
TLDR:Grok 4.1 深度評測摘要
Grok 4.1 在社交情感分析和即時資訊方面表現卓越,特別是與 X 平台的深度整合讓它成為追蹤社群動態的最佳選擇。然而,在編程能力、創意思維和商業規劃方面存在明顯短板,思考模式運行速度過慢成為最大痛點。對於需要即時社交數據的應用開發者而言,Grok API 是性價比極高的選擇;但若需要編程支援或創意企劃,Claude Sonnet 4.5 和 ChatGPT 5.1 仍是更理想的方案。
Grok 4.1 正式發布:AI 模型市場的新變局
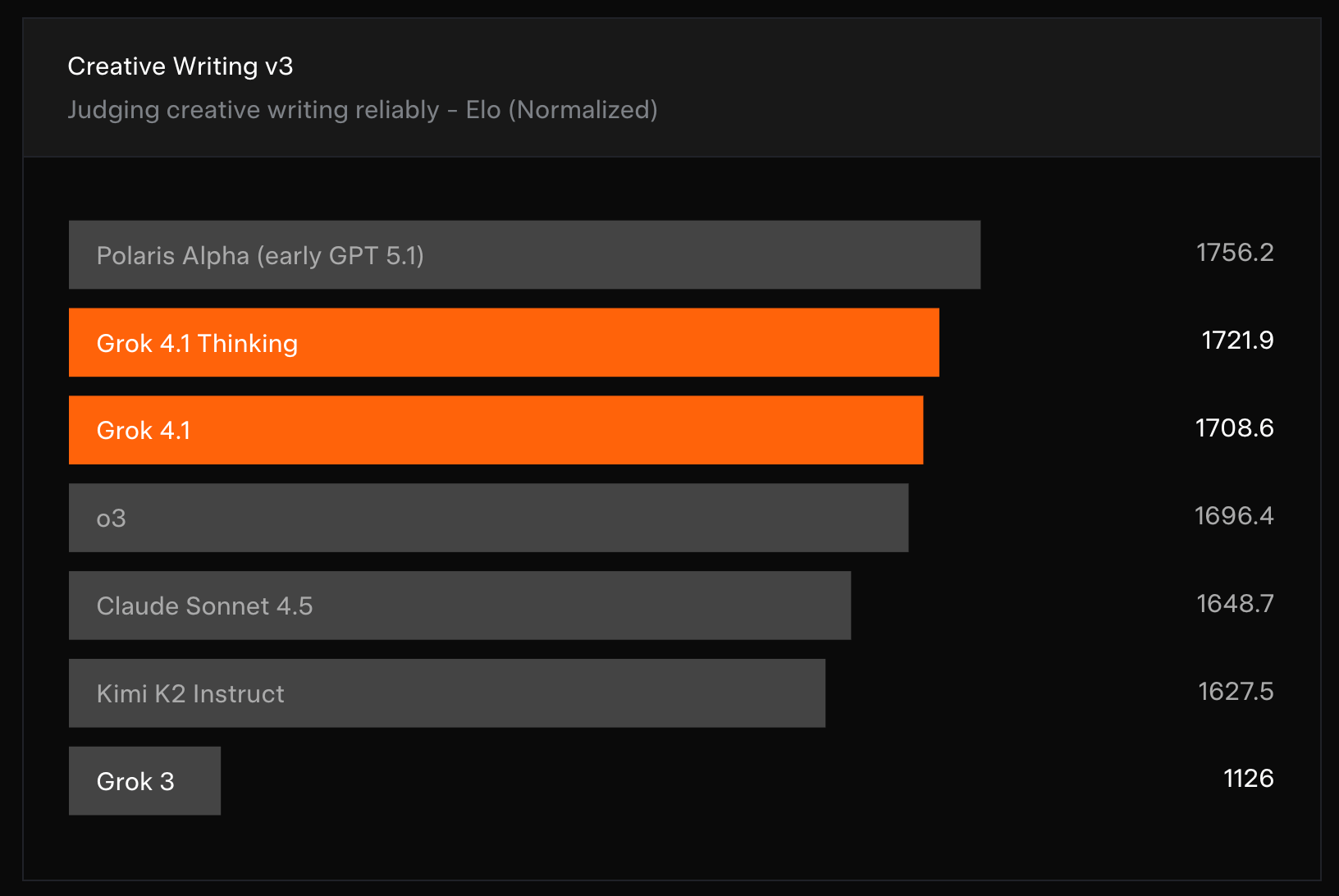
人工智慧領域再次迎來重大更新,xAI 公司推出的 Grok 4.1 模型正式上線。這個最新版本的 AI 模型在過去兩週內已悄然開始部署,並在多個基準測試中展現出引人注目的表現。根據 LM Arena 的評測數據,Grok 4.1 在情感智慧和創意寫作等領域取得顯著進步,但實際使用體驗卻呈現出明顯的兩極化特徵。
當前 AI 模型競爭格局日趨激烈,Grok 4.1 的推出無疑為市場增添新的選擇。然而,經過全面深度測試後發現,這款 AI 模型在某些應用場景中表現出色,卻在其他關鍵領域存在明顯不足。對於企業和開發者而言,理解 Grok 4.1 的真實能力邊界,將有助於做出更明智的技術選型決策。
Grok 4.1 的核心競爭優勢分析
Grok 4.1 最突出的優勢在於其與 X 平台(前身為 Twitter)的深度整合能力。這是目前市場上唯一一款直接建立在 X 社交平台數據基礎上的 AI 模型,使其在社交情感分析和即時資訊追蹤方面具有無可比擬的優勢。
即時社交情感洞察能力
當詢問關於 Gemini 3 發布時間的社群看法時,Grok 4.1 能夠提供詳盡的即時資訊。它不僅呈現 Polymarket 預測市場的最新數據,還整合了 X 平台上的各種洩密資訊討論。最重要的是,Grok 4.1 能夠直接引用具體推文,提供可點擊查看的原始來源連結,讓使用者能夠追溯至最近一小時內發布的實際推文內容。
