
TL;DR 重點摘要
DeepSeek V4 即將於 2026 年春節前後(2 月中旬)發布,據洩漏消息指出,這將是一款「程式編碼優先(Coding-First)」的模型。其核心秘密武器在於全新的 Engram 架構(條件記憶),透過將靜態記憶(知識儲存)與動態推理(GPU 計算)分離,實現了 的極速查找與更低的推理成本。內部測試顯示,V4 在長篇程式碼生成與多檔案推理上可能超越 GPT 與 Claude。這不僅是性能的提升,更是 AI 模型運作邏輯的根本性轉變。

DeepSeek 再次成為 AI 圈的焦點。根據多方洩漏與內部消息,DeepSeek V4 正準備在春節前後(約 2 月中旬)震撼發布。初步測試表明,它在程式設計領域的表現可能全面碾壓現有的巨頭如 GPT 和 Claude。
但這不僅僅是跑分上的勝利。DeepSeek V4 代表了一種根本性的架構轉移。今天,我們將深入剖析 DeepSeek 如何走到這一步,解密洩漏的 Engram 架構(Engram Architecture),以及為什麼這可能是 2026 年最重要的模型發布。
DeepSeek 的進化策略:從效率到推理
要理解 V4,必須先看懂 DeepSeek 的佈局。他們從不隨機發布模型,每一步都經過深思熟慮:
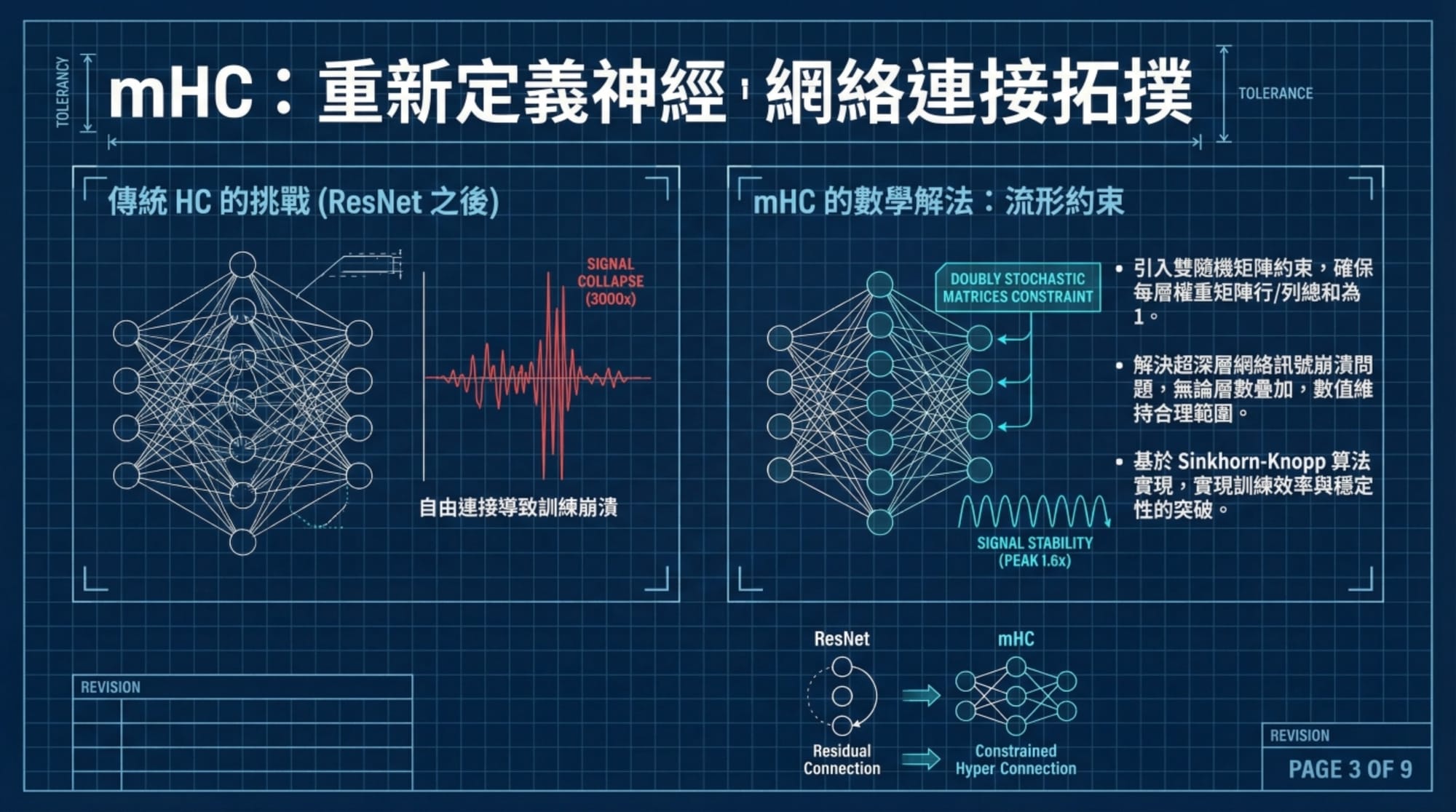
- DeepSeek V2: 重點在於「效率」。引入了 MLA(多頭潛在注意力),證明了不需要暴力堆疊參數也能獲得強大的推理能力。
- DeepSeek V3: 轉向 MoE(混合專家模型) 的實用化。以極低的成本實現了頂級的編碼與推理能力,成為開發者圈內「安靜的強者」。
- DeepSeek R1: 這是「推理優先」的嘗試。它不追求通用性,而是專注於長思維鏈(Chain of Thought)與深度邏輯,彷彿在說:「在擴大規模之前,我們先搞懂如何思考。」
現在,DeepSeek V4 似乎是這一切的集大成者。它不再將推理與通用模型分開,而是將 R1 的深度思考能力直接「烘焙」進旗艦模型中。
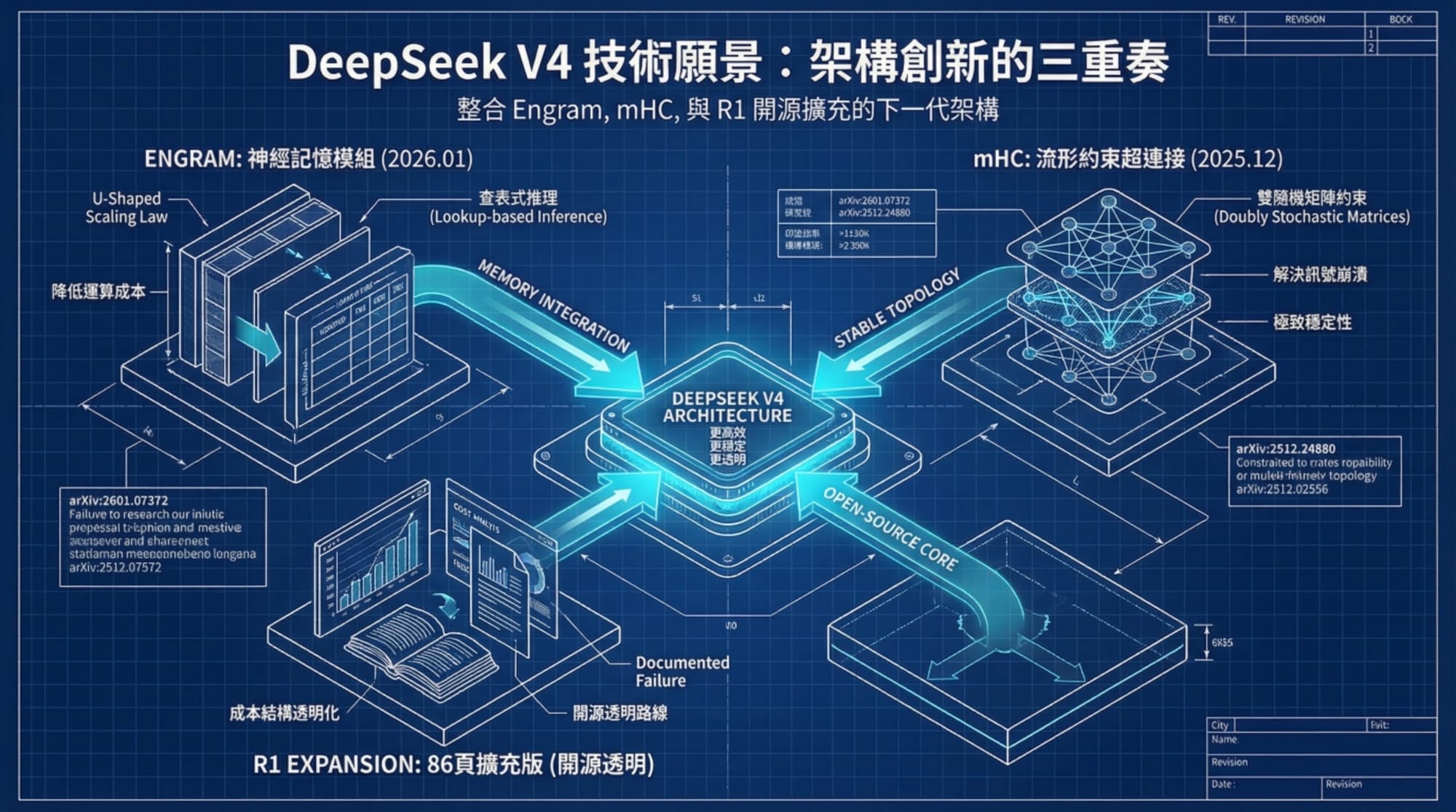
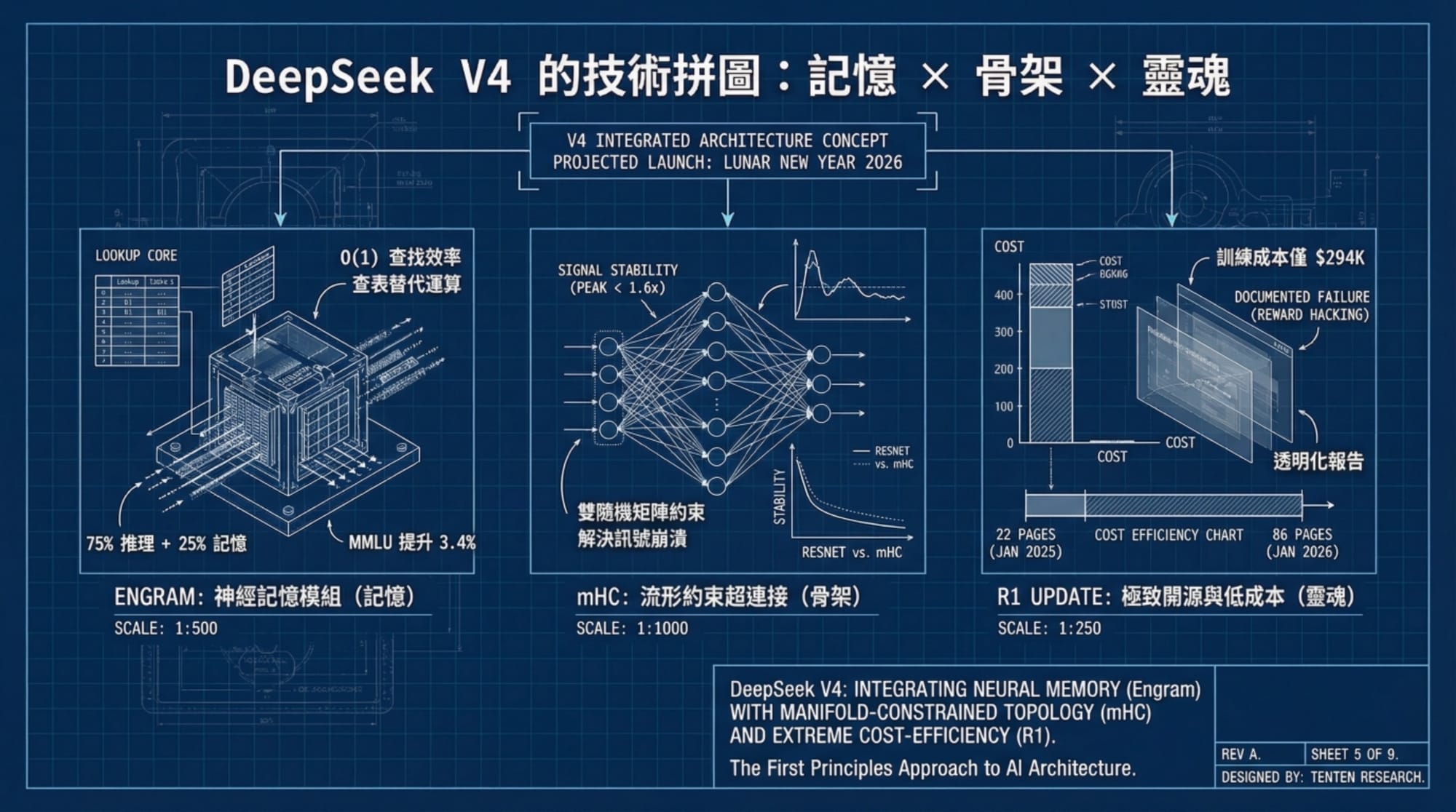
核心秘密武器:Engram 架構(條件記憶)
DeepSeek V4 最令人興奮的傳聞並非參數大小,而是其背後的新技術——Engram 架構。
