
Claude Opus 4.5 是 Anthropic 最新一代旗艦模型,主打更強的程式能力、推理深度與 AI Agent 自動化,目前已經在官方 App、API 與多家雲端平台全面上線。社群普遍把它視為現在最強的「寫程式+電腦操作」模型之一,同時也在討論它的性價比、和其他模型(像 GPT、Gemini)之間的差異。
作為一位長期追蹤 AI 發展的觀察者,我認為 Opus 4.5 的推出標誌著 AI 模型正式進入「實戰應用」階段。過去我們談論的都是模型能力有多強,現在討論的是如何真正把這些能力轉化成可以穩定運作的商業價值。這個轉變對企業來說意義重大,因為這代表 AI 終於可以從「實驗室玩具」變成「生產力工具」。
快速掌握 Claude Opus 4.5 的核心特色
如果你只想知道「值不值得用」,抓住這幾點就夠:
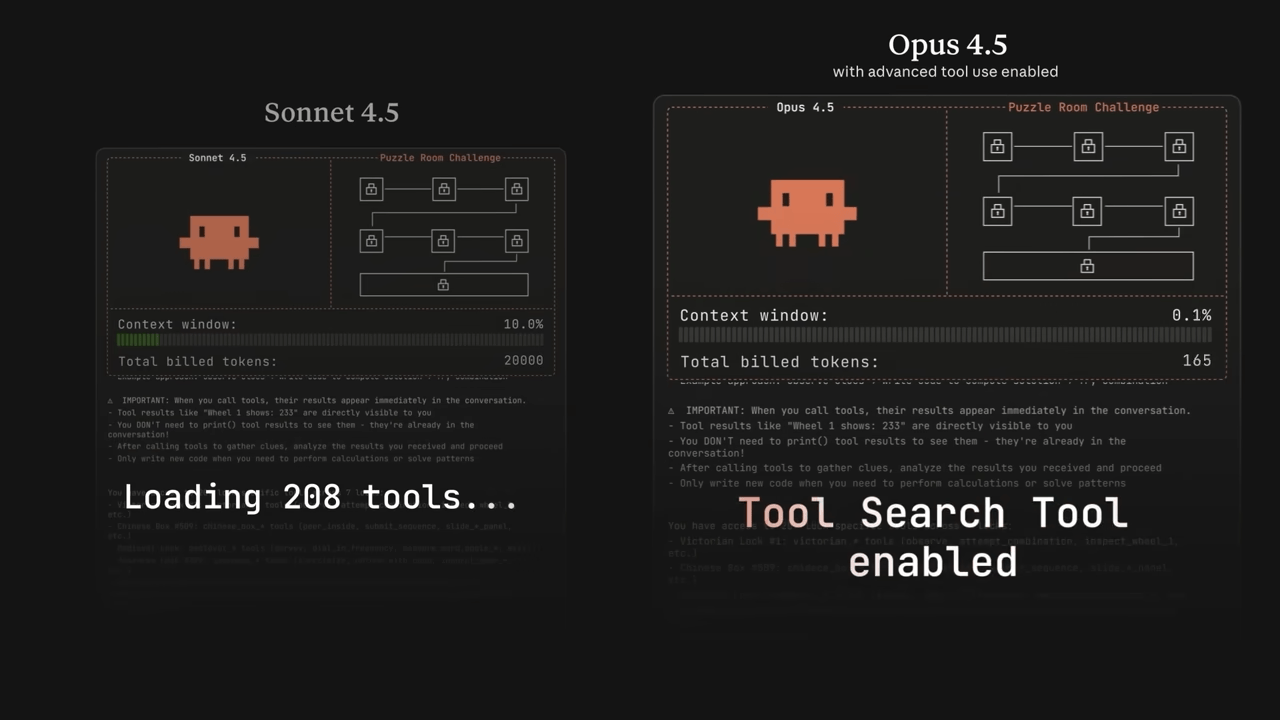
Claude Opus 4.5 是主打「全球最強 coding & agent 模型」的新旗艦,特別針對真實軟體工程、長時間自動化任務做優化。根據官方數據顯示,它在困難的軟體工程測試上打敗人類應徵者,還能在 30 分鐘以上的自動 coding session 中維持穩定品質。
這個模型新增了 effort 參數,讓使用者可以控制「想得多一點還是省 token 一點」,同一個模型就能在深度分析與大量自動化之間切換。這種彈性設計在實務上非常實用,特別是當你需要在成本與品質之間找平衡點的時候。
電腦使用能力也有顯著加強:支援螢幕「放大檢視」、多步驟操作,適合讓它幫你操控瀏覽器、處理 office 工作、改 Excel、做簡報等重複性任務。我自己測試過讓它處理一些資料整理工作,確實比之前的版本更可靠,不會因為看不清楚小字就出錯。
價格變得比舊 Opus 便宜:API 約是每百萬輸入 5 美金、輸出 25 美金,等於把旗艦等級拉到更多團隊也負擔得起的區間。如果你正在規劃實戰型 AI Agent(例如自動跟進客戶、營運助理),這種長鏈推理+工具操作強的模型,剛好就是那種「當 Agent 大腦」的理想人選。
Claude Opus 4.5 在 Artificial Analysis 智能指數排名第二,緊追 Google Gemini 3
