
2026 年 3 月最後一週,AI 產業同時出了六件大事:Anthropic 因為 CMS 設定錯誤意外洩露了新一代旗艦模型 Claude Mythos(代號 Capybara),智譜 AI 推出 GLM-5.1 在編碼基準上逼近 Claude Opus 4.6 的 94.6%,Google DeepMind 發表 Gemini 3.1 Flash Live 即時語音模型,OpenAI 替 Codex 加上插件系統並同時宣布關閉 Sora 影片 App,ARC Prize 基金會發布 ARC-AGI-3 互動式基準測試讓所有前沿模型得分低於 1%,而 Cursor 的 Composer 2 被揭露底層其實是月之暗面的 Kimi K2.5。
這一週發生的事情,每一件單獨拿出來都能當頭條。放在一起看,輪廓更清楚:前沿模型能力正在快速拉開層級差距,開源模型的追趕速度超出多數人預期,而真正衡量智能的基準測試才剛開始跟上。
Anthropic Mythos 洩露:CMS 人為疏失曝光下一代旗艦模型
3 月 27 日,Fortune 報導 Anthropic 因為內容管理系統(CMS)的預設設定錯誤,讓將近 3,000 筆未發布的素材暴露在公開可搜尋的資料庫裡。其中包含一篇草稿部落格文章,內容描述了一個名為 Claude Mythos 的新模型,內部產品名稱為 Capybara。
需要澄清的是:多個 YouTube 影片聲稱 Mythos 是「10 兆參數模型」,但 Fortune、Techzine、The Decoder 等一手報導來源都沒有提到任何參數規模數字。Capybara 也不是「Mythos 之下的層級」。根據洩露文件和 Anthropic 的官方回應,Capybara 就是 Mythos 的產品層級名稱,兩者指的是同一個底層模型。
洩露的草稿指出,Capybara 是一個全新的模型層級(tier),位於現有 Opus 之上。原文寫道 Capybara 在軟體編碼、學術推理和網路安全等測試中,得分「遠高於」Claude Opus 4.6。Anthropic 發言人隨後向 Fortune 確認,這個模型代表了一個「階躍式變化」(step change),是「我們迄今建造過最強大的模型」。
幾個值得注意的細節:
第一,網路安全能力是重點。草稿明確提到這個模型「預示了即將到來的一波模型浪潮,能夠以遠超防禦者修補速度的方式利用漏洞」。Stifel 分析師 Adam Borg 在報告中寫道,Mythos「有潛力成為終極駭客工具,能將任何普通駭客提升到國家級對手的水準」。消息公布後,美國網路安全股隔天普遍下跌。
第二,運算成本極高。Anthropic 在草稿中承認這個模型「對我們來說運算成本非常高,對客戶來說也會非常昂貴」,目前僅提供給少數「早期存取客戶」測試。
第三,洩露本身的諷刺性。一家正在開發「具有前所未有網路安全風險」模型的公司,因為 CMS 的 human error 把模型公告留在公開資料庫裡。
Anthropic 把事件歸因為「內容管理系統設定中的人為錯誤」,並在 Fortune 聯繫後限制了公開存取。目前沒有確認的公開發布日期。
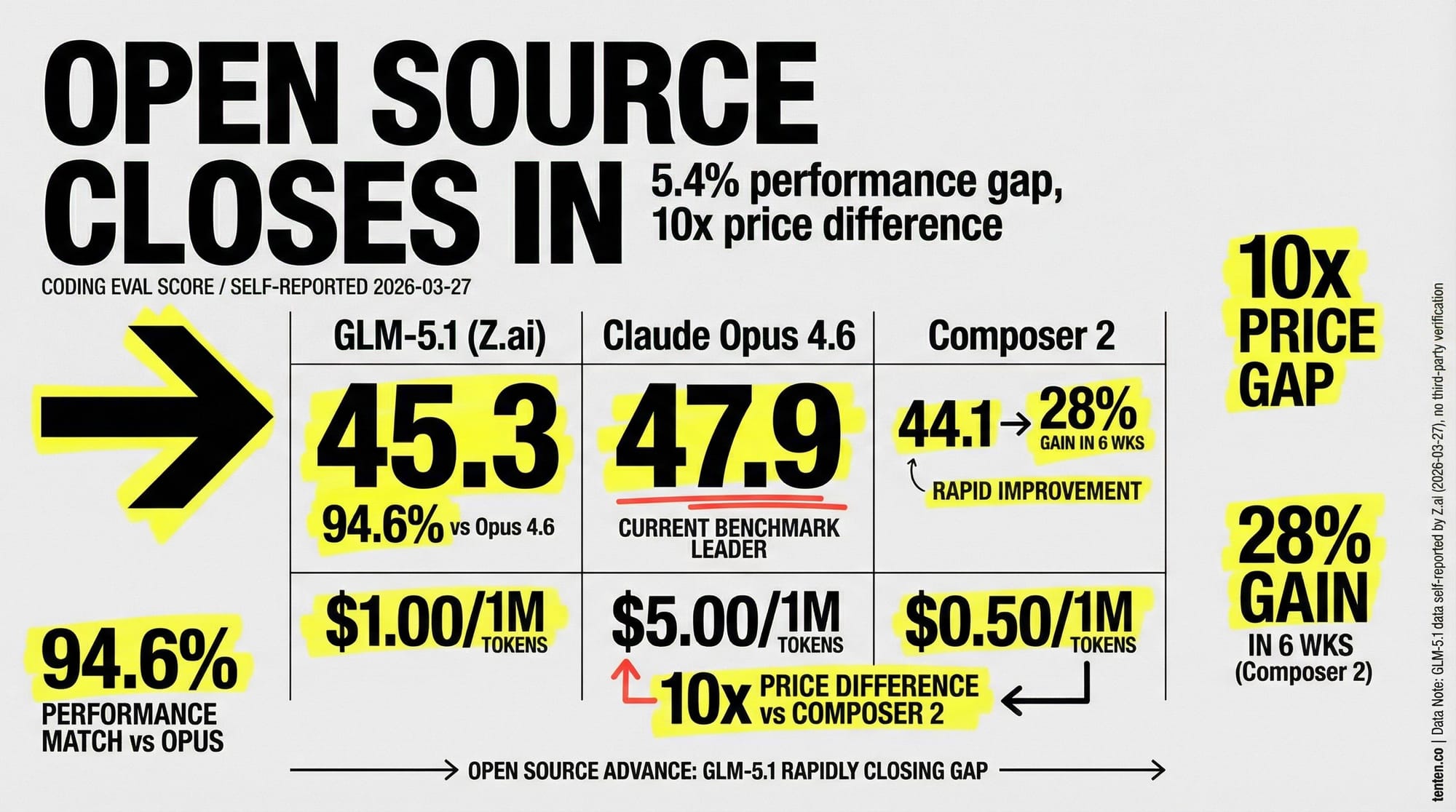
GLM-5.1:中國開源模型逼近前沿
同一天(3 月 27 日),智譜 AI(國際品牌 Z.ai)發布 GLM-5.1,在以 Claude Code 為測試框架的編碼評估中拿到 45.3 分,跟 Claude Opus 4.6 的 47.9 分只差 2.6 分,達到 Opus 性能的 94.6%。這比前代 GLM-5(35.4 分)提升了 28%,而 GLM-5 才在 2026 年 2 月 11 日發布。
