
Google 剛正式推出新一代大型模型 Google Gemini 3,同時在 Search、Gemini App、企業雲端和開發者平台全面上線,並搭配像 Deep Think、Google Antigravity 等新工具,整體戰場就是「跟 OpenAI 正面對撞的一次大升級」。
TL;DV:Google Gemini 3 重點總覽
- Google 推出全新旗艦模型 Google Gemini 3,主打「目前最聰明的模型」,在推理、程式碼生成、多模態理解上全面超過 Gemini 2.x。
- 第一波先釋出 Gemini 3 Pro(預覽版),直接進入 Gemini App、AI Mode in Search、Vertex AI 和 Gemini Enterprise 等產品。也就是說,你日常搜尋、問答、寫程式都會慢慢被它接手。
- 新增 Gemini 3 Deep Think 模式,專門強化「深度推理」,在高難度考題與推理基準測試上,把前一代 Gemini 2.5 和其他對手通通壓過去,但會比較慢、比較吃算力,只先給付費高階訂閱用戶。
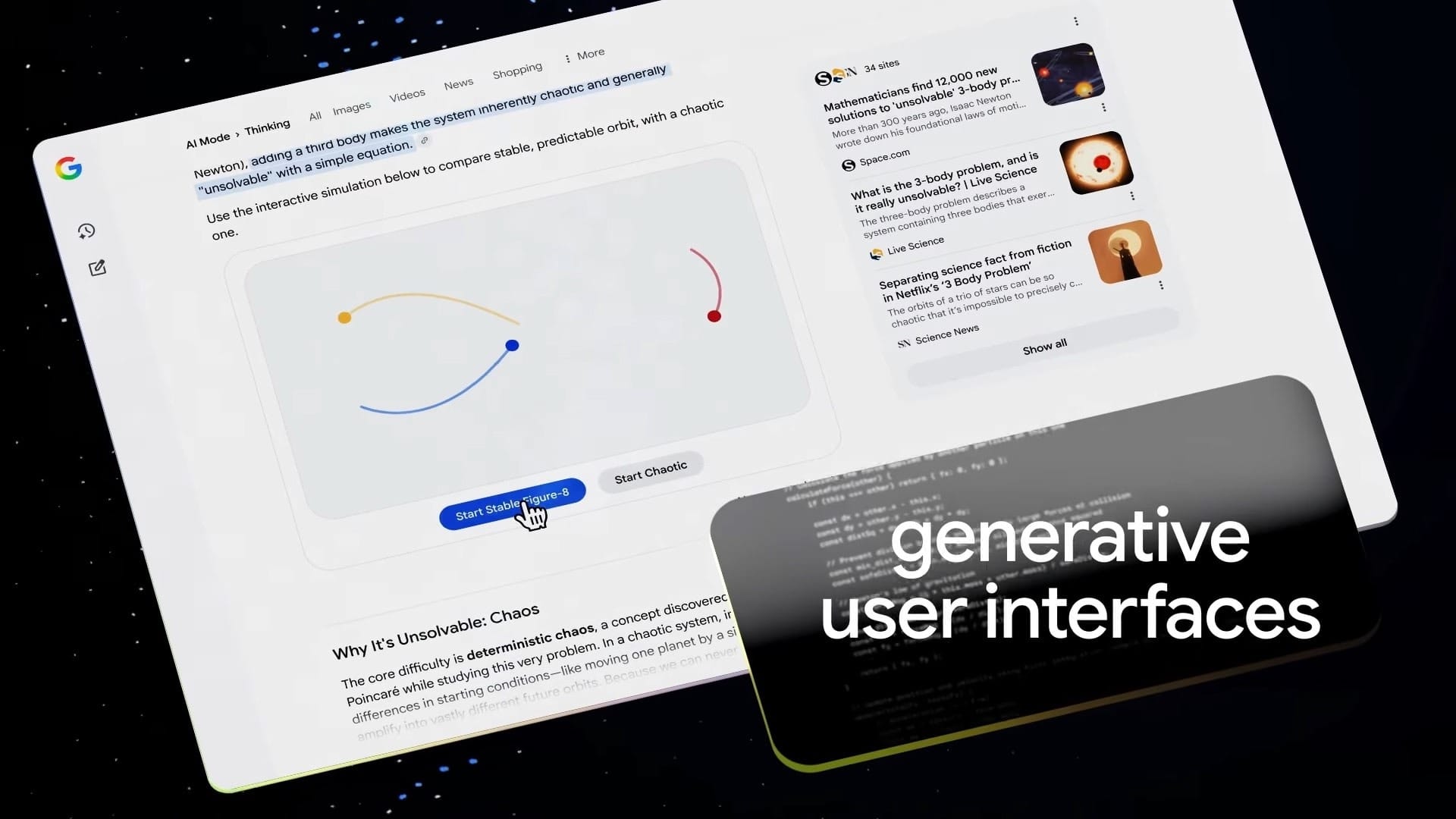
- Search 的 AI Mode 現在一出生就綁定 Gemini 3,提供更動態、可互動的答案與小工具(例如情境模擬、計算器、教學互動介面)。
- Google 同步宣布全新的 agentic 平台 Google Antigravity,讓開發者可以用 Gemini 3 打造類似「AI Agent / 自動代理人」的應用。這是它們對 AI Agent 浪潮的正式回應。
- 開發者端則持續升級 Gemini API:File Search API、multi-tool use、Live API 的非同步 function call 等,讓模型可以查檔案、用工具、即時互動,變得更像一個「能幹活」的 AI 程式助手。
