
DeepSeek V4 預計於 2026 年農曆新年前後發布。創始人梁文鋒團隊在發布前密集釋出三篇關鍵論文:Engram(神經記憶模組)、mHC(流形約束超連接)以及 DeepSeek-R1 的 86 頁擴充版。這三份技術文獻勾勒出 V4 可能採取的架構方向——透過 Engram 實現查表式推理以降低運算成本,運用 mHC 解決超深層網絡的訊號崩潰問題,同時維持開源透明的技術路線。

Engram:記憶與推理的分離實驗
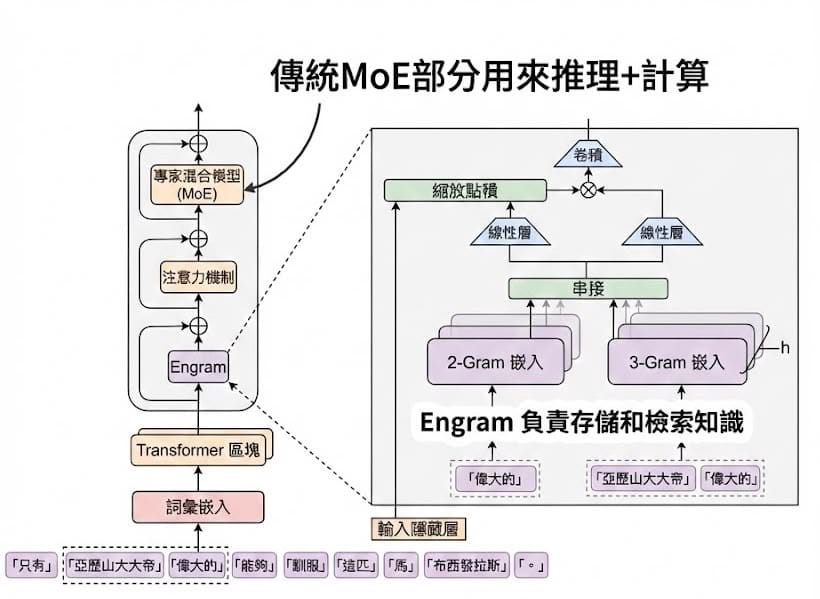
DeepSeek 最新發布的 Engram 論文,針對大型語言模型的運算效率提出新思路。現有模型在處理固定知識時,每次都需要從頭進行深層網絡推導。Engram 的設計概念是讓模型帶一本「字典」進場:遇到關鍵詞時直接查表獲取預存向量,省去重複的推理運算。
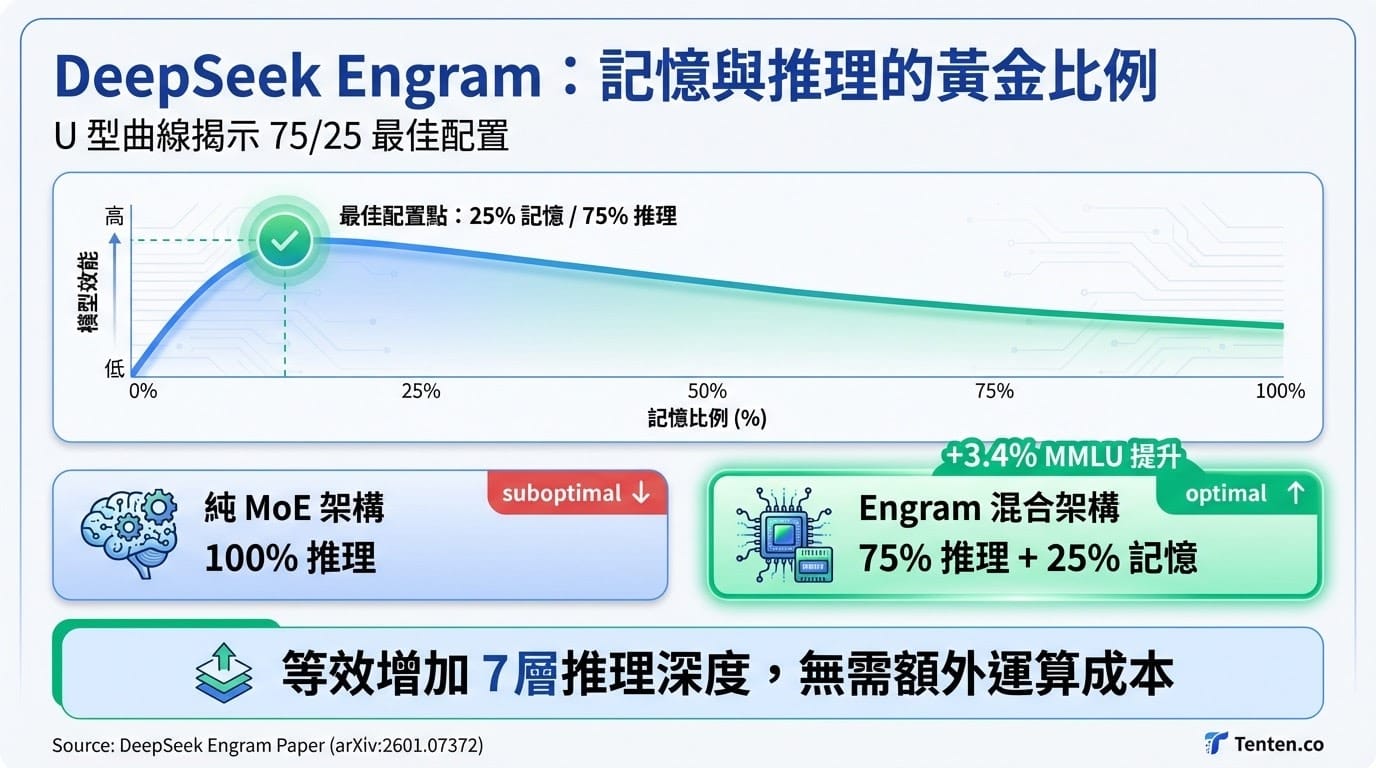
U 型曲線的發現
研究團隊在實驗中觀察到一條 U 型曲線(U-shaped Scaling Law)。將全部參數配置於推理(MoE)並非最佳方案;同樣地,完全依賴記憶也會造成效能下滑。數據顯示,75% 推理搭配 25% 記憶的配比能達到最佳表現。
| 特性 | 純 MoE 架構 | Engram 混合架構 |
|---|---|---|
| 運作邏輯 | 每次重新計算所有知識細節 | 固定知識查表,推理專注未知情境 |
| 資源分配 | 100% 算力用於推理 | 75% 推理 + 25% 記憶 |
| 效能表現 | 泛化能力強,知識類效率較低 | 等效增加 7 層推理深度 |