| 指標 | GLM-5 | GLM-5.1 | Claude Opus 4.6 |
|---|---|---|---|
| 編碼評估(Claude Code 框架) | 35.4 | 45.3 | 47.9 |
| 與 Opus 的差距 | 26.1% | 5.4% | — |
| SWE-bench Verified | 77.8% | 未公布 | — |
| 總參數量 | 744B | 744B(同架構) | 未公開 |
| 活躍參數 | 40B | 40B | 未公開 |
| API 價格(輸入/百萬 tokens) | USD 1.00 | Coding Plan 起價 USD 3/月 | USD 5.00 |
幾個需要注意的點:第一,這些基準數字全部來自 Z.ai 自家文件,截至 3 月 27 日沒有第三方獨立驗證。第二,測試框架本身是 Claude Code,理論上對 Claude 模型有天然優勢,GLM-5.1 在這個框架下逼近 Opus 反而更說明問題。第三,整個 GLM-5 家族完全在華為昇騰 910B 晶片上訓練,沒有使用任何 NVIDIA 硬體。智譜 AI 自 2025 年 1 月起就在美國實體清單上。
對開發者來說,這代表 開源模型在編碼任務上的可用性門檻已經大幅降低。日常編碼場景裡 GLM-5.1 和 Opus 的差異已經很小,真正需要 Opus 的是 1M token 超長上下文、極端深度推理和複雜多步驟 Agent 工作流這些場景。
Gemini 3.1 Flash Live:即時語音 AI 的新基線
3 月 26 日,Google DeepMind 推出 Gemini 3.1 Flash Live,定位為「迄今最高品質的音訊和語音模型」。這個模型基於 Gemini 3 Pro,專門為建構即時語音和視覺 Agent 設計。
在 ComplexFuncBench Audio 基準測試中,3.1 Flash Live 拿到 90.8%,衡量的是多步驟函式呼叫的可靠性。在 Scale AI 的 Audio MultiChallenge 中,開啟思考模式後得分 36.1%,排名第一。Big Bench Audio 邏輯推理測試中,高思考模式得到 95.9%。
實際應用上,Verizon 和 The Home Depot 已經在測試用這個模型改善客戶互動。Search Live 從原本只在美國開放,擴展到超過 200 個國家和地區,支援 90 多種語言。所有 3.1 Flash Live 生成的音訊都嵌入 SynthID 浮水印,人耳聽不到但軟體可以偵測。
對開發者來說,Gemini Live API 現在可以在 Google AI Studio 中以預覽形式使用。支援多語言、工具呼叫、函式呼叫和長時間對話管理。
OpenAI Codex 插件:從編碼工具到工作平台
3 月 26 日,OpenAI 為 Codex 推出插件系統。插件是可安裝的套件,裡面打包了可重複使用的工作流、應用整合和 MCP 伺服器設定。
首批已有超過 20 個插件上線,包括 Slack、Figma、Notion、Gmail、Google Drive 和 Cloudflare 的整合。這些插件可以在 Codex App、CLI 和 IDE 擴充(包括 VS Code 和 JetBrains)中使用。
OpenAI 明確區分了 Skills 和 Plugins:Skills 是個人或專案專用的可重複提示,不適合分享;Plugins 是有版本號、可重複使用的套件,設計來跨團隊甚至公開分享。官方建議「從 Skills 開始做本地實驗,準備好分享時再打包成 Plugin」。