在 AI 模型競賽白熱化的今天,每一次新模型的發布都會引發業界的高度關注。Anthropic 最新推出的 Claude Opus 4.5 在編碼和智能體任務的基準測試中取得優異成績,如今更在 Artificial Analysis 智能指數中穩居亞軍位置。
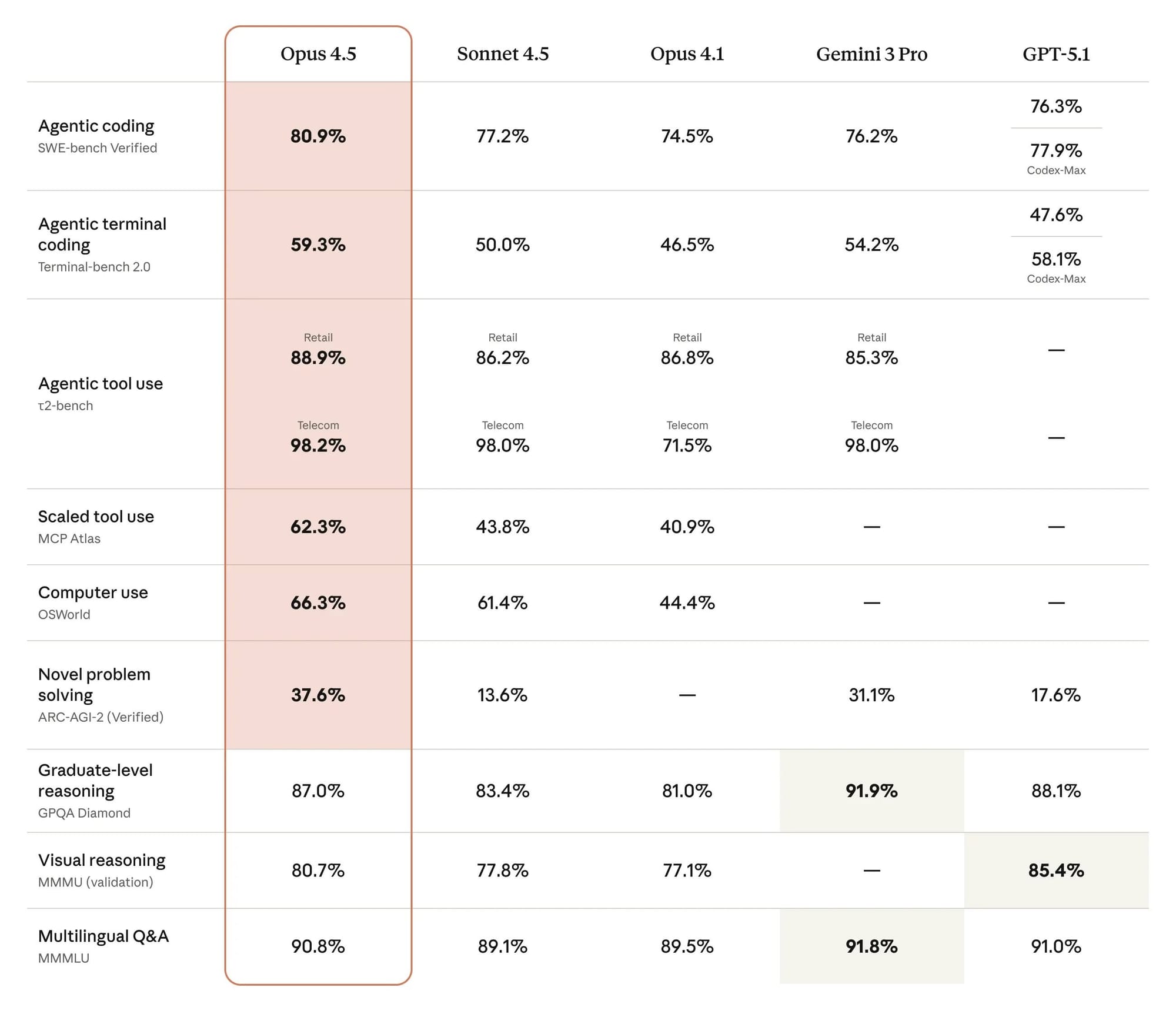
Claude Opus 4.5 以 70 分的成績與 OpenAI 的 GPT-5.1 (high) 並列第二,僅次於 Google Gemini 3 Pro 的 73 分領先地位。這次發布標誌著 Anthropic 模型家族的重大智能升級——相較於 Claude Sonnet 4.5 提升了 7 分,相較於前代 Claude Opus 4.1 更是躍升了 11 分,為公司產品線樹立了新的性能標竿。
定價策略的大幅調整重塑成本結構
Anthropic 在定價模式上進行了大幅度的調整,將每個 token 的成本削減了約三分之二。Claude Opus 4.5 的定價為每百萬輸入 token 5 美元,每百萬輸出 token 25 美元,相較於 Claude Opus 4.1 的 15/75 美元大幅降低。這使得新模型的價格更接近中階的 Claude Sonnet 4.5(每百萬 token 3/15 美元),同時在思考模式下提供了更高的智能表現。
然而,單純的價格降幅並未完整呈現實際情況。在完成 Artificial Analysis 的智能指數評測時,Claude Opus 4.5 消耗的 token 數量比 Claude 4.1 Opus 多出約 60%——4800 萬 token 對比 3000 萬 token。這意味著運行這些評測的實際成本從 3,100 美元降至 1,500 美元,雖然降幅顯著,但不如單純的 token 定價所暗示的那麼戲劇性。
儘管如此,Claude Opus 4.5 在大規模運營時仍屬於較昂貴的模型之一,運行智能指數的成本高於 Gemini 3 Pro (high)、GPT-5.1 (high) 和 Claude Sonnet 4.5 (Thinking),但在成本效益上略勝於 Grok 4 (Reasoning)。