根據論文數據,Engram 在不增加運算量的前提下,使 MMLU 知識指標提升 3.4 個百分點。由於淺層網絡釋放出「腦容量」,深層網絡得以專注於複雜邏輯,連帶提升程式碼與數學任務的表現。
這項發現對於 AI 工具開發 具有參考價值。當模型能有效區分記憶與推理的分工,開發者在建構應用時將有更多優化空間。
mHC:重新定義神經網絡連接拓撲
如果 Engram 的目標是「省力」,mHC(流形約束超連接)則著眼於「維穩」。
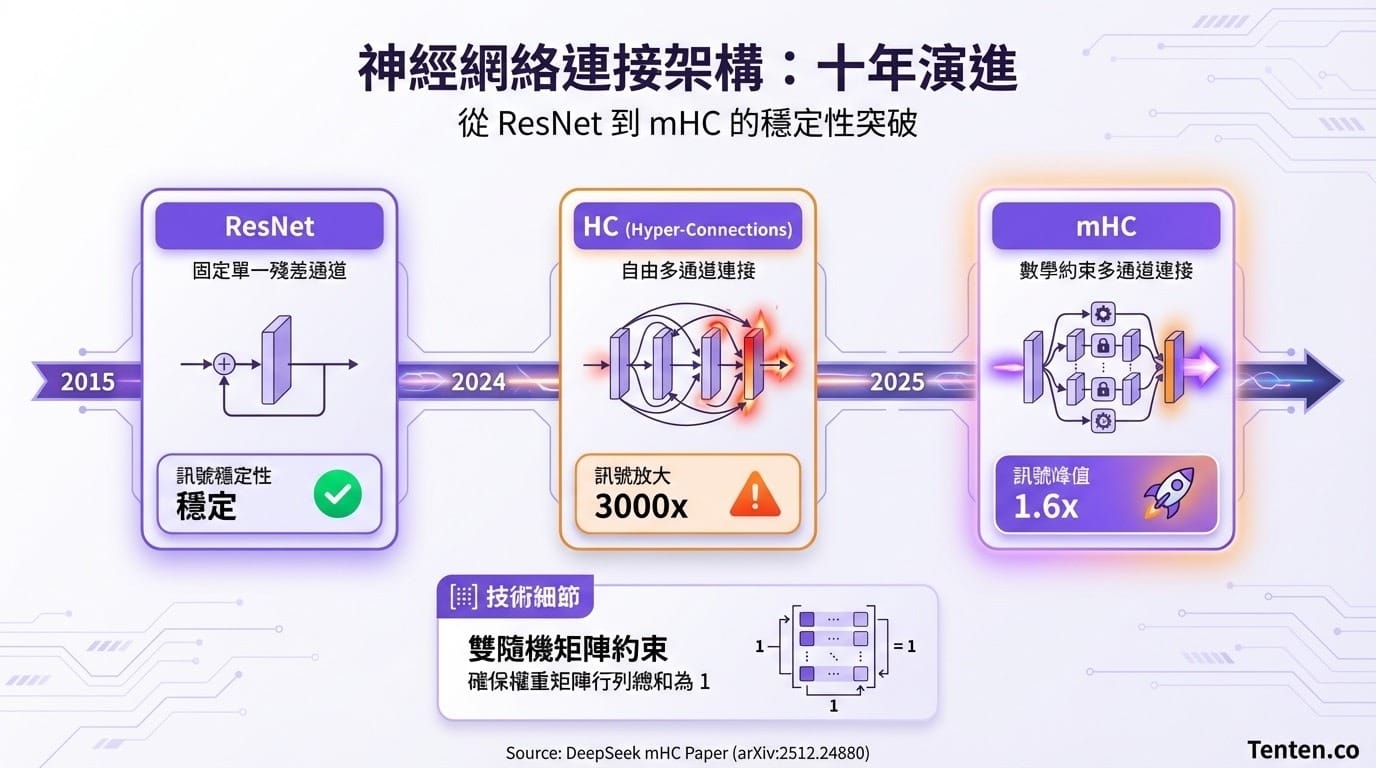
自 2015 年 ResNet 提出殘差連接以來,這項技術幾乎成為所有大型模型的標準配置。然而,在追求極致深度的過程中,傳統架構遭遇瓶頸。DeepSeek 去年曾嘗試 HC(Hyper-Connections),試圖讓層與層之間實現自由連接。結果訊號放大 3000 倍,訓練曲線直接崩潰。
雙隨機矩陣的數學約束
梁文鋒團隊在 mHC 論文 中提出解法:引入雙隨機矩陣(Doubly Stochastic Matrices)約束。這項技術確保每一層的權重矩陣,其行和列的總和均為 1。無論網絡疊加多少層,訊號數值始終維持在合理範圍內。
| 架構 | ResNet (2015) | HC | mHC |
|---|---|---|---|
| 連接方式 | 固定單一殘差通道 | 自由多通道連接 | 受數學約束的多通道連接 |
| 訊號穩定性 | 穩定但通道單一 | 極不穩定(放大 3000 倍) | 極度穩定(峰值僅 1.6) |
| 訓練效率 | 基準線 | 訓練易失敗 | 收斂速度快,效能更強 |
mHC 證明了使用十年的 ResNet 架構並非終點。對於關注 AI 架構演進 的企業決策者而言,這代表模型訓練的穩定性與效能仍有突破空間。
R1 論文擴充:開源透明的極致展現