這個動作的背景是 Codex 正在快速成長。根據 OpenAI 公布的數據,過去一個月有超過 100 萬開發者使用 Codex,自 GPT-5.2-Codex 模型發布以來整體使用量翻倍。不過多個報導也指出,部分進階使用者已經轉向 Anthropic 的 Claude Code,偏好終端機優先的工作流和更長時間的 Agent 行為。
SiliconANGLE 的報導點出一個重點:OpenAI 的插件架構跟 Anthropic 在 Claude Code 中約五個月前推出的類似功能高度相似。三大主要 AI 編碼 Agent(Codex、Claude Code、Gemini CLI)現在都使用相同的架構來打包 MCP 伺服器、Skills 和應用整合。
Sora 正式關閉:AI 影片社群的短命實驗
3 月 24 日,OpenAI 宣布關閉 Sora App 和 API。App 預計 4 月 26 日下線,API 在 9 月 24 日停用。
Sora 2 在 2025 年 9 月推出後,24 小時內就衝上 App Store 照片與影片類別第一名。11 月下載量達到峰值約 333 萬次,但到 2026 年 2 月已經降到約 113 萬次。整個生命週期的應用內購買收入約 USD 210 萬(約 NTD 67,200,000)。
Disney 在 2025 年 12 月宣布投資 OpenAI 10 億美元並授權超過 200 個角色供 Sora 使用。隨著 Sora 關閉,Disney 也終止了這項合作。Disney 發言人表示:「我們尊重 OpenAI 退出影片生成業務並將優先順序轉移到其他地方的決定。」
OpenAI 把關閉歸因於運算資源的取捨。Sora 團隊負責人 Bill Peebles 去年 11 月就說過公司的 GPU「快燒起來了」。在準備可能的 IPO 之際,OpenAI 正在將資源從消費者產品轉向企業客戶服務和下一代模型(內部代號 Spud)的開發。
ARC-AGI-3:重新定義智能測量的基準
3 月 25 日,ARC Prize 基金會在 Y Combinator 總部舉辦發表會,由 François Chollet(ARC-AGI 創造者)和 Sam Altman(OpenAI CEO)進行爐邊對話,正式發布 ARC-AGI-3。
跟前兩代的靜態視覺拼圖不同,ARC-AGI-3 是完全互動式的。Agent 被丟進一個陌生的回合制環境中,沒有任何指示、沒有規則描述、沒有目標說明。它必須自己探索環境、搞清楚規則、推斷出贏的條件,然後制定策略執行。
| 版本 | 格式 | 前沿模型最佳分數 | 人類分數 |
|---|---|---|---|
| ARC-AGI-1(2019) | 靜態拼圖 | 98%(Gemini 3.1 Pro) | ~100% |
| ARC-AGI-2(2025) | 更難的組合式拼圖 | 84.6%(Gemini 3 Deep Think) | ~100% |
| ARC-AGI-3(2026) | 互動式遊戲環境 | 0.37%(Gemini 3.1 Pro) | 100% |
其他前沿 LLM 的表現:GPT-5.4 得 0.26%,Claude Opus 4.6 得 0.25%,xAI 的 Grok-4.20 得 0%。預覽階段表現最好的不是大型語言模型,而是一個簡單的 RL 加圖搜尋系統,得了 12.58%。
計分方式也不是簡單的對錯。ARC-AGI-3 使用 RHAE(Relative Human Action Efficiency)指標,衡量 AI 完成每個關卡所需的動作數量跟第二好的人類首次嘗試相比的效率。二次懲罰意味著效率差距會快速放大:一個花 3 倍人類動作的 Agent 只能得 11%,不是 33%。