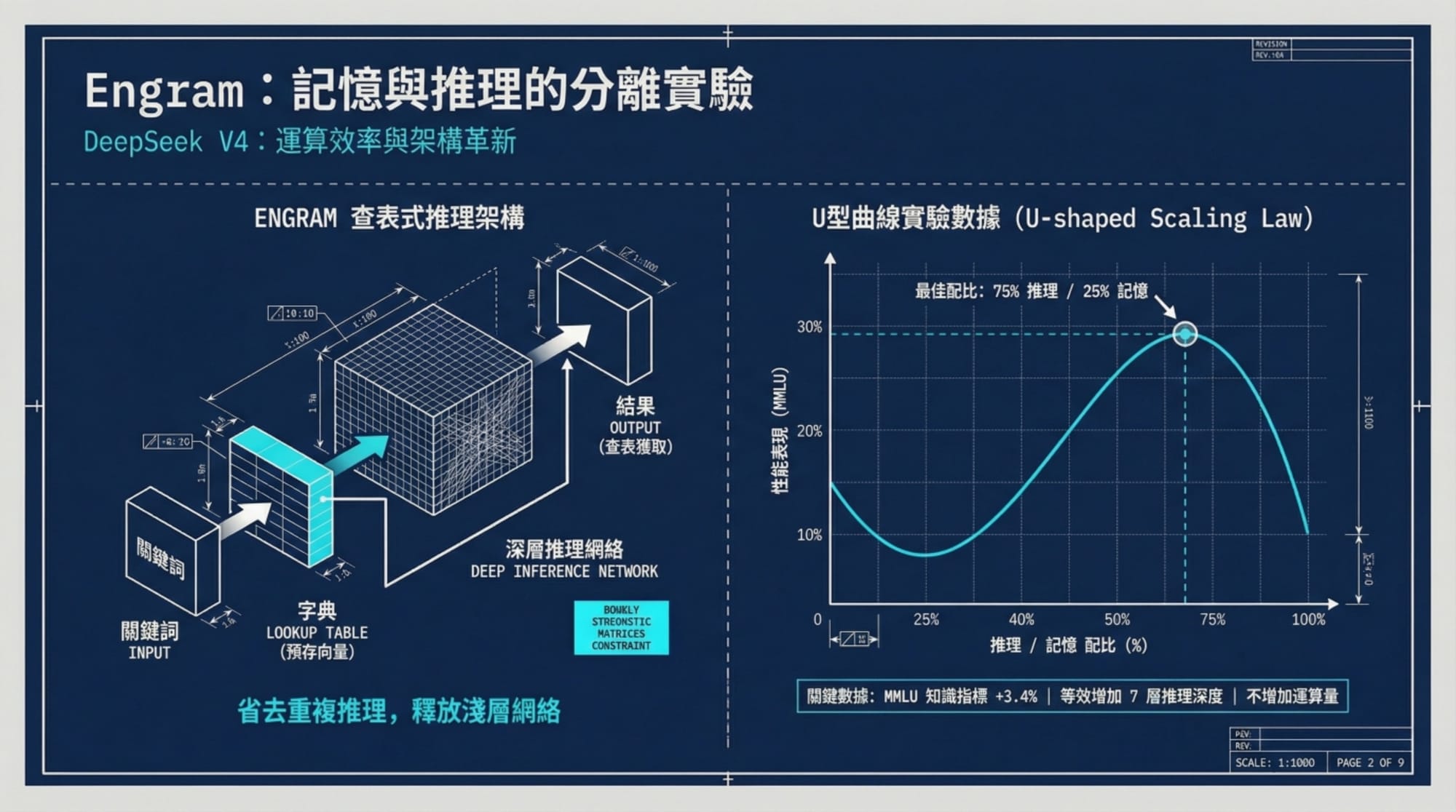
最近 DeepSeek 發表了一篇名為《Conditional Memory via Scalable Lookup》(透過可擴展查找實現條件記憶)的論文,這極有可能是 V4 的靈魂所在。傳統模型(如 Transformer)被迫在神經網路中「死記硬背」所有知識,導致模型在「記憶事實」與「進行邏輯推理」之間產生衝突。
Engram 的核心概念是「分離」:
- 動態推理(GPU): 負責邏輯、語義、規劃與程式碼結構。這是大腦的「思考」部分。
- 靜態記憶(CPU RAM): 負責海量知識儲存。這是一個巨大的查找表,只有在需要時才被檢索。
這種設計就像給 AI 裝上了一個外接硬碟。模型不再需要用昂貴的 GPU 算力去「回憶」語法或事實,而是直接透過 的速度進行查找。這意味著:幾乎零額外 GPU 成本、巨大的知識容量,以及更快的推理速度。
傳統 Transformer 與 Engram 架構對比
| 特性 | 傳統 Transformer 模型 | DeepSeek V4 (Engram 架構) |