| 模型 | 輸入價格 (每百萬 token) | 輸出價格 (每百萬 token) | 智能指數分數 | 評測成本 |
|---|---|---|---|---|
| Claude Opus 4.5 | $5 | $25 | 70 | $1,500 |
| Claude Opus 4.1 | $15 | $75 | 59 | $3,100 |
| Claude Sonnet 4.5 | $3 | $15 | 63 | - |
| Gemini 3 Pro | - | - | 73 | 低於 Claude Opus 4.5 |
| GPT-5.1 (high) | - | - | 70 | 低於 Claude Opus 4.5 |
Token 效率成為競爭優勢
Claude 模型系列的一個關鍵差異化優勢在於,它們比所有其他推理模型的 token 效率都要高得多。Claude Opus 4.5 在大幅提升智能表現的同時,並未顯著增加輸出 token 的使用量,這與其他依賴於推理時產生更多輸出 token 的模型家族有著本質上的不同。
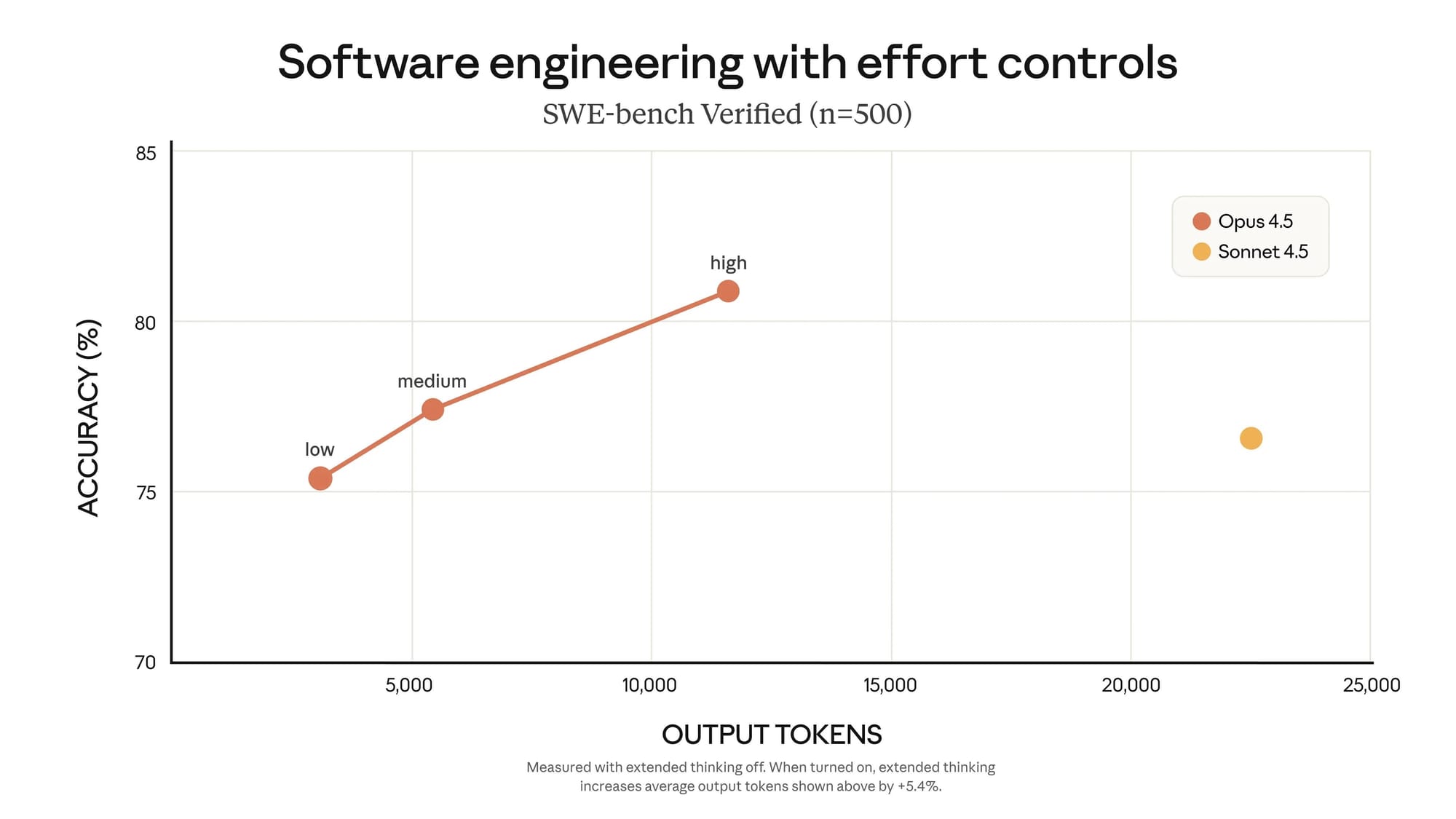
在 Artificial Analysis 智能指數的輸出 token 使用量與智能指數的對比圖表中,Claude Opus 4.5 (Thinking) 位於帕累托前沿線上。該模型使用了 4800 萬輸出 token 完成智能指數評測——遠少於 Gemini 3 Pro (high) 的 9200 萬、GPT-5.1 (high) 的 8100 萬,以及 Grok 4 (Reasoning) 的 1.2 億 token。
這種輸出 token 的效率使得 Claude Opus 4.5(在思考模式下)在智能與運行 Artificial Analysis 智能指數成本之間提供了比 Claude Opus 4.1 (Thinking) 和 Grok 4 (Reasoning) 更好的權衡。雖然 Claude Opus 4.5 比幾乎所有其他推理模型都更加 token 高效,但它使用的 token 數量仍比 Claude Opus 4.1 多出約 50%。考慮到其相對較高的定價,Claude Opus 4.5 在運行 Artificial Analysis 智能指數時仍屬於最昂貴的模型之一,成本約為 1,500 美元。
