Claude Opus 4.7 於 2026 年 4 月 16 日正式發布,SWE-bench Verified 分數從 Opus 4.6 的 80.8% 跳到 87.6%,但大量開發者在 48 小時內回報「同一組 prompt 產出品質變差」。 問題不在模型退步,而在 Opus 4.7 改變了跟你互動的方式:它不再幫你腦補模糊指令,逐字照做你寫的東西。X 上的 @the_smart_ape 用一句話講完核心問題:Opus 4.6 一直在替你的模糊 prompt 兜底,4.7 不幹了。
這篇文章拆解 Opus 4.7 的五項重大變更,附上具體的 prompt 修改策略,讓你把新模型的能力榨乾。
Opus 4.7 到底改了什麼:三項破壞性 API 變更
Anthropic 在 Opus 4.7 裡拿掉了三個 API 參數,如果你的程式碼還在用,會直接收到 400 錯誤。
第一,Extended Thinking 預算消失了。Opus 4.6 可以設 budget_tokens: 32000 來控制推理深度,4.7 改成自適應思考(adaptive thinking),模型自己決定要想多久。Anthropic 內部測試顯示自適應方式表現穩定優於固定預算。
第二,temperature、top_p、top_k 被移除。任何非預設值都會回傳錯誤。以前靠 temperature=0 追求確定性的做法要改用 prompt 層面的格式約束,例如指定 JSON schema 或明確的輸出模板。
第三,思考內容預設隱藏。4.7 會在背景跑推理,但除非你主動設定 "display": "summarized",否則使用者端只會看到一段沈默後直接跳出答案。做過「展示 AI 推理過程」功能的產品要特別注意。
| 變更項目 | Opus 4.6 | Opus 4.7 |
|---|---|---|
| 推理預算 | budget_tokens: 32000(手動設定) |
thinking: {"type": "adaptive"}(模型自決) |
| 採樣參數 | temperature/top_p/top_k 可調 |
移除,回傳 400 錯誤 |
| 思考顯示 | 預設顯示推理過程 | 預設隱藏,需手動啟用 |
| 視覺解析度 | 1568px / 1.15MP | 2576px / 3.75MP |
| Tokenizer | 舊版 | 新版,同樣文字約多 1.0–1.35 倍 token |
