

OpenAI最新推出的o3模型展現了AI發展的新方向,但高昂的訓練成本成為產業發展的一大挑戰。
上個月,AI 創辦人和投資者提出,我們現在正處於「擴展定律的第二個時代」,並指出改進 AI 模型的既有方法正顯示出收益遞減。他們建議一種有希望的新方法可以維持收益,那就是「測試時擴展」,這似乎是 OpenAI 的 o3 模型 效能背後的原因 — 但它也有自身的缺點。
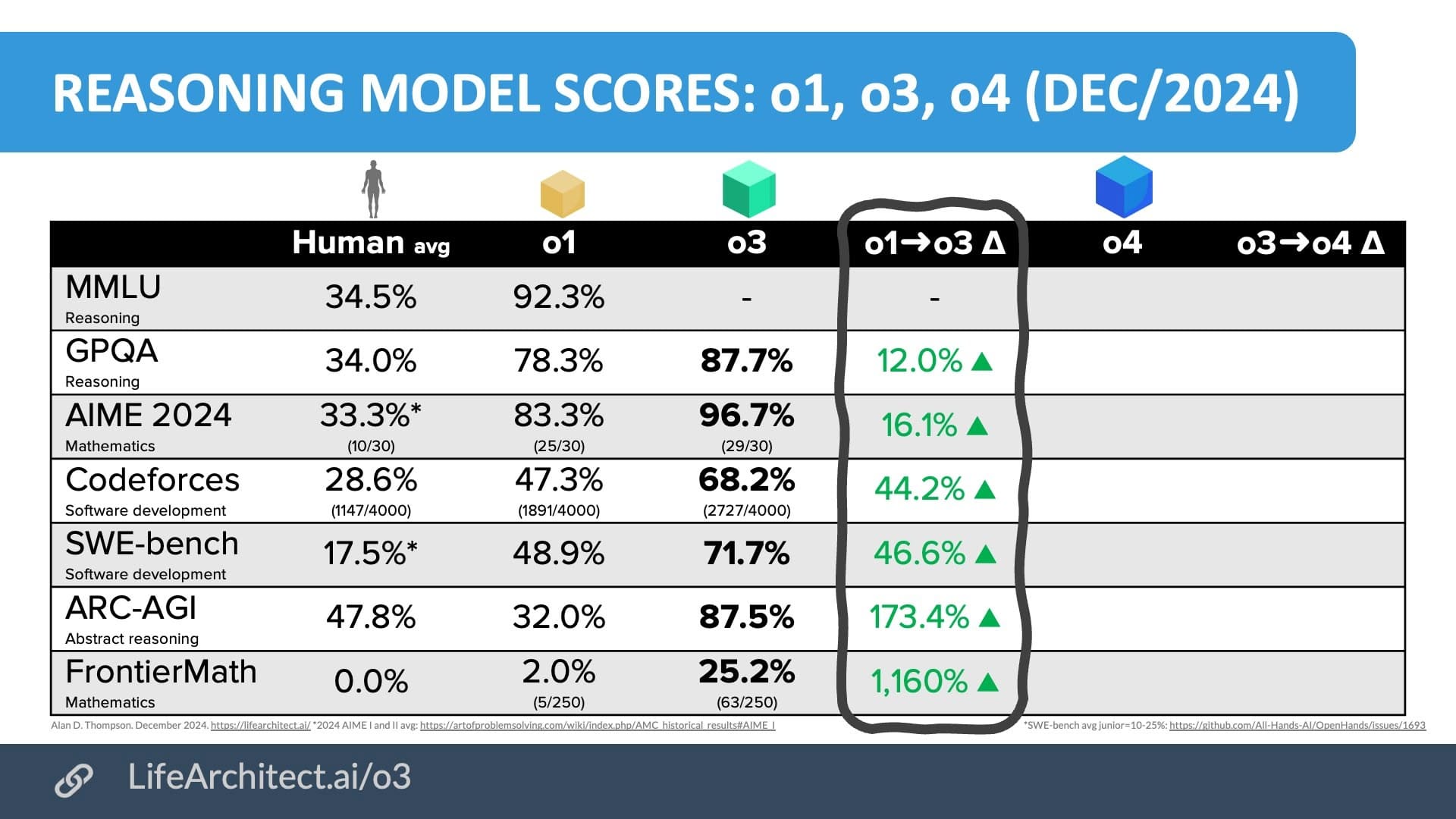
許多 AI 界人士將 OpenAI 的 o3 模型的發布視為 AI 擴展進展並未「碰壁」的證明。o3 模型在基準測試中表現良好,在一項名為 ARC-AGI 的通用能力測試中顯著超越所有其他模型,並在 困難的數學測試 中獲得 25% 的分數,而其他 AI 模型在該測試中的得分均未超過 2%。
當然我們對所有這些都持保留態度,直到我們可以親自測試 o3(到目前為止,很少有人嘗試過)。但即使在 o3 發布之前,AI 界已經確信一些重大轉變已經發生。
OpenAI 的 o 系列模型的共同創建者 Noam Brown 週五指出,該新創公司在宣布 o1 後僅僅三個月就宣布了 o3 的驚人收益 — 對於效能的如此躍升而言,這是一個相對較短的時間範圍。
Brown 在一則 推文 中表示:「我們有充分的理由相信這種軌跡將會持續下去。」
Anthropic 共同創辦人 Jack Clark 在週一的一篇 部落格文章 中表示,o3 證明 AI「在 2025 年的進展將比 2024 年更快。」(請記住,暗示 AI 擴展定律仍在持續對 Anthropic 有利 — 尤其是其籌集資金的能力)