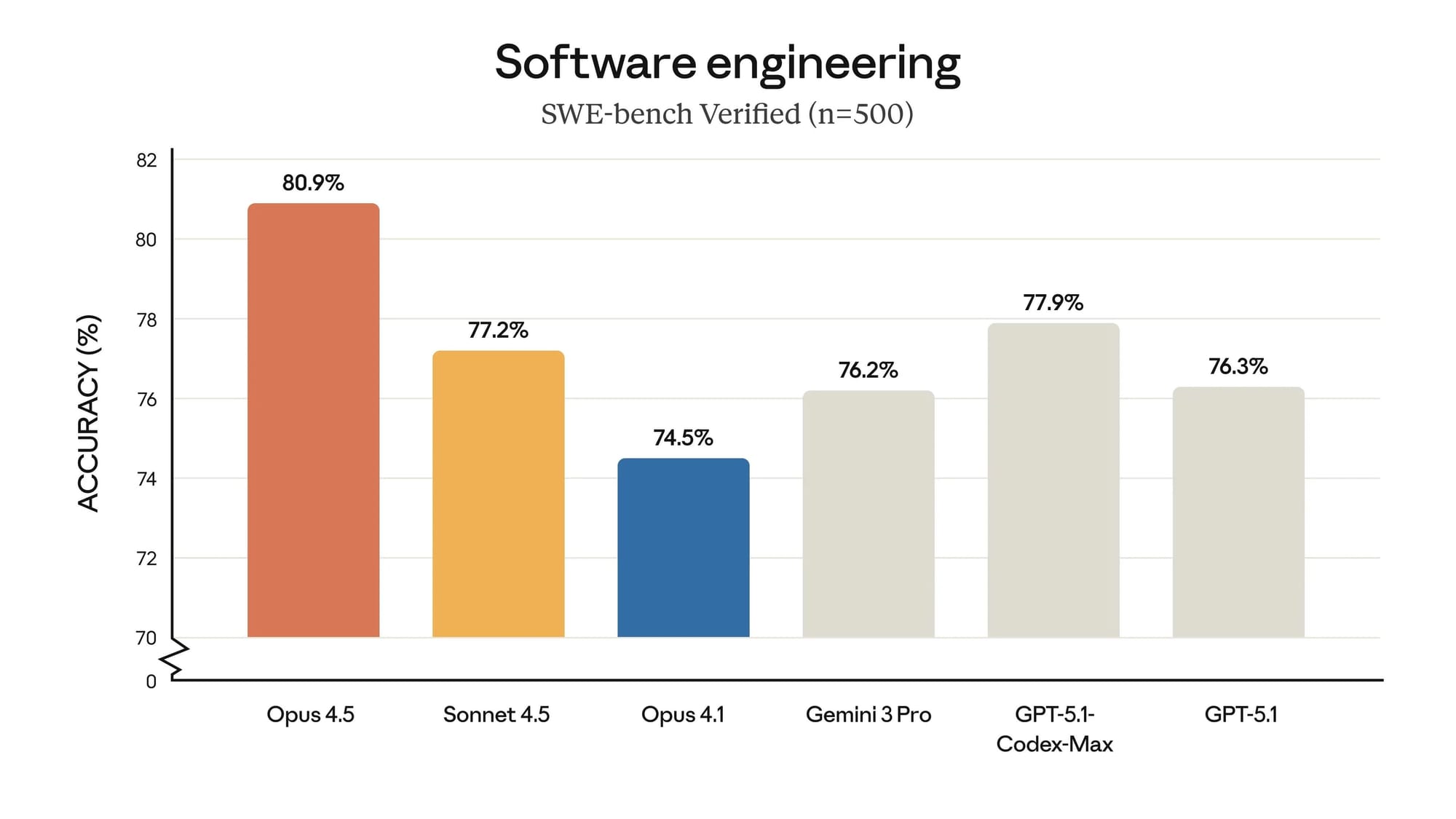
在編碼和智能體任務中表現最強
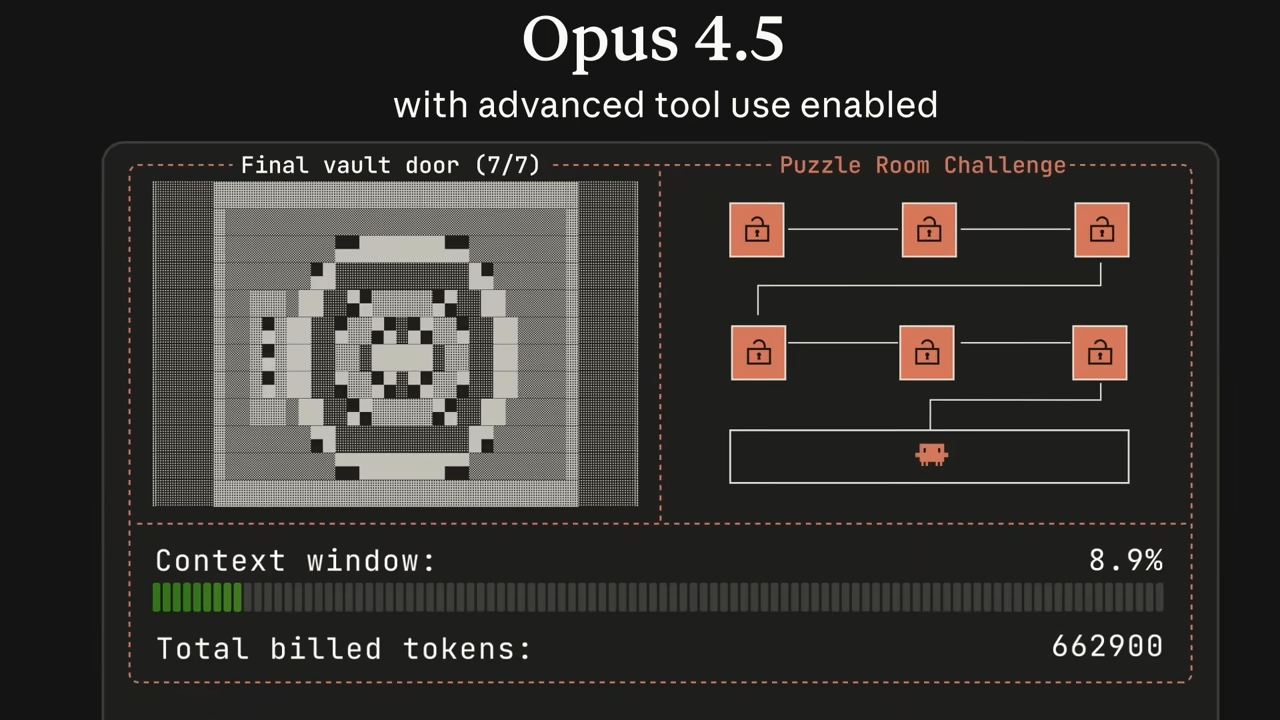
智能提升在對企業 AI 應用至關重要的領域中最為顯著。相較於 Claude Sonnet 4.5 (Thinking),Claude Opus 4.5 在編碼和智能體任務上展現了顯著的改進:在 LiveCodeBench 上提升了 16 個百分點,在 Terminal-Bench Hard 上提升了 11 分,在 τ²-Bench Telecom 上提升了 12 分,在 AA-LCR 上提升了 8 分,在 Humanity's Last Exam 上提升了 11 分。
Claude Opus 4.5 在智能指數的所有 10 項基準測試中都達到了 Anthropic 的最高分數。值得注意的是,它在 Terminal-Bench Hard 上以 44% 的成績獲得了所有模型中的最高分,並在 MMLU-Pro 上與 Gemini 3 Pro 並列 90% 的高分。在 CritPt 這項專為測試研究助理能力而設計的前沿物理評測中,Claude Opus 4.5 得分 5%,僅次於 Gemini 3 Pro(9%),與 GPT-5.1 (high) 並列。
知識與幻覺表現
Claude Opus 4.5 (Thinking) 在 Artificial Analysis Omniscience Index 這項衡量跨領域知識和幻覺的新基準測試中排名第二。Claude Opus 4.5 (Thinking) 在 Omniscience Index(主要指標,會對錯誤答案扣分)和 Omniscience Accuracy(正確率百分比)兩方面都排名第二,相較於同級模型提供了高準確率與低幻覺率的平衡。
