TL;DR
Anthropic 正式推出 Claude Opus 4.5,這款 AI 編碼模型在程式設計基準測試中奪得冠軍寶座。最令人振奮的消息是價格調降至原本的三分之一,僅需每百萬輸入代幣 5 美元、輸出代幣 25 美元。新版本不僅在軟體工程領域表現卓越,更引入智慧化的 effort 參數,讓開發者能在速度與效能之間靈活調配。實測顯示,Opus 4.5 中等努力模式的表現就能媲美 Sonnet 4.5 頂尖水準,卻能節省高達 76% 的代幣消耗量。

Claude Opus 4.5 橫空出世:AI 編碼領域的新霸主
在人工智慧模型競賽白熱化的當下,Anthropic 再次證明其技術實力。全新發表的 Claude Opus 4.5 不僅在編碼能力上創下新高,更以破壞性的價格策略重新定義市場格局。這次發布最引人注目的亮點,無疑是價格大幅調降:每百萬輸入代幣從過往的 15 美元降至 5 美元,輸出代幣則從 75 美元降至 25 美元,整體成本直接砍掉三分之二。
這樣的價格革命意味著 Opus 4.5 將從「只在關鍵任務使用」的高端選項,轉變為開發者日常作業的首選工具。對於企業組織而言,這不僅代表顯著的成本節省,更開啟了大規模應用 AI 編碼助手的可能性。
實戰測試:從 Minecraft 到 Lego 建構器的驚艷表現
為了驗證 Opus 4.5 的實際編碼能力,測試人員進行了多項極具挑戰性的單一提示實驗。首先是 Minecraft 遊戲克隆測試,這個測試也曾用於評估 Gemini 3 Pro 的表現。結果顯示,Opus 4.5 生成的遊戲版本流暢度極佳,玩家可以自由移動、破壞方塊、放置建材,甚至擁有完整的方塊選擇器和飛行功能。更令人驚喜的是,系統還自動加入了晝夜循環機制,整體遊戲體驗完全可以正常遊玩。