Clark 表示,明年 AI 界將把測試時擴展和傳統的預訓練擴展方法結合在一起,以從 AI 模型中獲得更多回報。也許他是在暗示 Anthropic 和其他 AI 模型供應商將在 2025 年發布他們自己的推理模型,就像 Google 上週推出的 Gemini 2。

測試時擴展意味著 OpenAI 在 ChatGPT 的推理階段使用了更多的計算資源,也就是你在提示符上按下 enter 鍵之後的時間段。目前尚不清楚幕後到底發生了什麼:OpenAI 要么使用更多的電腦晶片來回答用戶的問題,要么運行更強大的推理晶片,要么在 AI 產生答案之前,運行這些晶片更長的時間 — 在某些情況下為 10 到 15 分鐘。我們不了解 o3 是如何製作的所有細節,但這些基準測試是早期跡象,表明測試時擴展可能有助於提高 AI 模型的效能。
雖然 o3 可能讓某些人重新相信 AI 擴展定律的進展,但 OpenAI 的最新模型也使用了前所未見的計算量,這意味著每個答案的價格更高。
Clark 在他的部落格中寫道:「這裡可能唯一重要的警告是理解到 O3 如此出色的原因之一是它在推理時運行需要花費更多的錢 — 利用測試時計算的能力意味著在某些問題上,你可以將計算轉化為更好的答案。」「這很有趣,因為它使得運行 AI 系統的成本在某種程度上變得不太可預測 — 以前,你只需查看模型和生成給定輸出的成本,就可以計算出服務生成模型的成本。」
Clark 和其他人指出,o3 在 ARC-AGI 基準測試中的表現 — 一項用於評估 AGI 突破的困難測試 — 是其進展的指標。值得注意的是,根據其創建者的說法,通過此測試並不意味著 AI 模型已實現了 AGI,而只是衡量朝著這個模糊目標邁進的一種方式。儘管如此,o3 模型超越了之前所有進行過該測試的 AI 模型的得分,在其一次嘗試中獲得了 88% 的分數。OpenAI 的下一個最佳 AI 模型 o1 的得分僅為 32%。