該模型在 Omniscience Index 上獲得 10 分,僅次於 Gemini 3 Pro Preview 的 13 分,領先於 Claude Opus 4.1 (Thinking) 的 5 分和 GPT-5.1 (high) 的 2 分。它以 43% 的準確率排名第二,同時保持第四低的幻覺率 58%,僅次於 Claude Haiku (Thinking) 的 26%、Claude Sonnet 4.5 (Thinking) 的 48%,以及 GPT-5.1 (high)。
Anthropic 強調,Claude Opus 4.5 展現了比部分其他前沿模型(包括 Grok 4 和 Gemini 3 Pro)更低的幻覺率,強化了公司對 AI 安全的重視。這一點在企業部署時特別重要——畢竟,一個經常「胡說八道」的 AI 助手可能比沒有助手還要糟糕。
非推理模式領先群雄
在非推理模式下,Claude Opus 4.5 在 Artificial Analysis 智能指數中得分 60,成為最智能的非推理模型。它超越了 Qwen3 Max(55)、Kimi K2 0905(50)和標準推理模式下的 Claude Sonnet 4.5(50)。
可用性與技術規格
Claude Opus 4.5 具備 200,000 token 的上下文視窗,支援高達 64,000 輸出 token。該模型可透過 Anthropic 的 API、Google Vertex AI、Amazon Bedrock 和 Microsoft Azure 使用。它也可透過 Claude 應用程式和 Claude Code(Anthropic 的智能體編碼命令列工具)存取。
這次發布使 Anthropic 在日益擁擠的前沿模型市場中佔據了有利位置,Google、OpenAI 和 xAI 等新興競爭者都在競相提供更強大的 AI 系統。憑藉在實用任務上的強大表現、token 效率和降低的定價,Claude Opus 4.5 代表了 Anthropic 爭取需要強大 AI 能力且希望成本可預測的企業用戶的策略。
我認為這次的價格調整特別有意思。Anthropic 顯然意識到,要在企業市場取得成功,不能只靠技術優勢,還需要讓客戶能夠負擔得起。雖然 Claude Opus 4.5 在絕對成本上仍然不便宜,但考慮到它提供的性能提升和 token 效率,對於需要處理複雜任務的企業來說,這個價格是相當合理的。
Claude Opus 4.5 究竟升級了什麼?