| Effort 層級 | low / medium / high / max | 新增 xhigh(Claude Code 預設值) |
最大行為變化:逐字照做,不再幫你補完
Opus 4.7 的 instruction following 能力大幅提升,Notion 的 AI Lead Sarah Sachs 指出這是第一個通過他們「隱性需求測試」的模型,複雜多步驟工作流程比 Opus 4.6 進步 14%,工具呼叫錯誤減少三分之二。
但這個優勢有代價。過去 Opus 4.6 會自動「幫你想到」你沒寫的東西:你說「整理這份文件」,它會順便修格式、加標題、調排版。Opus 4.7 不會。你說整理,它就只整理。沒提到格式,格式不動。
開發者社群的反應很兩極。Boris Cherny——Claude Code 的創造者——在 X 上承認「我也花了幾天才學會怎麼用」,這則貼文拿了 936 個讚。同一時間,一位日本開發者的評論被大量轉發:「評判悪すぎて速攻 4.6 にした」(評價太差,秒切回 4.6)。
FindSkill.ai 分析數百則社群回饋後的結論是:prompt 寫得愈具體的人,升級體驗愈好;愈依賴模型「讀心術」的人,落差愈大。
新的 Effort 參數:選錯等於浪費錢
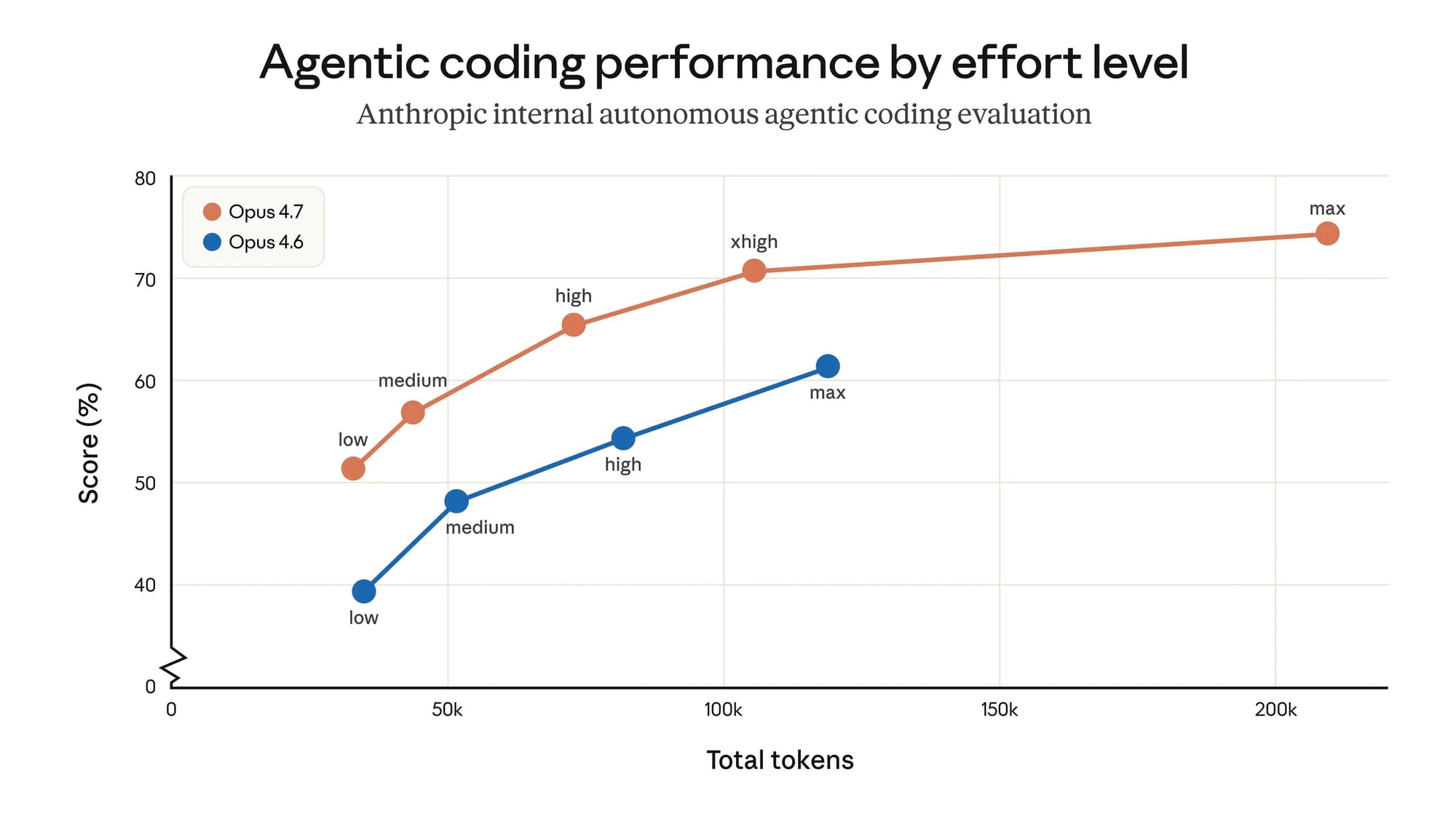
Opus 4.7 新增了 xhigh effort 層級,位在 high 跟 max 之間。Claude Code 把所有方案的預設值拉到 xhigh,因為 Anthropic 判斷 high 在程式開發場景榨不出夠好的品質。
Hex 的 CTO Caitlin Colgrove 在 Anthropic 官方測評中給出一個有用的對照:低 effort 的 Opus 4.7 大約等於中 effort 的 Opus 4.6。換句話說,如果你把 effort 設太低,新模型的表現可能還不如舊模型的中等設定。
Anthropic 官方建議:程式開發和 agentic 場景從 xhigh 起跳,多數需要智力密集的任務至少用 high。如果你的 prompt 還在寫「think step by step」或「reason carefully before responding」,把這些刪掉,改用 effort 參數來達成同樣效果——那些指令是在補償 4.6 的推理能力不足,4.7 在高 effort 下原生就有那個推理深度。
五個必須改的 Prompt 習慣