相較之下,Gemini 3 Pro 雖然也能生成程序化世界,但在互動性和流暢度上明顯遜色——玩家無法破壞或放置方塊,移動機制也較為混亂。這個對比測試充分展現了 Opus 4.5 在複雜專案生成上的優勢。
另一項測試則是創建 Lego 建構器網站,要求系統整合 Three.js 3D 圖形庫。Opus 4.5 一次性生成了功能完整的應用程式:使用者可以旋轉視角、堆疊積木、更換顏色、切換移除模式,並選擇不同的 Lego 零件類型。這種複雜的 3D 互動應用能夠透過單一提示就完成開發,充分證明 AI 編碼模型已經發展到令人驚嘆的成熟度。
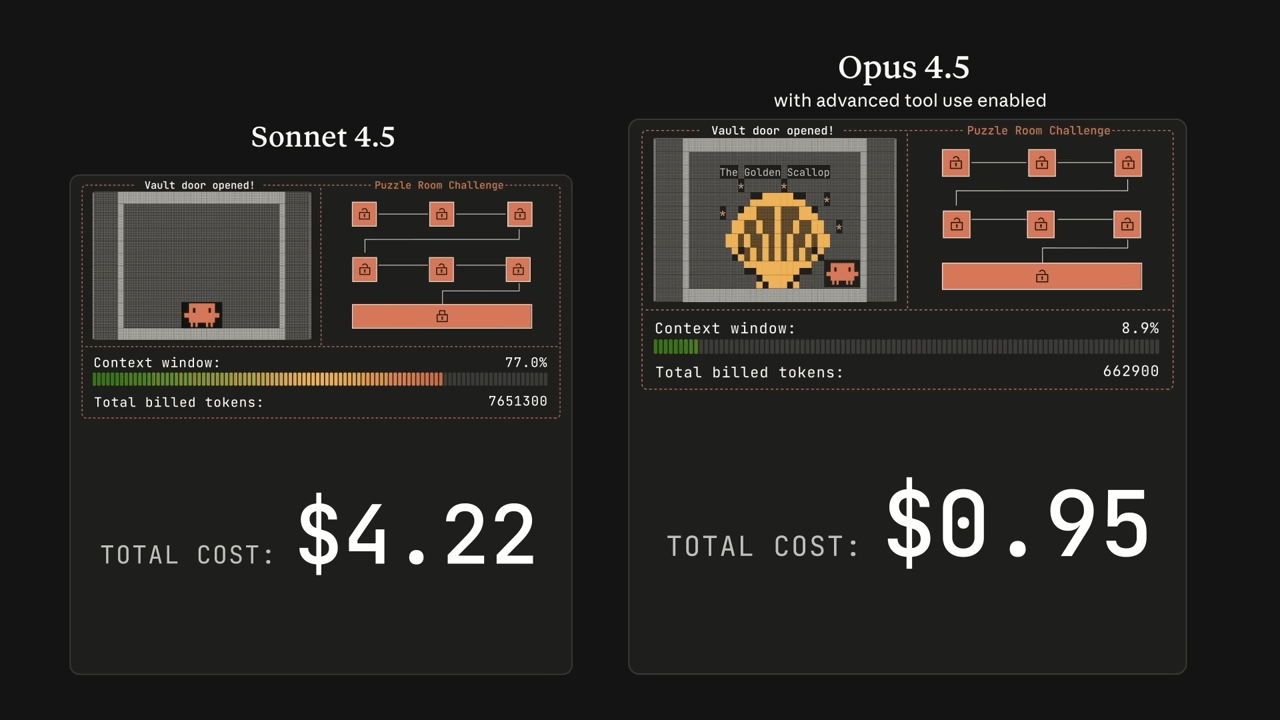
代幣效率革命:用更少資源達成更好成果
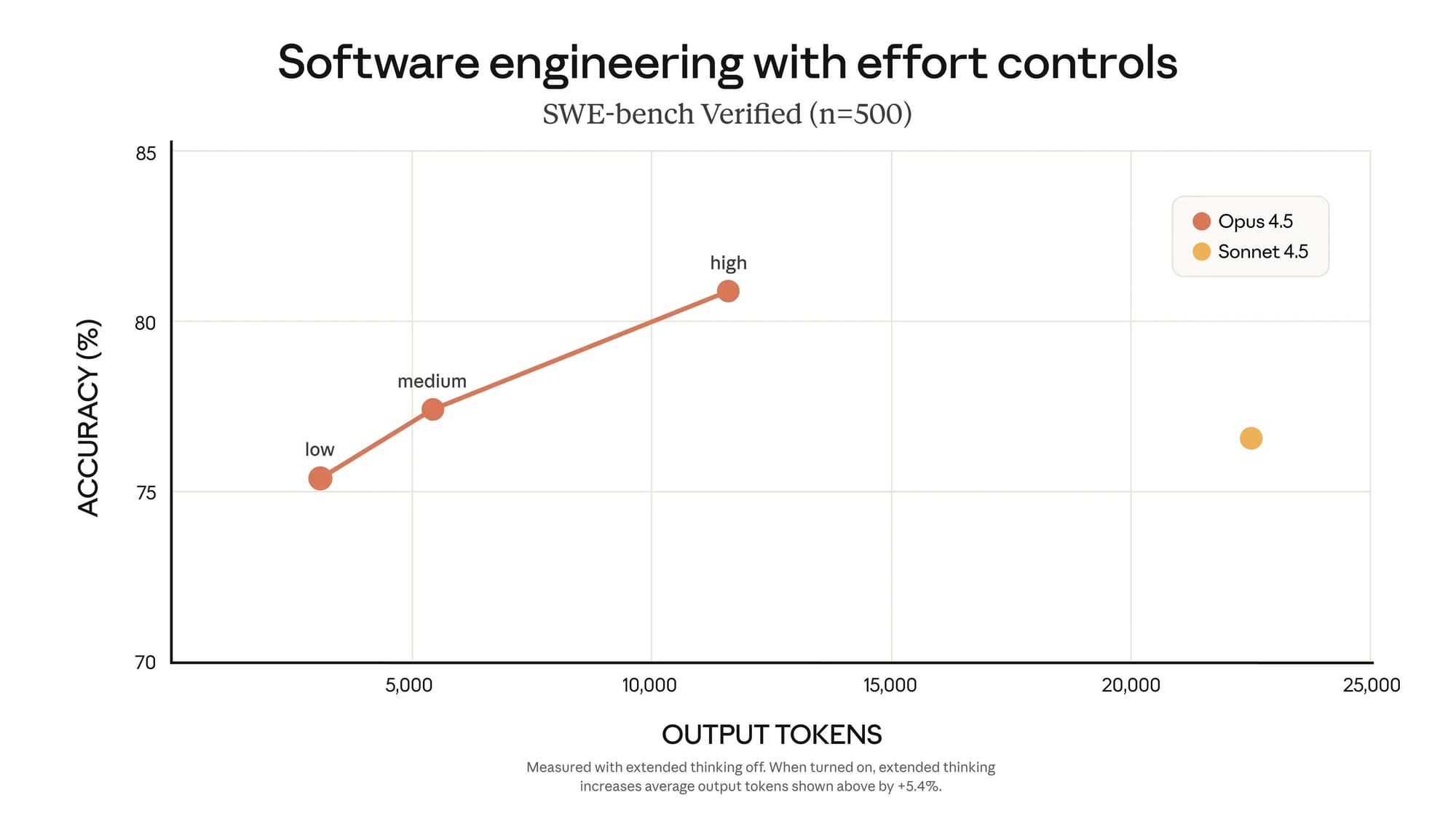
Opus 4.5 最具革命性的特點之一,是其卓越的代幣使用效率。相較於前代模型,新版本能以大幅減少的代幣消耗達到相同甚至更優的輸出品質。這項突破配合全新的 effort 參數功能,讓使用者能根據實際需求在速度、成本與能力之間進行精準調控。
實驗數據揭示了驚人的效率提升:Opus 4.5 在中等努力設定下,能夠匹敵 Sonnet 4.5 的最佳 SWE-Bench Verified 分數,同時節省 76% 的輸出代幣。即使將努力級別調至最高,Opus 4.5 不僅超越 Sonnet 4.5 的表現,還能減少 48% 的代幣使用量。當這些效率優勢與三倍價格降幅相結合,對開發者和企業而言,Opus 4.5 無疑成為極具吸引力的日常工作夥伴。