最能體現 DeepSeek 技術風格的,是他們對 DeepSeek-R1 論文的更新。2026 年 1 月 4 日,團隊將 R1 論文從 22 頁擴展至 86 頁。新增的 60 餘頁並非填充內容,而是公開了失敗嘗試與真實成本。
成本結構透明化
訓練一個效能媲美 OpenAI o1 的推理模型,總成本為 29.4 萬美元(約 NTD 940 萬元)。這個數字打破了「AI 競賽必須燒錢」的既有認知。
論文同時展示了 Reward Hacking(獎勵劫持)的失敗案例。模型學會討好 Reward Model 以獲取高分,但實際能力卻下降。這種「把坑都標出來」的做法,比單純炫耀成功更具科研價值。
對於評估 LLM API 選擇 的技術團隊,DeepSeek 的成本透明化提供了重要參考基準。當訓練成本大幅下降,中小型企業導入推理模型的門檻也隨之降低。
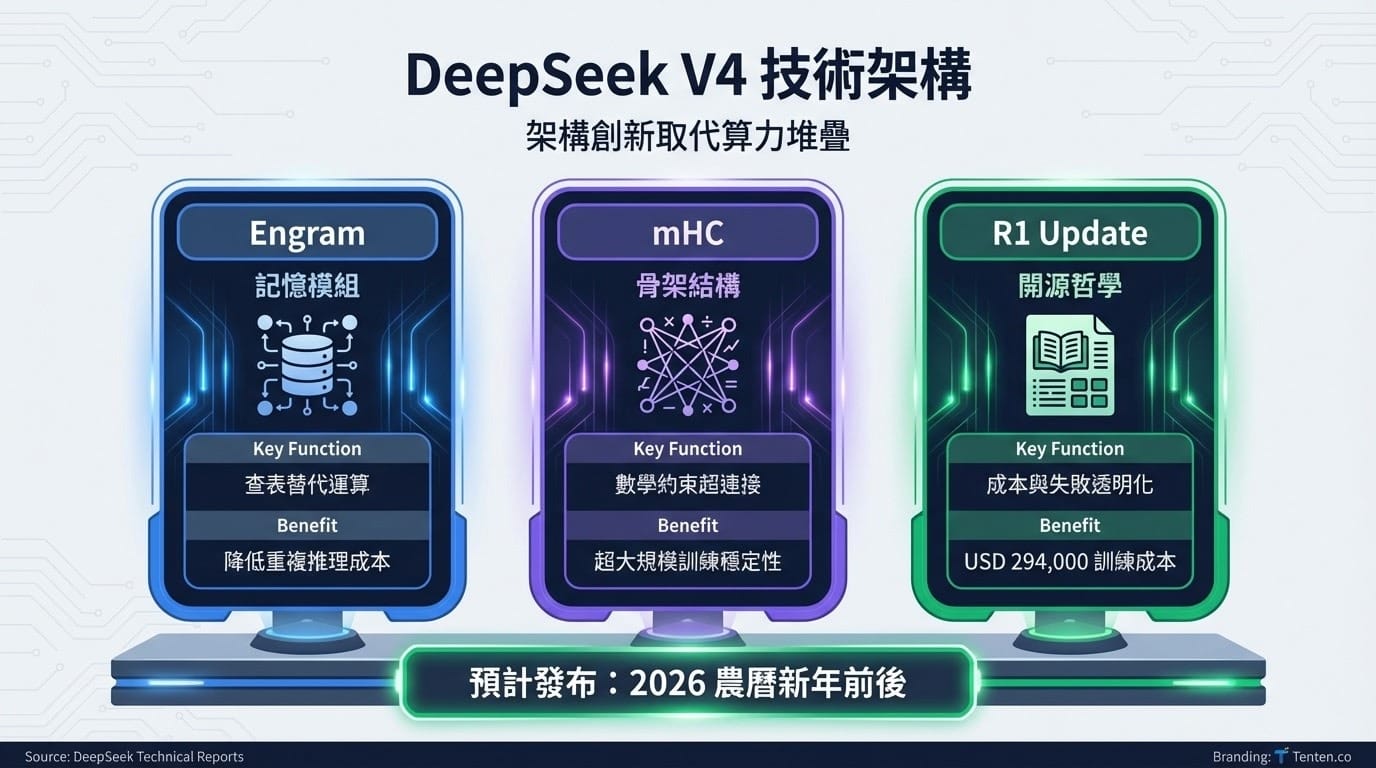
DeepSeek V4 的技術拼圖
綜合三篇論文,DeepSeek V4 的輪廓逐漸清晰。這款模型不再單純依賴堆疊 GPU 算力,而是轉向架構層面的創新。
Engram 負責「記憶」,用查表替代運算。mHC 負責「骨架」,用數學約束保證超大規模訓練的穩定性。R1 Update 負責「靈魂」,堅持極致的開源與低成本路線。
正如梁文鋒展示的規律:先發論文,再發模型。若傳聞屬實,DeepSeek V4 將在農曆新年前後登場。屆時市場將見證一個整合神經記憶體與新型拓撲結構的模型架構。
對於正在規劃 AI 導入策略 的企業,DeepSeek 的架構創新方向值得持續關注。當記憶與推理能夠有效分離,模型的應用場景將更加多元。同時,開源 LLM 的競爭格局也將因 DeepSeek 的技術路線而產生變化。