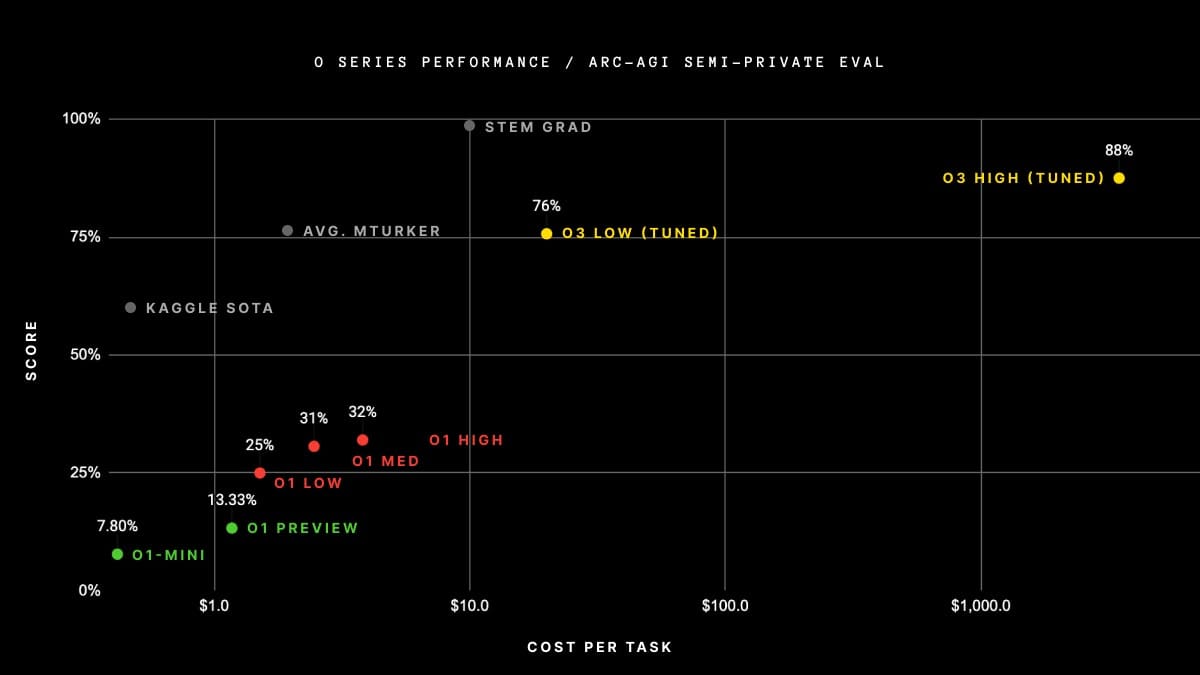
但是此圖表上的對數 x 軸可能會讓某些人感到擔憂。高分版本的 o3 每個任務使用了價值超過 1,000 美元的計算資源。o1 模型每個任務使用了約 5 美元的計算資源,而 o1-mini 僅使用了幾美分。
ARC-AGI 基準測試的創建者 François Chollet 在一篇 部落格 中寫道,與僅低 12% 分數的高效率版本 o3 相比,OpenAI 使用了大約 170 倍的計算資源來產生 88% 的分數。高分版本的 o3 使用了超過 10,000 美元的資源來完成測試,這使得它太過昂貴而無法參加 ARC Prize 競賽 — 一項讓 AI 模型擊敗 ARC 測試的未被擊敗的競賽。儘管如此,o3 對於 AI 模型來說仍然是一個突破。
Chollet 在部落格中表示:「o3 是一個能夠適應它以前從未遇到過的任務的系統,可以說在 ARC-AGI 領域接近人類水平的表現。」「當然,這種通用性是有代價的,並且還不夠經濟:你可以付錢給人類來解決 ARC-AGI 任務,每個任務大約 5 美元(我們知道,我們做過),而消耗的能源僅為幾美分。」

過分強調所有這些的確切定價還為時過早 — 我們已經看到 AI 模型的價格在去年暴跌,而 OpenAI 尚未宣布 o3 的實際成本是多少。但是,這些價格表明,即使只是略微突破當今領先 AI 模型設定的效能障礙,也需要多少計算資源。
這提出了一些問題。o3 實際上是為了什麼?為了在 o4、o5 或 OpenAI 將其下一個推理模型命名的任何名稱上圍繞推理獲得更多收益,需要多少額外的計算資源?