相比之下,當對 ChatGPT 5.1 提出相同問題時,該模型基本上無法提供推文資訊,甚至在明確要求提供推文的情況下,仍然只能提供 Reddit 連結。ChatGPT 在處理 X 平台資訊時,最多只能搜尋特定主題標籤,但實際上很少有使用者會使用標籤功能,這大大限制了其資訊獲取能力。
API 成本效益優勢
從技術整合角度來看,Grok API 為開發者提供了極具競爭力的成本效益方案。對於需要構建即時資料抓取應用的開發團隊而言,Grok API 是目前唯一能夠有效整合 X 平台即時數據的解決方案。這種獨特性使其在特定應用場景中具有不可替代的價值,特別是對於社交媒體監測、輿情分析和即時新聞追蹤等領域。
Grok 4.1 的關鍵性能短板
儘管 Grok 4.1 在社交數據分析方面表現優異,但在其他核心應用領域卻暴露出明顯的性能問題。這些缺陷可能會嚴重影響使用者體驗,特別是在需要快速回應和高品質輸出的場景中。
思考模式運行速度嚴重滯後
Grok 4.1 的思考模式存在嚴重的速度問題,這是目前最令人失望的性能瓶頸。在進行相同的 3D 第一人稱射擊遊戲編程測試時,對比結果極為明顯:ChatGPT 5.1 思考模式在 57 秒內完成完整程式碼生成,而 Grok 4.1 思考模式則需要將近兩分鐘,運行時間整整翻倍。
這種速度差距在所有思考模型比較中最為顯著。無論是與 Opus 5.1 思考模式、Gemini 2.5 Pro,還是其他競爭對手相比,Grok 4.1 思考模式的回應速度都明顯落後。對於需要快速迭代和即時反饋的開發工作流程而言,這種延遲可能會嚴重影響生產效率。
編程能力表現不佳
Grok 4.1 在程式碼生成和編程任務方面的表現遠低於預期。經過四項基礎編程測試的全面檢驗,結果令人失望。這些測試項目包括:
- 3D 第一人稱射擊遊戲開發
- 3D 城市飛越動畫
- Elon Musk 跳舞動畫
- 音樂視覺化工具