ARC Prize 2026 提供超過 200 萬美元的獎金,其中 ARC-AGI-3 賽道的大獎是 70 萬美元,頒給第一個得到 100% 的 Agent。所有參賽者必須在寬鬆授權(MIT 或 CC0)下開源他們的方案。
Cursor Composer 2 爭議:底層模型不是自研的
Cursor 在 3 月中旬發布 Composer 2,宣稱是「前沿等級」的編碼模型。但一位開發者在檢查 Cursor 的 API 設定時,發現了一個內部模型路徑:kimi-k2p5-rl-0317-s515-fast。
需要更正的是:多個 YouTube 影片聲稱 Composer 2 的底層是 Qwen 2.5。這是錯誤的。實際的底層模型是月之暗面(Moonshot AI)的 Kimi K2.5,一個擁有 1 兆參數的 MoE 架構,每次推理啟用 320 億參數,支援 256,000 token 上下文窗口。
Cursor 的 VP Lee Robinson 在幾小時內確認了 Kimi 的連結,共同創辦人 Aman Sanger 承認一開始沒有披露底層模型是個錯誤。根據 Lee Robinson 的說法,大約四分之一的預訓練來自 Kimi K2.5 底層模型,Cursor 負責剩下的微調和繼續訓練。
| 模型 | CursorBench | Terminal-Bench 2.0 | SWE-bench Multilingual |
|---|---|---|---|
| Composer 1 | 38.0 | — | — |
| Composer 1.5 | 44.2 | — | 65.9 |
| Composer 2 | 61.3 | 61.7 | 73.7 |
| Claude Opus 4.6 | — | 58.0 | — |
Composer 2 在 Terminal-Bench 2.0 上超越了 Claude Opus 4.6(61.7 vs 58.0),定價也大幅低於 Anthropic:Composer 2 Standard 輸入 USD 0.50/百萬 tokens,Opus 4.6 是 USD 5.00/百萬 tokens,差了 10 倍。
不過月之暗面公開指控 Cursor 違反授權條款。Kimi K2.5 的授權是附帶署名要求的修改版 MIT 授權,月之暗面認為 Cursor 在商業化使用時沒有滿足這些要求。截至 3 月 22 日,Cursor 尚未對此發出正式回應。
對一家估值 USD 293 億、每天有 100 萬開發者使用的美國 AI 編碼新創來說,旗艦編碼模型建立在中國智慧財產權上,又有未解決的授權爭議——這種情況在中美 AI 供應鏈審查日益嚴格的背景下格外敏感。

本週其他更新
Claude Code 推出了 Auto Mode,取消了持續的權限提示,改用內建分類器在每個動作上做審查:安全動作即時執行,高風險動作會被阻擋。另外也推出了 Cloud Autofix,在雲端自動修復 CI 失敗和處理 PR 審查意見。不過目前尖峰時段有 5 小時 session 上限的臨時限制。
Anthropic 正在為 Claude Desktop 開發代號 Operon 的科學研究專用 Agent,初期聚焦生物學領域,提供獨立環境讓科學家跟 AI 協作、管理多個研究 session。
Mistral AI 發布了 Mistral TTS,一個開放權重的文字轉語音模型,支援 9 種語言和多種方言,強調情感表達和低延遲。
ElevenLabs 的 CLI 更新為 Agent-first 設計,預設為非互動模式,方便 Agent 和自動化工作流直接使用。
這週發生的事跟 AI 開發者有什麼關係?