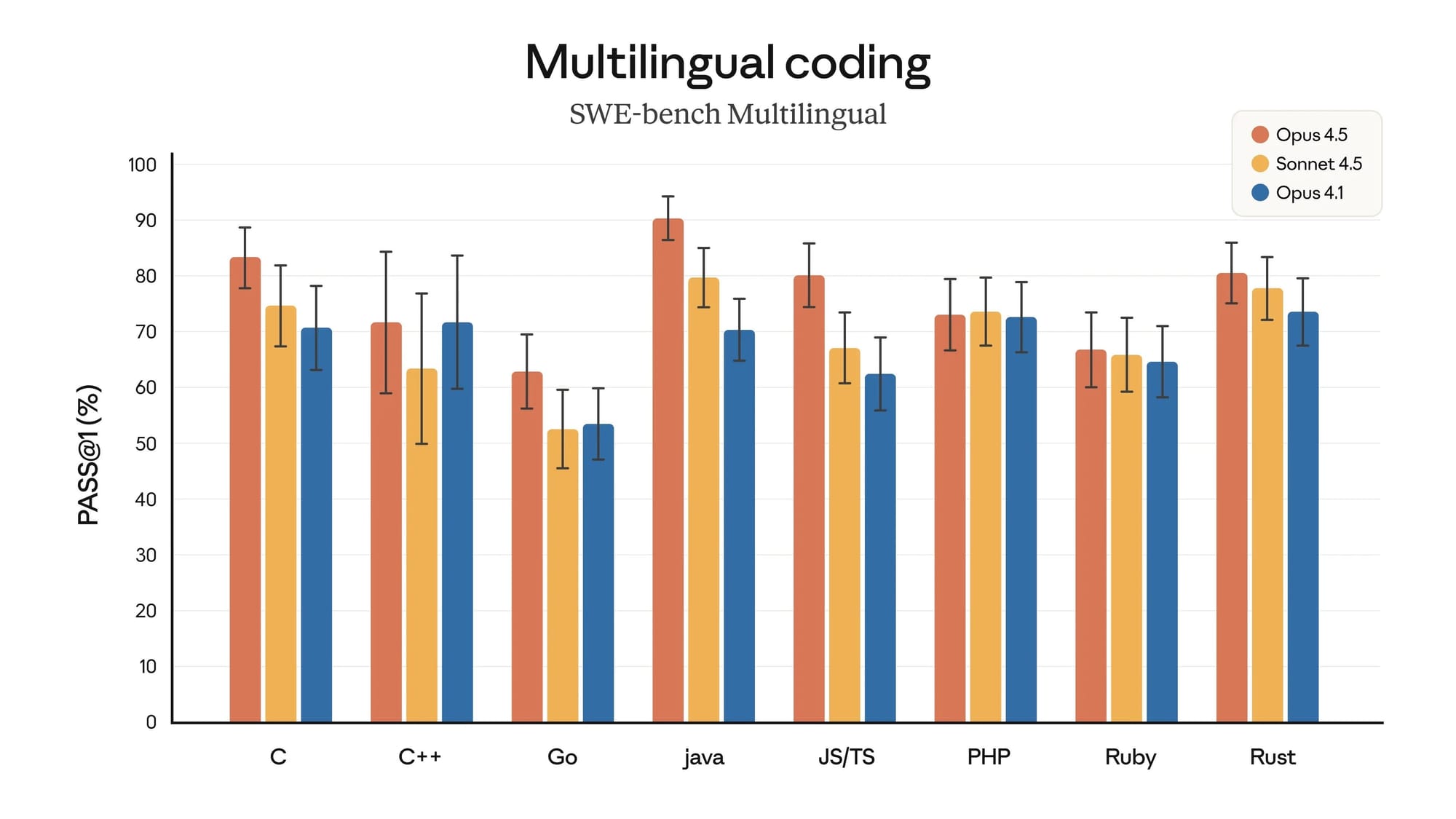
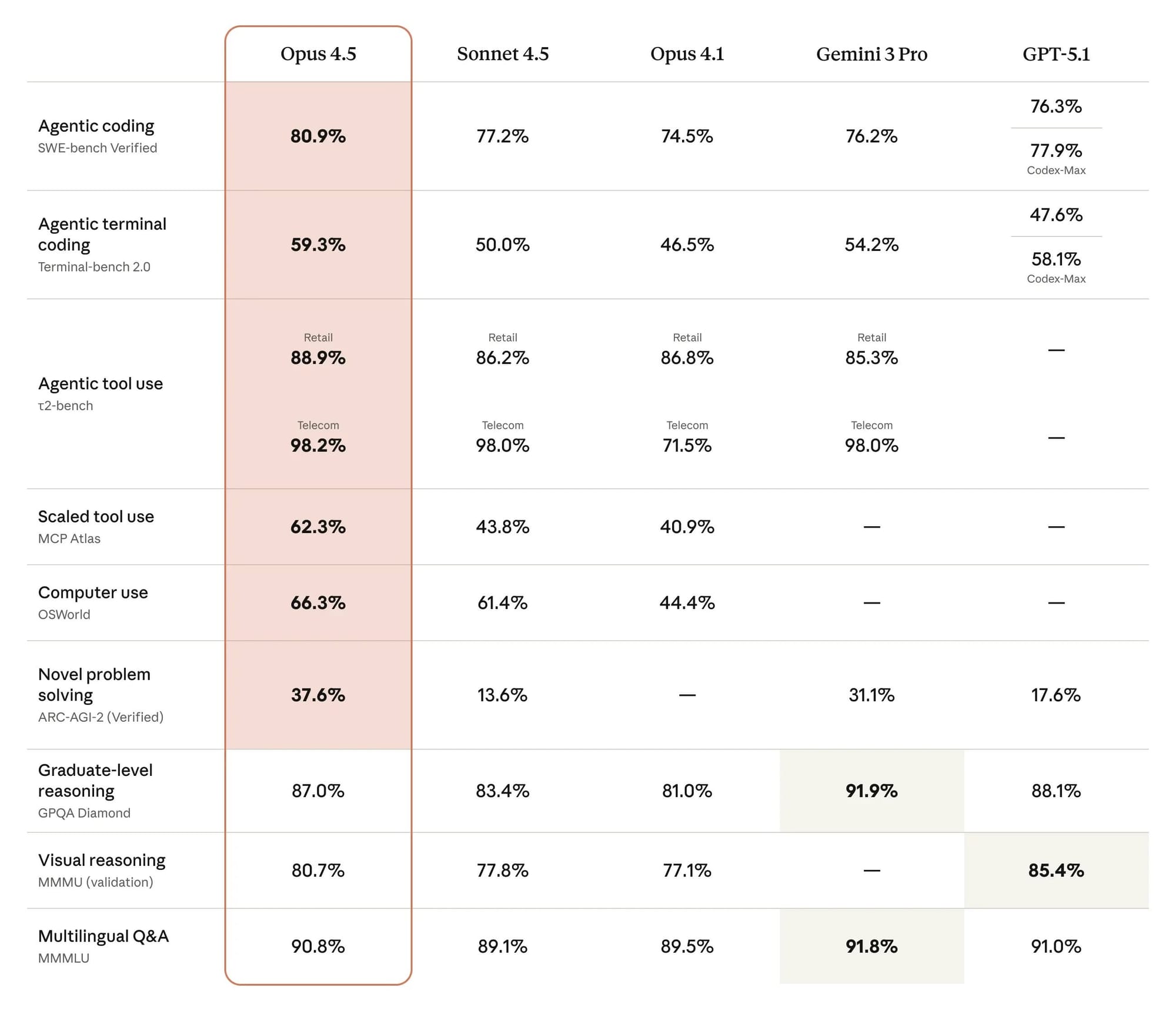
基準測試全面制霸:軟體工程領域的王者
在各項業界標準基準測試中,Claude Opus 4.5 展現了全方位的領先優勢。特別是在軟體工程領域,它擊敗包括 GPT-5.1 Codex Max 在內的所有競爭對手,穩坐冠軍寶座。
| 基準測試項目 | Claude Opus 4.5 表現 | 競爭對手比較 |
|---|---|---|
| 軟體工程 (SWE-Bench) | 第一名 | 擊敗 GPT-5.1 Codex Max |
| Arc AGI 基準測試 | 第二名 | 僅次於 Gemini 3 Pro Deep Think |
| 研究生等級推理 | 頂尖表現 | 略遜於部分競品 |
| 視覺推理 | 優異表現 | 非首位但表現強勁 |
| 多語言問答 | 高水準輸出 | 接近領先群組 |
更有趣的是,Anthropic 團隊用自家公司的員工招募考試來測試 Opus 4.5。結果這個 AI 模型的得分超越了所有曾經應試的人類候選人,創下歷史新高。這個結果雖然帶有一絲幽默,卻也真實反映了 AI 在特定技術任務上已經超越人類專家的現實。