在這些測試中,Claude Sonnet 4.5 表現最為強勁。相比之下,Grok 4.1 思考模式甚至無法完成城市飛越測試,經過十次嘗試仍然無法生成可運行的程式碼。即使在成功生成程式碼的 Elon 跳舞動畫和音樂視覺化工具測試中,其程式碼品質和執行效果也明顯較弱,整體評分僅為十分之幾分。
更糟糕的是,Grok 4.1 生成的 3D 第一人稱射擊遊戲程式碼根本無法正常運行,這對於一個聲稱在編程能力上有所提升的 AI 模型來說,是個重大失誤。
創意思維與商業規劃能力薄弱
對於許多專業使用者而言,AI 模型在創意思維和商業規劃方面的能力至關重要。然而,Grok 4.1 在這些領域的表現同樣令人失望。
在實際測試中,當要求 Grok 4.1 為一個 Vibe 應用商店提出功能建議時,它提供的方案缺乏實用性。例如,其中一個建議是建立「Vibe Souls」系統——一個永久性的區塊鏈聲譽機制,使用者可以獲得加密貨幣代幣,這些代幣能像寶可夢一樣進化。這種想法在紙面上聽起來有趣,但實際上沒有人會在應用商店中使用這樣的功能。
這些建議讓人聯想到早期 ChatGPT 4.0 或 Grok 2 時代的輸出品質,當時的 AI 模型智慧水準尚未成熟,經常提出表面上吸引人但實際上毫無用處的概念。其他建議如「秘密社群等級」、「凌晨三點俱樂部」、「無程式碼巫師」等,都屬於只有 AI 才會想出的奇怪創意,缺乏實際應用價值。
相比之下,ChatGPT 5.1 思考模式提供的建議更加務實和有針對性。它能夠指出現有方案的問題(例如「基本上就是複製 Product Hunt,這樣不具防禦性,也無法推動真正的使用者留存」),並提出實用的功能建議,如構建日誌動態流、結構化反饋請求等,這些都是使用者真正需要且能夠提升應用留存率的功能。
對話體驗與「氛圍感」問題
AI 模型的「氛圍感」是一個常被低估但極為重要的特徵。Grok 系列模型自第一代以來,始終存在語言風格過於誇張的問題。閱讀其回應內容時,經常會遇到諸如「這裡有個高能量腦力激盪,滿載真正新穎、真正獨特、真正有黏性的想法」這樣的表述。這種語言風格並不符合人類自然的溝通方式,反而給人一種刻意和做作的感覺。