核心定位很清楚:比前一代 Opus 4.1 還要聰明,同時更適合真正在 production 裡長時間跑任務的場景。它專門針對多步驟推理、複雜程式專案、以及需要多輪思考的研究型工作加強表現。
多步驟推理與延伸思考模式
預設就會拉長內部思考鏈,讓它在複雜規劃、長期專案拆解、以及多 Agent 協作上,比前代更穩定。這不是單純讓模型「想更久」,而是讓它建立更完整的思考架構。我發現這在處理需要多個步驟的任務時特別有用,模型不會因為中途遇到問題就亂了陣腳。
Effort 參數的彈性控制
Opus 4.5 獨家支援 high / medium / low effort,讓你決定要「更認真多想一點」還是「快速省錢」地回應,同時影響文字、工具呼叫和內部思考長度。這個功能在實務上解決了一個很實際的問題:不是所有任務都需要最高等級的思考,能夠依據任務重要性調整,可以大幅降低總體成本。
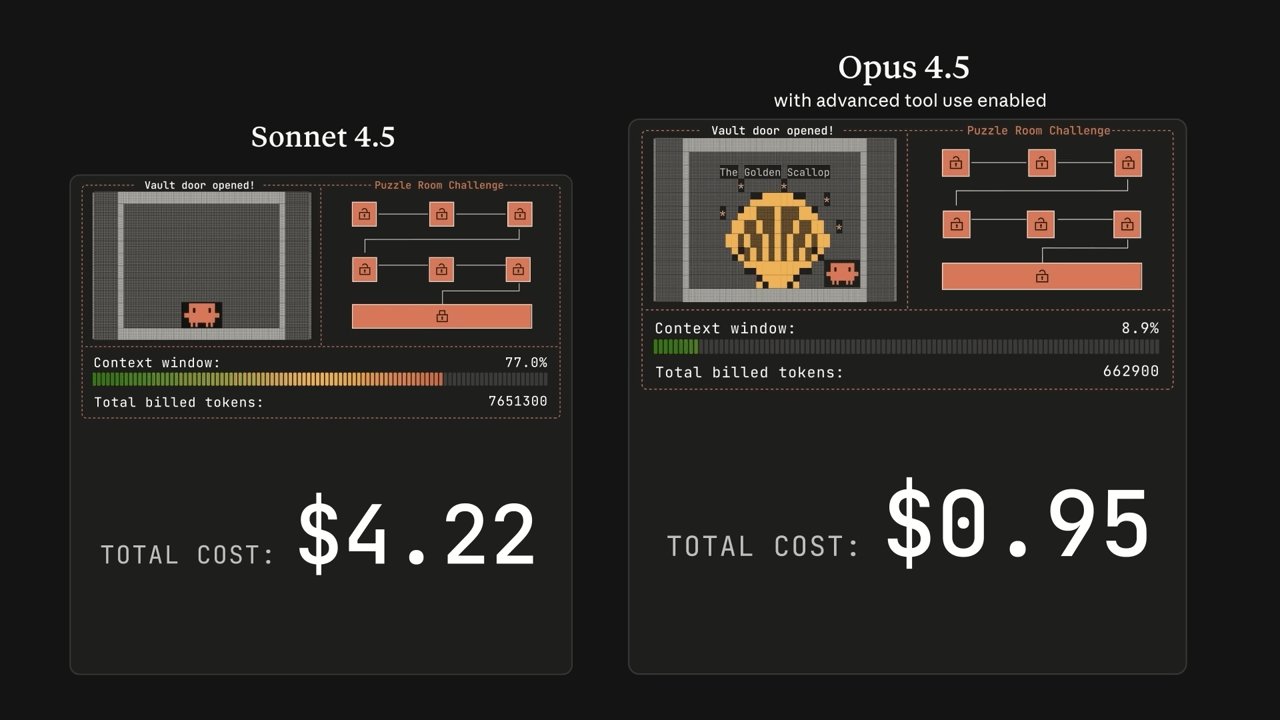
更強的電腦使用能力
新增螢幕區域放大(zoom action),能看清小字、複雜 UI,適合檢查細節後再自動點按或輸入資料。這個功能聽起來簡單,但在實際應用中非常關鍵。很多自動化任務之所以失敗,就是因為模型看不清楚畫面上的細節。
Context 與記憶管理
會保留之前的 thinking block,對於長對話與長任務不會「忘記前面怎麼想的」,這對 AI Agent 流程和深度研究特別重要。這意味著你可以進行更複雜的多輪對話,不用擔心模型會失去脈絡。
Claude 4.5 系列怎麼選?