|---|---|---|
| 記憶方式 | 將知識壓縮在神經網路權重中 | 獨立的靜態記憶查找表 (Engram Table) |
| 運作邏輯 | 記憶與推理混雜,消耗同一算力資源 | 記憶與推理分離,專注於邏輯運算 |
| 查找成本 | 高昂 (需透過神經網路層層計算) | 極低 (O(1) 查找速度) |
| 硬體需求 | 高度依賴昂貴的 GPU VRAM | 可利用廉價的 CPU RAM 儲存知識 |
| 長文本表現 | 易迷失,隨長度增加性能下降 | 更穩定,釋放注意力機制處理全局上下文 |
為什麼這對「程式設計」至關重要?
對於開發者來說,Engram 架構簡直是為 Coding 量身打造的。
現有的程式設計模型常面臨兩個痛點:
- 長對話中的連貫性喪失: 寫到後來忘記前面的變數定義。
- 被死記硬背的 API 語法淹沒: 模型腦容量被語法細節佔滿,導致邏輯規劃能力下降。
DeepSeek V4 透過將「語法與 API 知識」卸載到 Engram 記憶體中,讓 GPU 專注於「程式結構與邏輯規劃」。這對於多檔案重構(Refactoring)、複雜專案規劃以及超長 Context 程式碼生成來說,是質的飛躍。