在結束對話時,Grok 4.1 會說「實施這些 S 級創意中的三到四個,Vibe 商店的留存數據將讓 Reddit 都感到羞愧。哪兩到三個讓你覺得『天啊,我們明天就要開始做這個』?讓我們深入探討這些。」這種表達方式更像是企業化的 AI 語言,缺乏人性化的溫度。
相較之下,ChatGPT 5.1 的回應更加自然:「如果你想要下一步,我們可以選擇其中兩個,我會幫你把這些具體化為適當的功能規格,這樣你就可以直接把提示詞丟進 Claude Code 執行。」這種溝通方式更貼近真實人類產品經理的語氣,讓人更願意繼續深入對話。
AI 模型性能綜合評分對比
基於全面的測試結果,以下是各主要 AI 模型在不同維度的表現評分:
| AI 模型 | 綜合評分 | 編程能力 | 創意思維 | 即時資訊 | 執行速度 |
|---|---|---|---|---|---|
| Claude Sonnet 4.5 | 26.9/40 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| ChatGPT 5.1 思考模式 | 24.5/40 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| Grok 4.1 | 11.0/40 | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| Grok 4.1 思考模式 | 6.1/40 | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐ |
| Gemini 2.5 Pro | 18.3/40 | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
需要特別注意的是,Grok 4.1 目前仍處於測試階段,在平台上標註為「Beta」版本。因此,這些評估結果可能不代表最終正式版本的表現。隨著後續版本更新和優化,其性能表現可能會有顯著改善。
