superhuman result for AI and technology at large. pic.twitter.com/l43DTJDTqR
o3 竟然達到全球程式設計師的排名 175 名 - 前 99.7% !
O3 的多重設定:低推理模式與高推理模式
OpenAI 這次同時推出兩種版本:
- O3(低推理模式):運算資源用量少、反應迅速,適合處理簡易問題或基礎程式碼生成。
- O3(高推理模式):面對複雜與多步驟推理的任務時,會投入更高運算量,也帶來更強大的解題能力。
有趣的是,低推理模式雖然運算量較少,但在一般場景已能取得不錯表現;然而,一旦切換成高推理模式,模型對複雜問題的解決能力更勝人類,這也是為何許多研究者驚呼 AGI 似乎不再遙遠。
算力成本不斷攀升,但未來或將大幅下降
值得注意的是,O3 高推理模式雖然效果驚人,但使用成本同樣高昂。依照目前測算,單次任務的花費可高達數千甚至上萬美元。雖然這聽來驚人,但回首過去科技史,我們也能看到類似的軌跡:早年的大型電腦價格高不可攀,電視、手機都曾是笨重而昂貴的裝置,如今卻變得平民化且功能強大。AI 研究者因此相信,AGI 的門檻和成本會隨著技術進步與規模化而逐漸降低。
持續擴展的 AI 能力:突破傳統基準後的新挑戰
除了在 ARC Benchmark 上大放異彩,O3 在軟體工程領域的 SWE 基準測試與高階數學測驗上,也取得顯著成長。尤其是面對大量「前所未見」的研究級數學題,O3 取得的分數竟比先前最頂尖的模型高出近 20 倍,可說在該領域實現了質的飛躍。
OpenAI 研究員也坦言,O3 只是「第二代」模型,未來尚有更多空間能再度提升。O2 之所以缺席,是因為商標與其他品牌(英國一家電信業者 O2)的名稱重疊,才直接跳到 O3。這也意味著:從現在起,O4 可能帶來更驚人甚至顛覆性的成果。
為何 OpenAI 03 Model 需要「安全測試」?
相較於早期的 GPT-3.5 或其他版本,OpenAI 03 Model 這次強調的是更強大的數學與程式設計能力。開發者甚至表示,因為它的邏輯與生成能力大幅提升,官方還要求進行「安全測試」(Safety Testing),可見新系統的潛力與複雜度足以帶來更廣泛的影響。
官方也釋出申請管道,讓有意提早試用 OpenAI 03 Model 的開發者提交申請,並預計在 1 月 10 日截止接受申請。據推測,若一切進展順利,最早可能在 3 月左右將此版本開放給廣大用戶。
驚人的演進速度:從 01 到 03,只用了幾個月?
回顧今年的更新節奏,OpenAI 01 Model 才剛問世不久,如今 OpenAI 03 Model 就已推出,且威力驚人。這個速度顯示 AI 技術不再像過去的手機年度更新,反而傾向於「數月一次」的大躍進。正因為如此,有人已開始揣測下一個版本 —— 04 Model —— 何時會亮相;更有人認為或許在 2025 年 5 月就能看到它正式登場,顯示整個AI領域正以驚人的節奏持續往前加速。
o3 是否為邁向 AGI 的前瞻模型?