o3 或其後繼者似乎不會像 GPT-4o 或 Google 搜尋那樣成為任何人的「日常使用工具」。這些模型使用了太多的計算資源來回答你一天中的小問題,例如「克里夫蘭布朗隊如何才能進入 2024 年季後賽?」
相反,似乎具有擴展測試時計算的 AI 模型可能只適用於宏觀提示,例如「克里夫蘭布朗隊如何在 2027 年成為超級盃球隊?」即便如此,可能只有當你是克里夫蘭布朗隊的總經理,並且你正在使用這些工具做出一些重大決策時,才值得付出高昂的計算成本。
正如華頓商學院教授 Ethan Mollick 在一則 推文 中指出的那樣,擁有雄厚資金的機構可能是唯一能夠負擔得起 o3 的機構,至少在初期是這樣。
我們已經看到 OpenAI 發布了一個訂閱高達 200 美元 ChatGPT pro o1,但據報導 OpenAI 正在評估推出成本高達 2,000 美元的訂閱計劃。 當你看到 o3 使用了多少計算資源時,你就能理解為什麼 OpenAI 會考慮這樣做。

但是,將 o3 用於高影響力工作也有缺點。正如 Chollet 指出的那樣,o3 不是 AGI,它在人類可以輕鬆完成的一些非常簡單的任務上仍然會失敗。
這並不一定令人驚訝,因為大型語言模型 仍然存在巨大的幻覺問題,而 o3 和測試時計算似乎並未解決這個問題。這就是為什麼 ChatGPT 和 Gemini 在它們產生的每個答案下方都包含免責聲明,要求用戶不要完全相信答案。據推測,AGI 如果真的實現,將不需要這樣的免責聲明。
解鎖測試時擴展更多收益的一種方法可能是更好的 AI 推理晶片。不乏新創公司正在解決這個問題,例如 Groq 或 Cerebras,而其他新創公司正在設計更具成本效益的 AI 晶片。
雖然 o3 是 AI 模型效能的顯著改進,但它引發了有關使用和成本的幾個新問題。儘管如此,o3 的效能確實為測試時計算是科技產業擴展 AI 模型的下一個最佳途徑的主張增添了可信度。
Tenten 有一個以 AI 為主題的 Threads 帳戶!在此處追蹤
延伸閱讀
- 量子運算:超越傳統計算的未來科技
- 什麼是 AGI - 通用人工智慧 (Artificial General Intelligence)?
- OpenAI 推出革命性 o3 模型:開啟AI 新紀元
- Google AI 捲土重來!即將超越 OpenAI? AI 發展進入新階段
FAQ
1. OpenAI 的 o3 模型有什麼突破性改進?
o3 模型運用了「測試時擴展」的新概念,在推理階段使用更多計算資源,顯著提升效能。它在 ARC-AGI 測試中創下 88% 的高分,而其他模型的得分遠低於這一水平。
2. 測試時擴展是什麼意思?
測試時擴展是指 AI 模型在推理階段採用更多計算資源,比如運行更強大的晶片或延長晶片運行時間,以在生成答案時提升準確性和效能。
3. 為什麼 o3 模型的成本如此高?
o3 正是因為使用了額外的計算資源而取得顯著效能提升,但這也導致運行成本的激增。例如,在每個 ARC 測試任務上,o3 最佳版本的單次運行成本可能高達 10,000 美元。
4. 哪些使用者適合使用 o3 模型?
o3 模型目前更適合於高影響力的任務,例如企業決策或專業研究。由於其高昂的運行成本,一般用戶通常不適合日常使用該模型。
5. o3 模型是否實現了 AGI?
儘管 o3 在某些基準測試中靠近人類水準,但它距離真正的 AGI(通用人工智慧)仍有很大距離,並且仍存在幻覺問題以及在簡單任務上的失敗案例。