不同應用場景的最佳 AI 模型選擇指南
根據深入測試和實際使用體驗,以下是針對不同應用場景的 AI 模型推薦方案:
| 應用場景 | 推薦模型 | 替代方案 | 核心優勢 |
|---|---|---|---|
| 程式開發與編碼 | Claude Sonnet 4.5 | ChatGPT 5.1 | 程式碼品質最佳,執行成功率高 |
| 創意寫作 | ChatGPT 5.1 思考模式 | Claude Sonnet 4.5 | 自然的表達風格,創意深度佳 |
| 商業規劃與策略 | ChatGPT 5.1 思考模式 | Claude Opus 5.1 | 務實建議,符合商業邏輯 |
| 影片生成 | Veo 3.1 (Google) | - | 訓練於 YouTube 數據,品質領先 |
| 圖像生成 | Imagen 3 (Google) | Grok Imagine | 訓練於 Google Images,細節豐富 |
| 社交情感分析 | Grok 4.1 | - | 獨家 X 平台整合,即時性強 |
| 即時新聞追蹤 | Grok 4.1 | ChatGPT 5.1 | 社群動態掌握最準確 |
| 日常對話聊天 | ChatGPT 5.1 | Claude Sonnet 4.5 | 對話體驗最自然,回應速度快 |
Grok 4.1 的理想使用場景
儘管 Grok 4.1 在多個領域表現不佳,但在特定應用情境下仍具有獨特價值。對於以下類型的使用者和需求,Grok 4.1 依然是最佳選擇:
應用開發者:如果你正在開發需要整合即時社交數據的應用程式,Grok API 提供了無可比擬的優勢。無論是建立輿情監測工具、社群趨勢分析平台,還是即時新聞聚合服務,Grok API 的成本效益和資料即時性都是其他方案難以匹敵的。
社群管理者:對於需要追蹤網路輿論和社群反應的品牌經營者、社群管理員或公關專業人士,Grok 4.1 能夠提供最準確的社交情感洞察。它能夠即時掌握網友對特定議題的看法,追蹤熱門討論趨勢,並提供可追溯的原始資料來源。