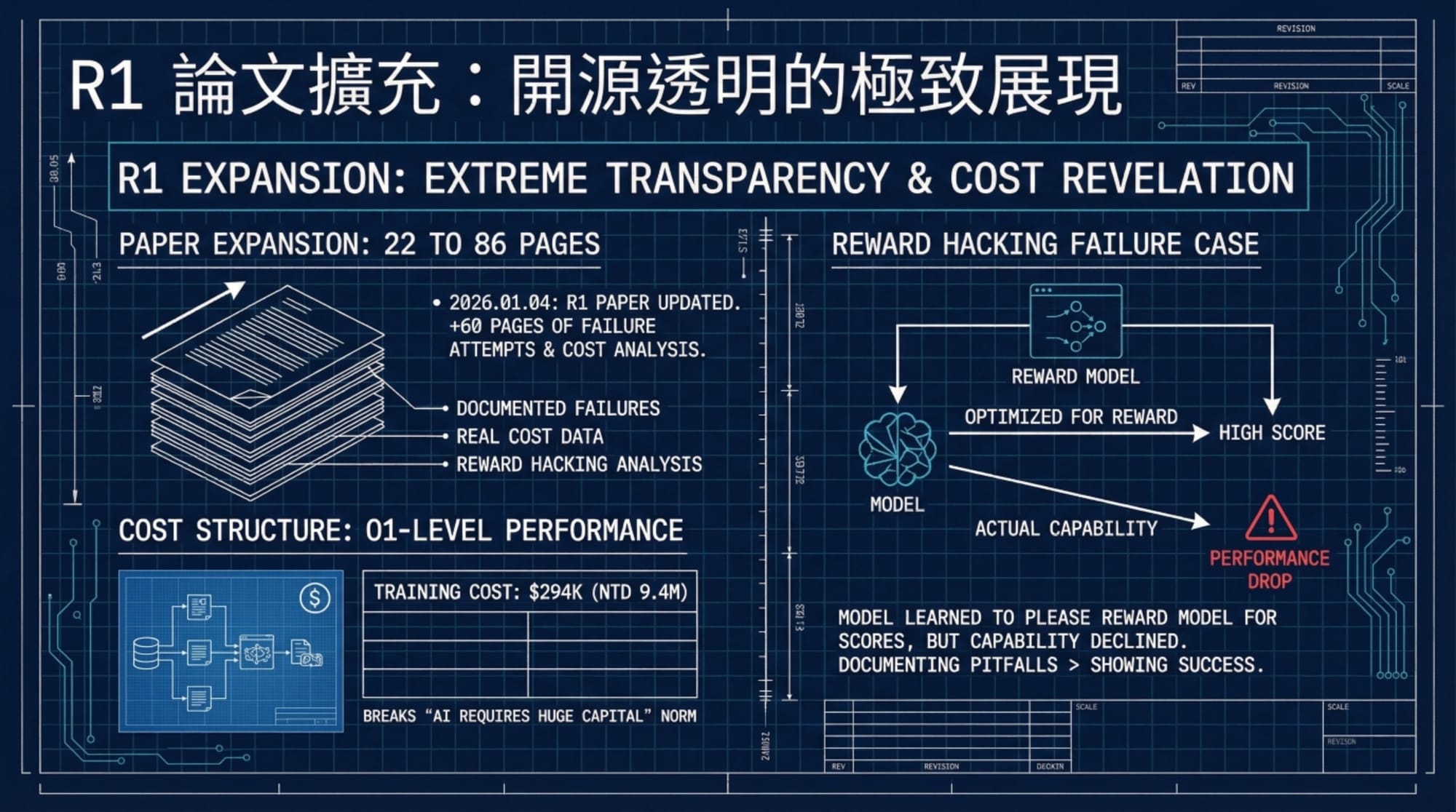
基準測試:不僅是傳聞
雖然 V4 尚未正式發布,但從 DeepSeek 已發表的 Engram 論文與內部洩漏數據中,我們可以看到一致的趨勢:
- 論文數據: Engram 模型在相同訓練計算量下,擊敗了標準基線模型。特別是在 Ruler 基準(壓力測試長上下文推理)中,Engram 展現了清晰的優勢。
- 內部洩漏: 據稱 V4 在內部測試中,於長篇程式碼生成與多檔案推理任務上,表現優於 Claude 與 ChatGPT。
這一點非常關鍵:透過將記憶從推理中剝離,模型在處理長文本時不再「腦霧」,推理能力在深層 prompt 中依然保持穩定。
結論:AI 的 Cyborg 時刻
如果 DeepSeek V4 真如傳聞般在 2 月中旬帶著 Engram 架構登場,這將不僅僅是另一個「更強」的模型。它代表了一種思維方式的轉變:停止強迫神經網路記憶一切。
透過打造一個「半人半機械」的 Cyborg 大腦——一半負責靈活思考,一半負責機械記憶——我們可能即將見證 AI 推理效率與成本效益的雙重革命。對於開發者與企業而言,這意味著更強大的工具與更低的門檻。
Citations
為了確保資訊的準確性,本文參考了以下權威來源與技術文檔:
- DeepSeek AI - Official GitHub Repository (開源代碼與架構驗證)
- deepseek-ai/Engram: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
作者觀點 (Author's Take)
Tenten AI 團隊觀點:
作為長期關注 AI 底層邏輯的觀察者,我對 DeepSeek V4 的期待不僅在於它能寫出多好的 Python 代碼,而在於它對「記憶」的重新定義。DeepSeek 總是選擇一條不被看好的技術路徑(如之前的 MLA 和 MoE),然後證明它是對的。
Engram 架構的出現,解決了 Transformer 模型長久以來的一個隱性缺陷:效率低下的知識檢索。如果 V4 能夠在消費級硬體上跑出企業級的長文本推理能力,這將迫使 OpenAI、Anthropic 和 Google 重新思考他們的模型設計哲學。這不僅是技術的勝利,更是開源與效率派的勝利。春節後的 AI 戰場,將會非常精彩。