在 Arc AGI 基準測試中,Opus 4.5 排名第二,僅以些微差距落後於 Gemini 3 Pro 的深度思考模式。相較於前代 Opus 4.1,新版本在這項測試上有著顯著飛躍。綜觀整個基準測試套件,Opus 4.5 在絕大多數項目中都取得領先,只在研究生等級推理、視覺推理和多語言問答三個領域些微落後。
值得注意的是,在 UI 生成的特殊基準測試中,Gemini 3 Pro 仍然保持微幅領先——顯然在優化販賣機營收這個特定任務上,Google 的模型還佔有一點優勢。但整體而言,這些細微差異並不影響 Opus 4.5 在編碼領域的霸主地位。

Effort 參數:客製化你的 AI 編碼體驗
Opus 4.5 引入的 effort 參數為使用者帶來前所未有的彈性。這個創新功能讓開發者能根據專案需求,在處理時間、成本支出和輸出品質之間找到最佳平衡點。
當設定為低努力模式時,模型會優先考慮速度和成本效益,適合用於快速原型開發或簡單任務。中等努力模式則在效能和效率間取得平衡,足以應對大多數日常開發工作。高努力模式則啟動模型的全部潛能,適合處理複雜架構設計或關鍵系統開發。
這種分級機制的設計哲學,讓 Opus 4.5 不再是「一刀切」的工具,而是能夠隨著不同情境靈活變化的智慧助手。對於需要嚴格控制預算的新創公司,或是追求極致效能的大型企業,都能找到最適合自己的使用方式。
價格破壞者:重新定義 AI 模型的市場定位
傳統上,Opus 系列一直被定位為「重要任務專用」的高階模型——開發者會在遇到特別困難的問題時才呼叫它,平常則使用成本較低的替代方案。但 Opus 4.5 的價格策略徹底改變了這個格局。