Claude 4.5 其實是一整個家族:Opus、Sonnet、Haiku,各自有擅長的場景。官方把它們定位成「不同工作負載」的工具箱,你可以依照預算與任務難度搭配使用。
| 模型 | 適合情境 | 大致特色 |
|---|---|---|
| Claude Opus 4.5 | 高難度推理、專業軟體工程、複雜多步驟 AI Agent 流程 | 最高智慧等級、支援 effort 參數、最強 coding 與電腦操作能力 |
| Claude Sonnet 4.5 | 大多數 production 等級 Agent、日常 coding、長時間自動任務 | 性能接近舊 Opus 4.1、速度快、成本較低,是通用工作馬 |
| Claude Haiku 4.5 | 即時互動、客服、自動標註等高頻低延遲場景 | 4.5 系列中最快的模型,也拉高了智慧上限,是第一個支援 extended thinking 的 Haiku |
現在 Opus 4.5 會成為 Claude Pro、Max、Enterprise 的預設旗艦模型,一般用戶只要訂閱高階方案就能直接在 App 裡用到,不用自己切換版本。開發者則可以透過 claude-opus-4-5-20251101 這個 model name 在 API 中直接呼叫,或在支援的雲端平台上選擇這個模型來部署服務。
從成本效益的角度來看,我會建議大部分日常開發工作使用 Sonnet 4.5 就夠了,只在真正需要最高推理能力的時候才切換到 Opus 4.5。這樣既能維持開發效率,又能有效控制成本。
社群怎麼聊:真香還是過譽?
在開發者圈與 AI 圈,大家對 Claude Opus 4.5 的第一波反應可以大致分成「超強派」和「觀望派」。很多工程師實測後認為它在大型程式庫、跨檔案推理與自動修 bug 上,穩定度明顯優於多數同級模型,也很適合拿來做長時間運作的 IDE 助手或 code agent。
技術社群的正面評價
部落客與獨立開發者在實測中,普遍肯定它在 coding benchmark(像 SWE-bench Verified)上的表現,甚至可以和最新一代競品正面對決。Simon Willison 這位知名的開源開發者和技術評論家,在他的部落格上對 Claude Opus 4.5 的程式能力給予高度評價。
雲端與工具平台(例如整合到 GitHub Copilot 的預覽版)則強調它在複雜專案編輯、多檔案重構與 CLI 工作流程中的實用性。我自己在使用 GitHub Copilot 整合版本時,確實感受到它對專案整體架構的理解比之前更深入。
Reddit 等社群裡,從早期「泄漏發售日」的討論,到正式上線後的實測分享,整體氛圍是期待+好奇它能不能在日常工作裡真正取代既有工具。有趣的是,很多討論都聚焦在「實際工作流程」而不只是跑分數,這顯示大家真的想知道它能帶來什麼實質改變。
質疑與關注點
當然也有質疑聲:例如有人會拿它和最新的 GPT 或 Gemini 模型比,討論誰在創意寫作、圖像理解或更開放式對話上更強。也有人關心在大量使用 extended thinking 和 Agent 流程時,成本和延遲是否還能被接受,尤其是對高流量服務來說。
我個人認為這些質疑都很合理,畢竟沒有一個模型是萬能的。重點是要根據你的實際需求選擇合適的工具,而不是盲目追求「最強」的模型。
如果你現在就想上手 Claude Opus 4.5
實際要用,很簡單:一般使用者可以直接在 Claude 的官網或 App 裡升級到 Pro / Max,Opus 4.5 現在是這些方案的預設旗艦模型;企業版也會以它作為預設大腦。開發者則可以透過官方 API、支援的雲端平台,或像 Copilot 類型工具中的模型選單,直接切到 Opus 4.5 來實驗新功能。
如果你在公司裡正推進 Generative AI 專案,把 Claude Opus 4.5 想像成「高智商參謀」,再用一層 AI Agent 或產品介面把它包起來,會比直接丟給使用者來得實際。想學怎麼把這種模型變成真的營收與效率,可以多看 Tenten AI 對 AI Agent、生成式 AI 應用的案例與教學,會幫你把 Opus 4.5 放進一個更完整的商業架構裡。
Claude Opus 4.5 vs 競爭對手:該怎麼選?
如果你在選「Claude Opus 4.5 vs GPT-5.1 Thinking vs Gemini 3 Pro」,可以先記這個:Opus 4.5 最偏「穩定深度推理+守規則的 coding & agents」、GPT-5.1 Thinking 是「會自己調整思考時間的萬用推理怪」、Gemini 3 Pro 則是「多模態+長上下文+工具操作的工作型大腦」。實際選型時,通常是看你更在意「程式與長鏈推理品質」、「思考彈性」還是「多模態與大 context」,而不是單純誰分數最高。
| 模型 | 核心定位 | 推理風格與強項 | Coding & 工具能力 | 多模態 & 上下文 | 速度與成本 | 常被提到的缺點 |
|---|---|---|---|---|---|---|
| Claude Opus 4.5 | 旗艦級「深度推理+軟體工程+電腦操作」模型 | 強調長鏈推理與嚴謹規劃,內建 extended thinking,適合困難決策、技術寫作與長專案拆解 | 在軟體工程基準有頂級表現,支援工具調用、檔案與終端機、螢幕放大操作,適合實作 AI Agent、IDE 助手、workflow bot | 主要是強文字與程式上下文,支援長對話與大型 codebase;多模態有但不是主打,更多被當成「理性技術顧問」 | 相比先前 Opus 4.1 降價,屬於「高階但可負擔」區間;延伸思考和高 effort 模式會拉高延遲與 token 花費 | 偏保守,寧可道歉或拒絕也不亂猜;在某些實測裡,長流程執行偶爾會失去節奏或過度客氣,需要額外流程設計保護 |