這週的事件對開發者的實際影響集中在三個層面。模型選擇上,GLM-5.1 在日常編碼場景中已經是 Opus 的可用替代品,價格只有十分之一;Composer 2 的爭議也提醒我們,產品背後的模型來源比行銷話術更重要。工具生態上,Codex 的插件系統跟 Claude Code 的 Skills/Plugins 架構趨同,意味著跨工具遷移的摩擦力在降低。能力評估上,ARC-AGI-3 證明目前的 LLM 在真正的互動式推理上還有巨大缺口,這跟企業導入 AI Agent 時的期望管理直接相關。
Anthropic Mythos 什麼時候會正式發布?
截至 2026 年 3 月 29 日,沒有確認的公開發布日期。Anthropic 表示會「從小規模早期存取客戶開始,逐步擴展 API 存取」。洩露文件也承認這個模型目前運算成本太高,需要在效率優化後才能做一般性發布。
ARC-AGI-3 跟之前的版本差在哪?
ARC-AGI-1 和 ARC-AGI-2 是靜態拼圖:給一個輸入/輸出模式,預測下一個。ARC-AGI-3 是互動式遊戲環境:Agent 被丟進陌生世界,沒有任何指示,必須自己探索、建立世界模型、推斷目標、制定策略。前兩代最好的 AI 已經接近飽和(ARC-AGI-1 上 Gemini 3.1 Pro 得 98%),但 ARC-AGI-3 把前沿模型打回 1% 以下。
Sora 關閉後 AI 影片生成還有什麼選擇?
Sora 關閉後,Google 的 Veo 系列成為目前唯一有規模的 AI 影片生成平台。其他選項包括 Runway Gen-3、Minimax、Kling 等,但在 IP 授權和企業合作方面都不如 Sora 曾經達到的程度(Disney 的 10 億美元合作案已終止)。
Cursor Composer 2 到底是不是 Qwen 2.5?
不是。多個 YouTube 影片和自媒體錯誤地聲稱 Composer 2 的底層是 Qwen 2.5。實際上它是基於月之暗面(Moonshot AI)的 Kimi K2.5,這已經由 Cursor 的 VP Lee Robinson 和共同創辦人 Aman Sanger 確認。Kimi K2.5 是一個 1 兆參數的 MoE 模型,跟阿里巴巴的 Qwen 系列完全不同。
GLM-5.1 真的可以替代 Claude Opus 4.6 嗎?
在日常編碼任務上,差距已經很小(45.3 vs 47.9)。但 Opus 在三個場景仍有明確優勢:1M token 超長上下文處理、極端深度的推理鏈、以及複雜的多步驟 Agent 工作流。Z.ai 的官方建議是「日常用 GLM,重活用 Opus」。另外,GLM-5.1 的基準數字目前全部是自報的,沒有第三方獨立驗證。
引用來源
- Fortune — Anthropic 'Mythos' AI model representing 'step change' in power revealed in data leak
- Google DeepMind Blog — Build real-time conversational agents with Gemini 3.1 Flash Live
Insights
從 Cursor 到 Claude Code 再到完整的 Agentic Coding 工作流。這週 Mythos 洩露讓我在意的不是模型本身有多強(還沒人真的測過),而是 Anthropic 對網路安全風險的措辭。一家 AI 公司公開說自己的模型可能「遠超防禦者修補速度」地利用漏洞,這在產業裡是第一次。這代表前沿模型的能力已經到了連開發者自己都要認真考慮雙重用途風險的程度。
如果你的團隊正在評估該用 Claude Code、Codex 還是開源方案來建構 AI 輔助開發工作流,我們協助多家企業做過這類技術架構決策。歡迎跟 Tenten 團隊預約諮詢。