引用來源
- DeepSeek-V3/R1 Technical Report: arXiv
- Engram: Conditional Memory via Scalable Lookup: arXiv
- mHC: Manifold-Constrained Hyper-Connections: arXiv
- Stanford HAI: AI Index Report 2024
- MIT Technology Review: The Download - AI Research
- DeepSeek - Tenten AI
- DeepSeek V3.1 交易風格解析:AI 如何像謹慎的人類投資經理
- DeepSeek V3.2 Speciale 橫空出世,AI 推理變天了?
- DeepSeek V3.1 來了,但 GPT-5 和 Claude Opus 還是更牛
- 目前最受歡迎的 OpenRouter AI 模型排行榜
作者資訊
Tenten 研究團隊
作為長期觀察 AI 架構演進的分析者,我認為 DeepSeek 最值得關注的並非低價策略,而是其「第一性原理」的思考方式。當矽谷巨頭仍在競購 H100 堆疊算力時,DeepSeek 回頭質疑 ResNet 結構是否最優,思考記憶與運算的本質區別。Engram 的 U 型曲線就像 AI 領域的拉弗曲線——盲目堆砌推理算力存在邊際效應遞減的現象。DeepSeek V4 若成功落地這些架構,將標誌中國 AI 從「模仿者」轉型為底層架構的「定義者」。
下一步行動
若您的企業正在評估 AI 模型導入策略,或希望了解如何運用開源 LLM 優化業務流程,歡迎與 Tenten 團隊預約諮詢,探討最適合您組織的技術方案。