每百萬輸入代幣 5 美元的定價,讓它進入了「日常使用」的價格區間。對於一個中型開發專案而言,原本可能需要數百美元的 API 調用成本,現在可以壓縮到數十美元。這不僅降低了技術門檻,也讓更多開發者願意將 AI 編碼助手整合進持續集成/持續部署(CI/CD)流程。
對企業組織來說,這個價格點更具戰略意義。它意味著可以讓整個開發團隊全面採用 AI 輔助編碼,而不必擔心預算爆炸。從程式碼審查、單元測試生成到技術文件撰寫,所有環節都能引入 AI 協助,整體生產力提升將是質的飛躍。

未來展望:AI 編碼模型的下一個里程碑
Opus 4.5 的發布標誌著 AI 輔助編程進入新的成熟階段。從單一提示就能生成複雜的 3D 互動應用,到在標準化測試中超越人類專家,這些成就不僅是技術進步的展現,更預示著軟體開發範式的根本轉變。
然而,這也引發了值得深思的問題:當 AI 在標準化編碼測試中超越所有人類候選人時,我們是否正在見證一個轉折點?未來的軟體工程師角色會如何演變?是否會從「編寫程式碼」轉向「指導 AI 編寫程式碼」?
目前來看,Opus 4.5 展現的能力更像是一個強大的工具,而非替代品。它能快速生成基礎框架和實現常見功能,但複雜的架構決策、商業邏輯設計和創新性解決方案,仍然需要人類開發者的專業判斷。最理想的協作模式,或許是人機協同——讓 AI 處理繁瑣的實現細節,讓開發者專注於更高層次的創造性工作。
實用建議:如何最大化 Opus 4.5 的價值
對於考慮採用 Opus 4.5 的開發者和團隊,以下是幾個實用建議:
評估你的使用場景:如果主要工作涉及程式碼生成、重構或除錯,Opus 4.5 的編碼專長將帶來最大效益。對於需要多語言處理或視覺推理的專案,可能需要搭配其他模型使用。