| GPT-5.1 Thinking | 以「自動調整思考時間」為核心的高階推理模型 | 專門做深度多步驟推理、數學、結構化規劃,會依題目難度自動延長或縮短思考時間,難題上更穩定 | 官方定位在技術與分析工作:coding、資料解讀、格式嚴格的任務,也能結合工具與 RAG 來查詢最新知識 | 支援長上下文與外部工具整合,適合跨文件研究與需要查資料的分析任務;多模態能力存在,但主賣點是 reasoning / instruction-following | 比 Instant 型號慢,但在困難任務的效能/時間比通常更好;簡單任務會自動少想一點避免浪費算力 | 思考時間可觀,對即時互動或超大量高併發服務來說成本與延遲都要特別評估;越難的任務越可能「想很久但仍需人工複查」 |
| Gemini 3 Pro | 主打「多模態+長上下文+工具行動」的通用工作型大腦 | 在多數官方基準上超過 Gemini 2.5 Pro,擅長跨文本、圖片、影片與長計畫的推理,特別強調長期規劃與實務工作流程 | 很適合當跨產品的自動助理:可在日常任務裡串工具完成多步驟流程,也支援複雜 coding 任務與代理人模擬測試 | 1M token 等級上下文,能吃整個 code repo、PDF、影片等,並在多模態基準拿到頂級分數 | 在雲端與多產品裡提供,易於擴散到大量使用者;長上下文與多模態推理意味着重任務時成本與延遲都可能上升 | 一些獨立實測指出:coding 嚴謹度有時不如最保守的對手,偶爾會過度自信或忽略指令細節;在重度工程工作流中需要加強測試與防呆 |
如果你是要用這三個來打造實戰型 AI Agent 或商業產品,通常會讓 Claude Opus 4.5 或 GPT-5.1 Thinking 當「高智商後端大腦」,再用像 Gemini 3 Pro 這種多模態長上下文模型去處理資料、文件與跨渠道互動,整體體驗會比只押一個模型更穩。
從我的實戰經驗來看,最理想的架構往往是組合式的:用 Claude Opus 4.5 處理核心邏輯和複雜推理,用其他模型處理特定場景(如影片理解、即時互動等)。這種混合架構雖然複雜度較高,但能發揮各個模型的長處。
實際應用建議與最佳實踐
基於我過去幾天密集測試 Claude Opus 4.5 的經驗,我整理了幾個實用建議:
場景選擇策略
不要在所有場景都使用 Opus 4.5。對於簡單的程式碼補全、基礎問答,Sonnet 4.5 甚至 Haiku 4.5 就夠了。只在真正需要深度推理的時候才動用 Opus 4.5,例如:複雜的系統設計決策、跨多個檔案的重構、需要理解大量上下文的 debug 任務。
Effort 參數的實用技巧
Low effort 適合:快速原型開發、簡單的程式碼生成、不太重要的文件撰寫。Medium effort 適合:日常開發任務、一般複雜度的 debug、標準的 code review。High effort 適合:關鍵系統設計、複雜演算法實作、需要嚴謹推理的架構決策。
成本控制方法
建議在開發環境使用較低的 effort 設定,在生產環境或關鍵任務才提高。可以設定監控機制,追蹤不同任務類型的 token 使用量,找出最佳的模型與 effort 組合。對於重複性高的任務,考慮先用 Opus 4.5 生成高品質範本,後續使用較便宜的模型套用範本。
與 Tenten 一起掌握 AI 轉型契機
看完這些技術細節,你可能會想:「這些強大的 AI 模型要怎麼真正應用到我的業務中?」這正是 Tenten 專注的領域。我們不只是追蹤最新的 AI 技術,更重要的是幫助企業找到最適合的 AI 整合方案,將這些先進技術轉化為實際的商業價值。
無論你是想建立自動化客服系統、開發智能行銷工具,還是打造企業級的 AI Agent,Tenten 都有豐富的實戰經驗可以分享。我們的團隊深諳各種 AI 模型的特性與應用場景,能協助你設計出最符合成本效益的解決方案。
別讓技術的複雜性阻礙了你的數位轉型之路。立即預約諮詢,讓 Tenten 的 AI 專家團隊為你量身打造專屬的 AI 策略,在這波 AI 革命中搶得先機。
延伸閱讀與權威資源
為了提供更全面的視角,以下是來自頂尖學術機構、研究組織和產業領袖的相關資源:
- Stanford HAI - AI Index Report - 史丹佛大學人工智慧研究所發布的年度 AI 指標報告,提供全球 AI 發展的權威數據與趨勢分析
- MIT Technology Review - AI Section - 麻省理工學院科技評論的 AI 專欄,深入探討 AI 技術的最新發展與社會影響
- McKinsey - The State of AI - 麥肯錫顧問公司對 AI 商業應用的年度調查與洞察
- Harvard Business Review - AI and Machine Learning - 哈佛商業評論關於 AI 與機器學習的商業策略文章
- Anthropic Research - Anthropic 官方研究論文與技術報告,深入了解 Claude 系列模型的技術細節
關於作者
本文由 Tenten 數位策略團隊撰寫。作為專注於 AI 技術應用與數位轉型的專業團隊,我們持續追蹤最新的 AI 發展動態,並將這些洞察轉化為實用的商業策略建議。
在與數十家企業合作的過程中,我們發現最成功的 AI 導入案例,往往不是單純追求最強大的模型,而是找到技術能力與業務需求之間的最佳平衡點。Claude Opus 4.5 的推出,為企業提供了一個強大但相對可負擔的選擇,特別適合那些需要穩定、可靠的程式開發與自動化解決方案的團隊, 歡迎隨時與我們交流,一起探索最適合你的 AI 應用策略。