根據 Anthropic 官方 prompting best practices 文件、Boris Cherny 的實測心得,以及 keepmyprompts.com 的遷移指南,以下是最影響產出品質的五個調整:
1. 砍掉模糊語氣詞。 「try to」「if possible」「you might want to」這類語氣在 4.6 有用,因為模型會慷慨詮釋。4.7 把它們當成弱化指令處理。改法:把每句指令寫成明確的命令句。「試著抽取文件中的 email」→「抽取文件中所有 email,回傳 JSON 陣列,沒有就回傳空陣列」。
2. 刪掉冗餘的長度控制。 4.7 會根據任務複雜度自動調整回覆長度。簡單問題給短答案,複雜問題給長答案。「be concise」這類指令現在大多多餘,除非你要覆寫自動校準(例如「回覆限制在 3 句以內」仍然有效)。
3. 補上工具使用的硬性規則。 中低 effort 下,4.7 偏好用推理取代工具呼叫。如果你的 agent 升級後突然不用某些工具了,不用重寫工具描述,先試著拉高 effort。如果 effort 已經夠高但工具仍被忽略,在 system prompt 加上硬性規則:「任何超過 2 個變數的計算,必須使用 calculator 工具」。
4. 明確指定語氣。 Opus 4.7 的預設語氣比 4.6 直接得多,不再有「好問題!」之類的暖場。客服、教練、心理健康類產品需要在 system prompt 裡明確寫出你要的語氣風格。
5. 指定子代理(sub-agent)策略。 4.7 預設產生更少的 sub-agent。如果你的工作流依賴平行處理,要在 prompt 裡寫清楚:「對於研究型任務,當子查詢互相獨立時,請委派給平行 sub-agent」。
Token 用量會增加:新 Tokenizer 的影響
Opus 4.7 換了新的 tokenizer,同樣的輸入文字可能映射到 1.0 到 1.35 倍的 token 數量。部分開發者實測甚至到 1.16–1.51 倍。定價沒變——輸入 USD 5(約 NTD 160)/ 百萬 token,輸出 USD 25(約 NTD 800)/ 百萬 token——但單次請求的實際成本可能上升。
Anthropic 的回應是提高所有訂閱方案的速率限制。Boris Cherny 宣布這件事的那則貼文拿了超過 15,000 個讚,是 Anthropic 工程師貼文中互動最高的一則。
實務建議:把 max_tokens 參數調高 20–35%,給新 tokenizer 留餘裕。成本敏感的場景可以搭配新的 task budget 功能(beta),設定整個 agentic 迴圈的 token 上限。