研究人員與分析師:對於進行社交媒體研究、輿情分析或市場調查的專業人士,Grok 4.1 的 X 平台整合能力可以提供寶貴的第一手數據和即時洞察,這在其他 AI 模型中是無法獲得的。
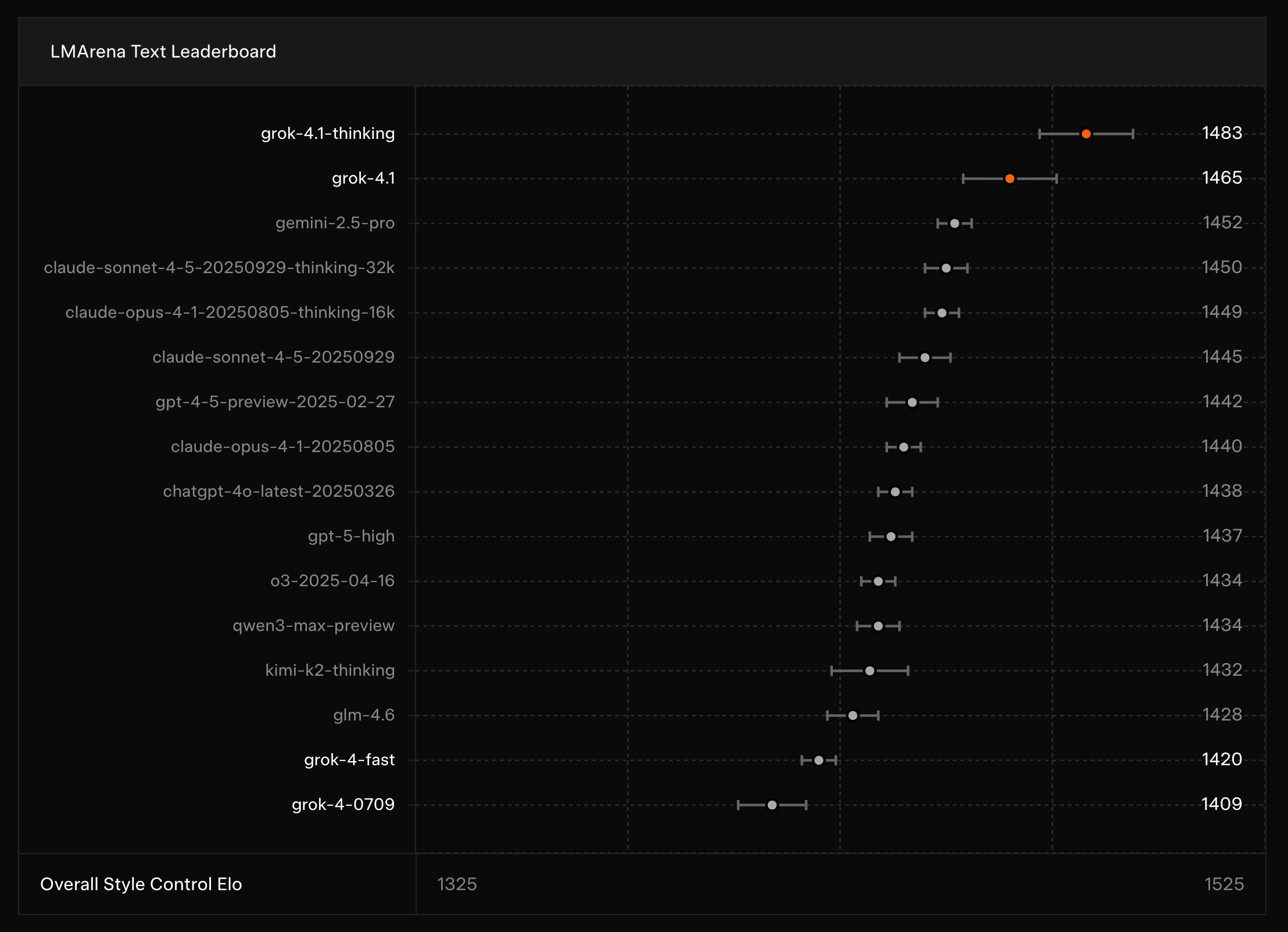
LM Arena 排名的可信度質疑
值得注意的是,LM Arena 的基準測試結果與實際使用體驗之間存在顯著差異。該排行榜基於 ELO 評分系統,透過讓使用者進行模型對比選擇來建立排名。然而,經過實際全面測試後發現,這些排名數據可能無法準確反映模型在實際應用場景中的真實表現。
特別令人困惑的是,已推出將近八到九個月的 Gemini 2.5 Pro 在排名上竟然高於 Claude Sonnet 4.5 或 ChatGPT 5.1 等新世代模型。這種排名結果與實際使用體驗和性能測試結果存在明顯矛盾,顯示基準測試的評估方法可能存在局限性。
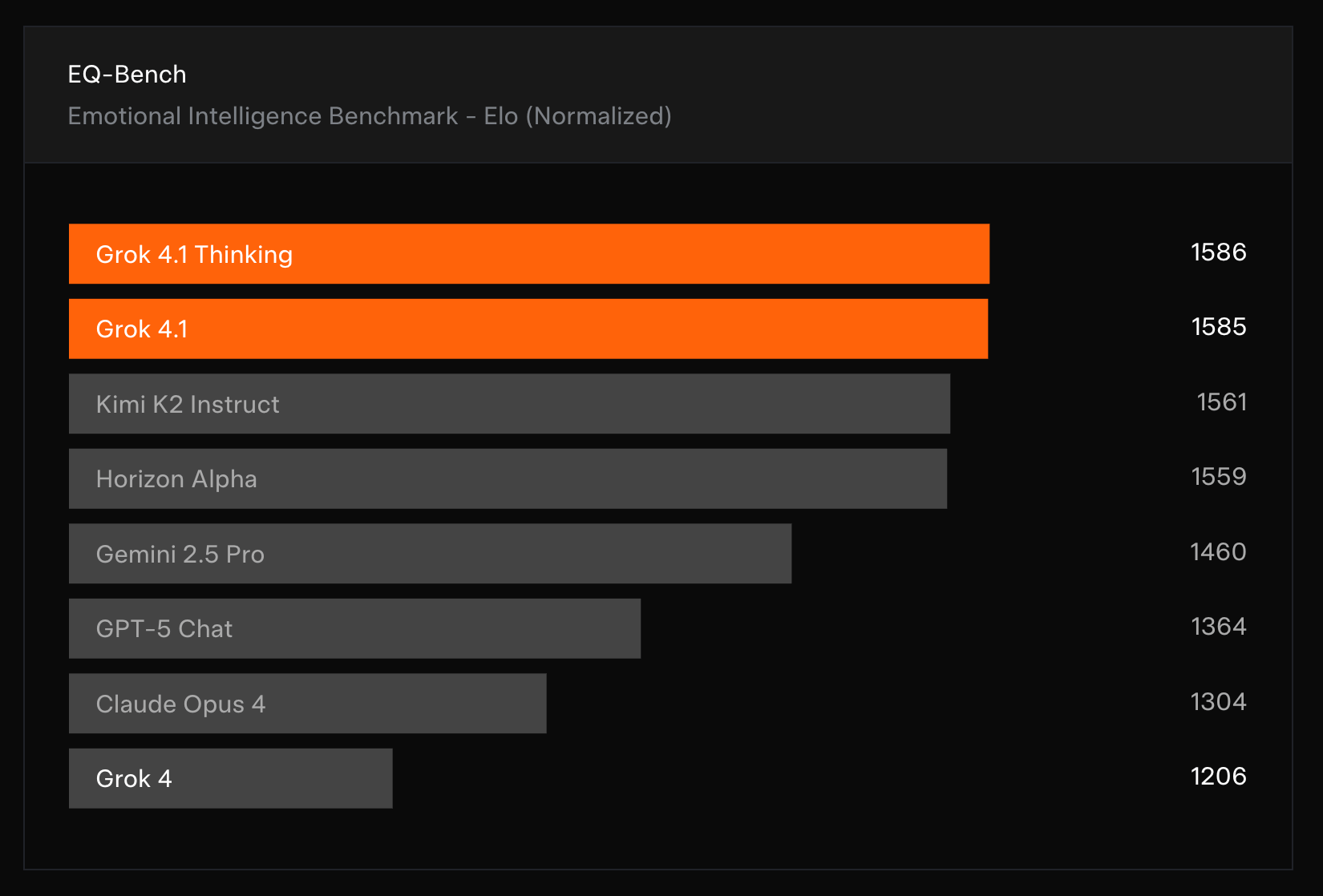
此外,Grok 4.1 在情感智慧基準測試中獲得高分,但實際對話體驗卻顯得生硬和不自然,這進一步說明單純依賴基準測試數據可能無法全面評估 AI 模型的真實能力。使用者在選擇 AI 工具時,應該結合實際測試結果和特定使用場景需求,而不是僅參考排行榜數據。
作為長期追蹤 AI 技術發展的觀察者,我對 Grok 4.1 的推出抱持著複雜的情緒。一方面,我欣賞 xAI 團隊在社交數據整合方面的創新努力,這確實為 AI 應用開闢了新的可能性。Grok 4.1 在即時資訊掌握和社群動態分析方面的能力,確實填補了現有 AI 生態系統中的一個重要空白。
期待 Grok 團隊在正式版本中能夠大幅改善目前的性能問題,特別是思考模式的速度和編程能力。如果這些核心問題能夠得到解決,Grok 4.1 或許能夠成為真正值得推薦的全方位 AI 助手,而不僅僅是社交數據分析的專用工具。