OpenAI 03 Model 的崛起,再度讓外界猜測我們是否正在逼近「人工通用智慧(AGI)」的時刻。雖然還無法斷言此版本就等同於 AGI,但它的專業領域(特別是數理與程式碼)表現的確已相當逼近部分人類專家的水準。這樣的進步速度也暗示,AI 系統正快速走向多功能且高智慧的應用時代,未來必定還有更多令人驚奇的突破。
何謂「AGI」?定義逐漸模糊
OpenAI 執行長 Sam Altman 與不少研究者都曾提及,「AGI」的定義已越來越模糊。一開始,「AGI」代表遠超過人類智慧的通用型 AI,但現在它的定位橫跨多個層級。有些人認為現行模型已是初級 AGI,也有人相信 AGI 應該遠比所有人類加在一起都更聰明。這種分歧代表,我們雖然屢屢在測驗上突破,但真正的「終極 AGI」還有一段路要走。
另一方面,ARC Benchmark 的設計者 François Chollet 曾表示,如果一款模型能在未經任何專業背景知識的情況下,達到人類的八成解題水準,就很可能被視為 AGI。現在,O3 成績已在部分評估中接近或超越這個指標,也難怪有人大呼「AGI 已經來了」。
安全與未來:AGI 時代的下一步
O3 的問世,使得 AI 安全及倫理議題更顯重要。OpenAI、以及其他研究組織呼籲安全領域的專家一起加入測試,力求在 AGI 的研發過程中降低風險。正如大型科技進步往往在初期會遇到高額花費、安全隱憂與社會適應等挑戰,AGI 自然也不例外。未來,我們將看到更多針對 O3 的應用,也可能出現更多創新思維,改變產業乃至社會結構。
實際應用與未來挑戰
1. 研究人員的合作與安全考量
當 AI 模型愈趨強大,安全風險也會相對增高。OpenAI O3 模型展現了能夠根據不同情境進行高效推理的特質,意味著在錯誤或惡意操作下,可能產生難以預料的影響。為此,開放研究測試和強化檢測機制勢在必行,OpenAI 也透過廣邀外部安全專家與研究人員,期望在研發的同時兼顧風險評估。
2. 硬體供應仍是瓶頸
早先業界有一種「硬體過剩」的期待,認為一旦 AI 演算法取得重大突破,就能憑藉大量閒置的硬體資源進一步升級。然而事實證明,市場上能供 Cutting-Edge 研究者使用的硬體並沒有想像中那麼充裕。隨著 OpenAI O3 模型運算需求不斷提高,硬體短缺與高成本的問題將成為可否進行大規模測試的主要障礙。
3. 後續發展與投資
儘管高昂的成本令人生畏,OpenAI O3 模型取得的進步已足以在全球範圍內引發業界追捧。更多企業、研究機構乃至個人投資者都開始關注這股新趨勢,相信未來在硬體研發與演算法優化的雙重助力下,O3 與其他類似模型仍會不斷衍生出更高效、更先進的版本。
結語
OpenAI 的 O3 公布,並在 ARC Benchmark 上創下嶄新紀錄,的確值得所有關注 AI 技術的朋友高度期待。雖然 O3 是否真正代表 AGI,還有不同聲音和定義上的爭議。
不過 o3 模型顛覆了人們對於 AI 已停滯不前的印象。從 ARK AGI 測試的刷新紀錄、程式生成與自動化能力的躍進,到對硬體供需不平衡的檢驗,O3 重新定義了 AI 所能達到的高度。或許未來還有更多新的挑戰與風險,但不可否認的是,OpenAI O3 模型正在縮短了人類與「通用人工智慧」之間的距離。。
了解更多關於 o3
- OpenAI o3: AGI 的曙光?
- AGI 距離我們還有多遠?探討人工智慧的未來
- 什麼是 AGI - 通用人工智慧 (Artificial General Intelligence)?
- OpenAI 推出革命性 o3 模型:開啟AI 新紀元
- OpenAI o3 模型是來自未來的訊息:更新您認為您所了解的有關 AI 的一切 — OpenAI o3 Model Is a Message From the Future: Update All You Think You Know About AI
- OpenAI O3 在 codeforces 上達到 2700 - Codeforces — OpenAI O3 reaches 2700 on codeforces - Codeforces
OpenAI O3 模型常見問答(FAQ)
Q1: OpenAI O3 模型在 ARK AGI 測試中的表現如何? A1: O3 模型在 ARK AGI 測試中取得突破性成績,低算力版本達到 75.7%,高算力版本更達到 85.7% 的成績,接近人類平均水準,遠超過其他模型普遍低於 5% 的表現。
Q2: O3 模型在程式設計方面有什麼突破? A2: O3 模型在 Codeforces 的排名達到全球第 175 名,ELO 分數為 2727,超越了 OpenAI 首席科學家的 2665 分,位居全球程式設計師的前 99.7%。
Q3: O3 模型的主要運算限制是什麼? A3: O3 模型需要極高的運算資源和硬體需求,單次大型測試的成本可能高達數千至數萬美元,硬體供應短缺也是一大限制。
Q4: O3 模型預計何時開放給一般用戶使用? A4: 根據官方消息,開發者申請將於 1 月 10 日截止,若進展順利,最早可能在 3 月左右開放給廣大用戶使用。
Q5: O3 模型與 AGI(通用人工智慧)的關係如何? A5: 雖然還不能完全等同於 AGI,但 O3 模型在數理與程式設計等專業領域的表現已接近人類專家水準,被視為邁向 AGI 的重要里程碑。