視覺能力:解析度翻 3 倍
Opus 4.7 的圖像解析度從 1568px 提升到 2576px(約 3.75 百萬像素),是 4.6 的 3.3 倍。座標現在直接對應實際像素,不用再做縮放換算。
XBOW 的 CEO Oege de Moor 在 Anthropic 官方評測中報告:他們的視覺準確度基準測試從 Opus 4.6 的 54.5% 跳到 4.7 的 98.5%。這對 computer use 場景影響重大——過去因為視覺精度不夠而無法處理的整類工作,現在可以交給 Opus 處理。
Anthropic 自己的評測也印證這一點:僅靠解析度提升就在 InfographicQA 上進步 2.4 個百分點,ScreenSpot Pro 上進步 4.4 個百分點。
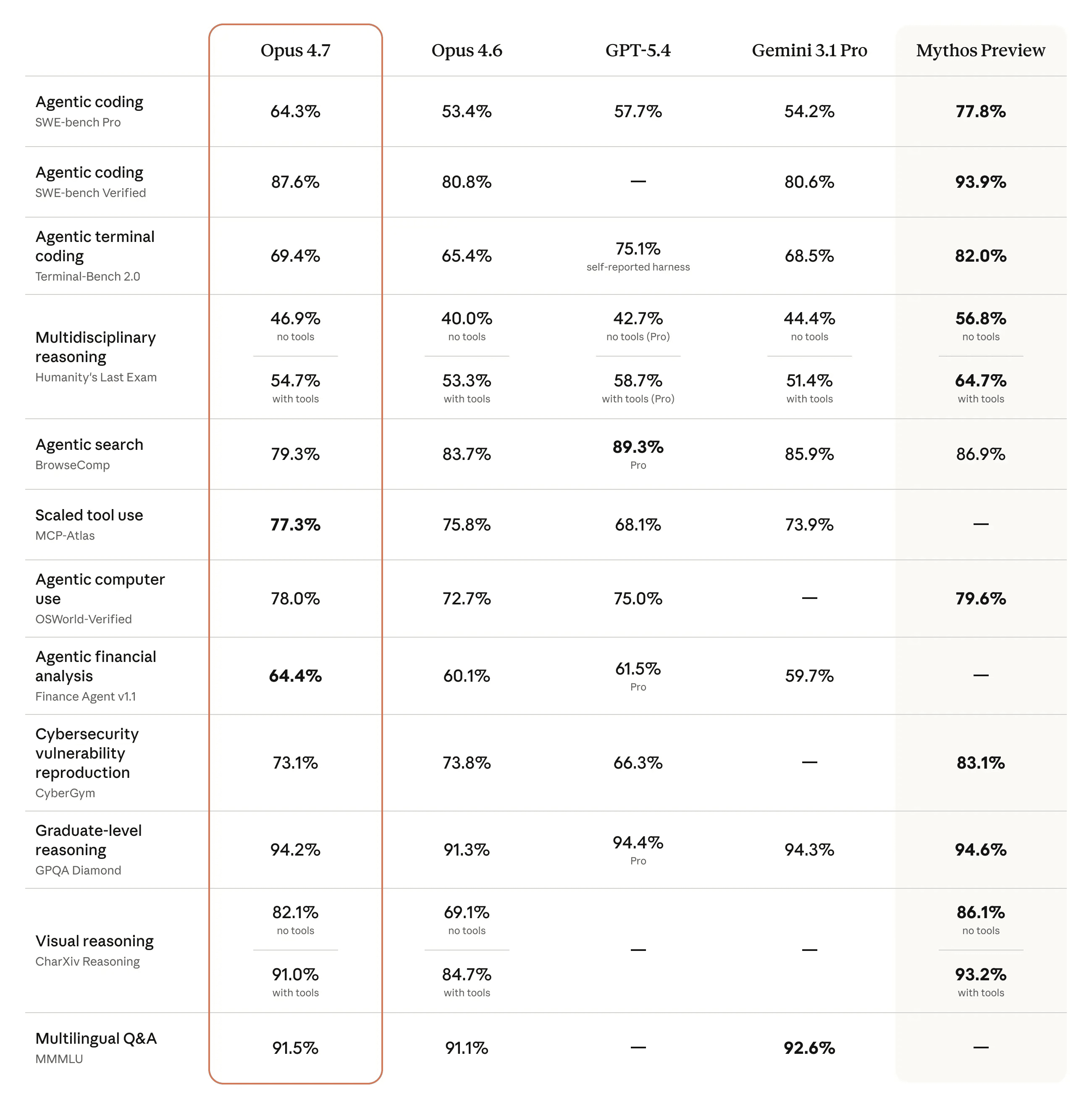
Benchmark 數據一覽
| 基準測試 | Opus 4.6 | Opus 4.7 | 變化 |
|---|---|---|---|
| SWE-bench Verified | 80.8% | 87.6% | +6.8pp |
| SWE-bench Pro | 53.4% | 64.3% | +10.9pp |
| CursorBench | 58% | 70% | +12pp |
| BigLaw Bench(Harvey) | — | 90.9%(high effort) | — |
| XBOW 視覺準確度 | 54.5% | 98.5% | +44pp |
| Rakuten-SWE-Bench | 基準 | 3x 解決率 | 200% 提升 |
誰應該現在升級,誰應該等
立刻升級的情境:你的工作流是長時間自主運行的 coding agent、需要精確 instruction following 的結構化任務、或者依賴視覺理解的 computer use 場景。這三個領域的進步最明確,回報最高。
先等的情境:你的 prompt 大量依賴模型自行推斷意圖、目前的 4.6 表現已經穩定、或者你的成本預算沒有 20–35% 的緩衝。Opus 4.7 不是白吃的午餐——它更強,但它要求你也更精準。
Hex CTO 的一句話總結了這次升級的本質:這是一個更聰明也更高效的 Opus 4.6。但你得先調整你跟它說話的方式。
Claude Opus 4.7 跟 4.6 的主要差異?