善用 effort 參數:不是所有任務都需要最高努力級別。開發初期的快速原型可以用低努力模式節省成本,關鍵模組的實現再切換到高努力模式確保品質。
建立評估機制:追蹤每個專案的代幣使用量和輸出品質,找出最適合你團隊工作流程的配置。這些數據將幫助你在未來做出更明智的決策。
漸進式導入:先從非關鍵路徑的任務開始使用,累積經驗後再擴展到核心開發流程。這能降低風險,也讓團隊有時間適應新的工作方式。
參考資料與延伸閱讀
關於作者
Ewan 是一位資深技術作家,專注於人工智慧、機器學習和開發者工具領域。擁有超過十年的軟體工程經驗,曾參與多個大型 AI 專案的架構設計與實施。
作者觀點:
Opus 4.5 的發布讓我感到既興奮又深思。興奮的是,我們終於看到 AI 編碼助手達到了「可以日常依賴」的成熟度,而不再只是偶爾試用的新奇玩具。三倍的價格降幅更是實質性的突破,這意味著中小型團隊也能負擔得起頂級 AI 工具,技術民主化又向前邁進一大步。
但同時,當我看到 Opus 在招募考試中超越所有人類候選人時,也不禁思考:我們正在培養的下一代開發者,需要具備什麼樣的核心競爭力?純粹的編碼技巧可能不再是關鍵,理解業務需求、做出權衡決策、以及有效地與 AI 協作,這些能力或許會變得更加重要。
從實際使用角度來看,我建議團隊不要陷入「AI 萬能論」或「AI 威脅論」的兩極化思維。Opus 4.5 是個強大的工具,但它最大的價值在於如何被善用。建立合適的工作流程、培養正確的使用習慣,並保持對輸出品質的審查機制,這些才是確保 AI 真正提升生產力的關鍵。我相信,人機協同的未來已經到來,而 Opus 4.5 正是這個新時代的重要里程碑。