- 社群普遍認為:Gemini 3 在推理與 benchmark 上超強,特別是數理與程式實作;但大家也在觀察實際使用體感會不會像 Google 說的那樣「少拍馬屁、多講重點」。
Google Gemini 3?
Google Gemini 3 是 Google 目前最新一代的通用大型模型家族,官方直接說這是它們「有史以來最聰明的模型」,核心賣點是更強的推理能力、對複雜任務的拆解能力,以及更穩定的多模態理解。
在演進路線上,Gemini 1.0 解決的是多模態與長上下文,Gemini 2.0 加強推理並開始嘗試 agentic 能力,Gemini 2.5 深化推理與程式碼,現在 Gemini 3 則是把這些能力「合體」,並明確定位成「可以把任何想法變成實作」的創作與工作引擎。
根據多家科技媒體與 Google 自家 Blog 的說法,Gemini 3 在理解使用者意圖上更敏銳,需要的提示更少,也比較能抓到問題背後的「真正需求」,這對一般使用者和開發者都是很實際的升級。這與目前生成式 AI 領域的發展趨勢一致,各家都在追求更自然、更貼近人類思維的互動模式。

發佈時間與可以在哪裡用?
Google 在 2025 年 11 月中正式公開 Gemini 3,並從 11 月 17–18 日起分批推送到自家服務與訂閱用戶,這次節奏非常快,幾乎是發表就直接上線。
目前已知 Gemini 3 Pro 先以預覽版形式提供給 Gemini App 用戶、Search 中的 AI Mode、以及 Google 雲端中的 AI Studio 和 Vertex AI,企業版用戶則透過 Gemini Enterprise 方案接觸到這一代模型。
媒體報導指出,付費的高階 AI 訂閱用戶會優先拿到更高使用額度與更進階的功能(包含 Deep Think),免費用戶則會在 Search 與 Gemini App 中逐步體驗到基礎版能力。這種「分層釋出」的做法,顯然是為了與其他家高階模型訂閱方案競爭。
Gemini 3 Pro 與 Deep Think 有什麼厲害?