Opus 4.7 在 SWE-bench Verified 上拿到 87.6%(4.6 是 80.8%),instruction following 顯著加強,圖像解析度提升 3.3 倍到 2576px。但三個 API 參數被移除(temperature、top_p/top_k、手動 thinking budget),prompt 需要重新調整。新的 xhigh effort 層級在 100k token 預算下就能超過 4.6 max 在 200k token 的表現。
Opus 4.7 為什麼感覺比 4.6 差?
不是模型變弱,是模型變「字面」了。4.6 會自動補完你沒寫清楚的意圖,4.7 逐字照做。如果你的 prompt 寫得模糊,產出品質會下降。修正方法:把指令寫成明確的命令句,砍掉「try to」「if possible」等語氣詞,用 effort 參數取代「think step by step」等推理輔助文字。
Claude Opus 4.7 的 effort 參數怎麼選?
程式開發和 agentic 場景用 xhigh(Claude Code 預設值),智力密集任務至少用 high,一般對話用 medium,簡單分類和抽取用 low。低 effort 的 Opus 4.7 大約等於中 effort 的 Opus 4.6,所以設太低等於浪費升級。
Opus 4.7 的 token 用量為什麼增加?
新 tokenizer 讓同樣的文字映射到更多 token(1.0–1.35 倍,部分實測到 1.51 倍)。定價不變,但單次請求成本可能上升。建議把 max_tokens 調高 20–35%,並用 task budget 功能控制 agentic 迴圈的總用量。
Claude Opus 4.7 值得升級嗎?
值得,但不是無痛升級。你需要調整 prompt(砍模糊語氣詞、加明確格式指令、設定正確 effort 層級)、更新 API 參數(移除 temperature 等已廢棄項目)、預留 20–35% 的 token 預算緩衝。花 2–3 天調整後,多數團隊回報產出品質和一致性明顯提升。
引用來源
- Anthropic — Introducing Claude Opus 4.7
- Anthropic — Prompting best practices for Claude
- Caylent — Claude Opus 4.7 Deep Dive: Capabilities, Migration, and the New Economics of Long-Running Agents
- FindSkill.ai — Opus 4.7 'Regression': Why Your Prompts Stopped Working
Author Insight
我們團隊在 Opus 4.7 發布當天就開始測試,前兩天的感受跟社群大多數人一樣:原本跑得好好的 prompt pipeline 突然產出不穩定。但仔細分析後發現,問題集中在兩類 prompt——一是大量使用模糊語氣詞的內容生成任務,二是沒有明確指定輸出格式的 agentic 工作流。花了大約三天重新調整 system prompt 後,產出品質確實比 4.6 時期好了一截,尤其是長篇技術分析的結構一致性和程式碼審查的準確度。
我們目前的做法是:所有 Claude Code 專案強制 xhigh effort,內容生成 pipeline 用 high,純格式轉換用 low。Prompt 層面砍掉所有「try to」「if possible」,每個工具呼叫規則都寫成 MUST 條件句。這套配置在過去五天的實測中穩定運行。