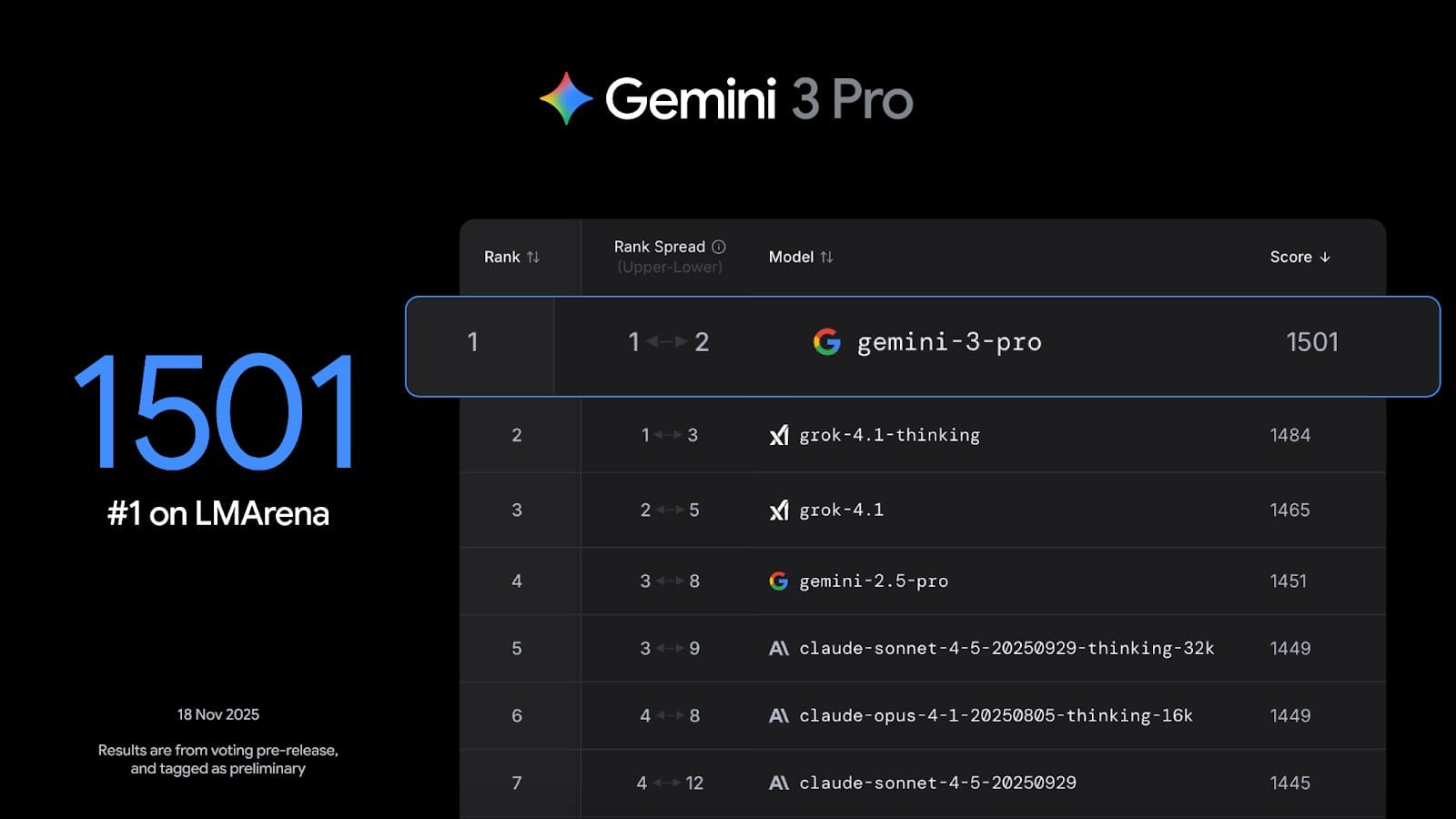
Gemini 3 Pro 是這一代家族中第一個公開的旗艦模型,專門針對難題推理、寫程式、數學與多模態任務做了大幅提升,在多個學術與綜合 benchmark 上都超越前一代 Gemini 2.5 Pro。
在第三方評測平台 LMArena 上,Gemini 3 Pro 的分數來到 1501,明顯高於 Gemini 2.5 Pro 的 1451,並在高難度推理測試上展現接近「博士等級」的表現。這代表它在解決複雜數理與跨領域問題時的可靠度有明顯進步。
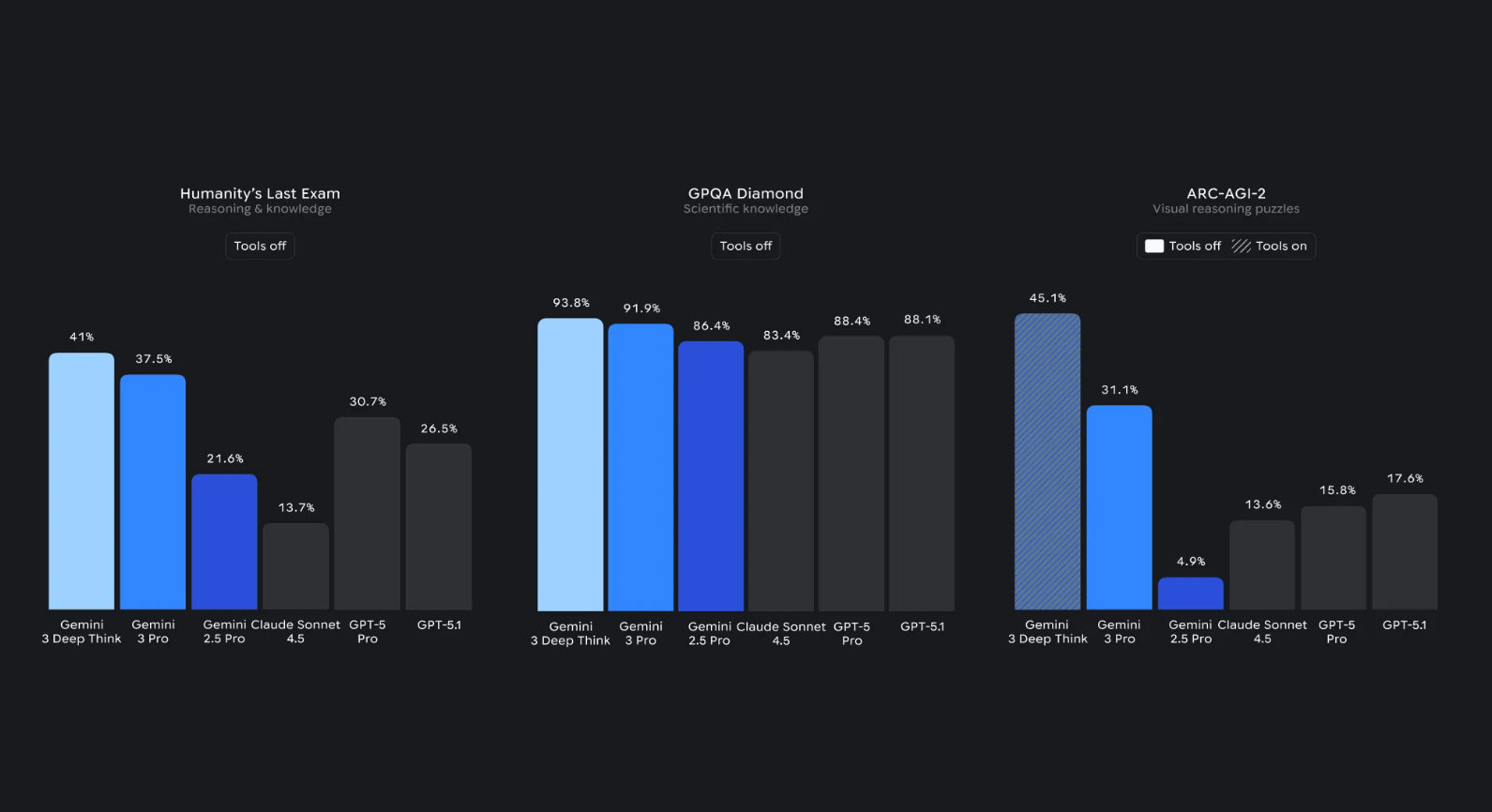
Deep Think 則是這次很吸睛的「深度推理模式」,簡單講,就是讓模型在回答前花更多計算資源思考與驗證,換來更高的正確率。官方數據顯示,Deep Think 在像 ARC-AGI、GPQA Diamond 這種高難度推理基準上有史無前例的成績,明顯壓過一般版本的 Gemini 3 Pro。這讓我想起人工智慧的認知革命,我們正見證 AI 從簡單的模式識別進化到真正的推理思考。
Google Gemini 3 不同方案與用途一覽
下面用表格大概整理 Gemini 3 相關版本與定位(名稱保持英文):
| 版本 / 工具 | 主要定位與用途 |
|---|---|
| Gemini 3 Pro | 通用旗艦模型,強調推理、程式碼、多模態理解,適合一般使用者與開發者。 |
| Gemini 3 Deep Think | 強化深度推理的模式,適合解高難度考題、研究型問題,主要提供給高階訂閱與企業客戶。 |
| Gemini Enterprise 中版本 | 給企業用的 Gemini 3,整合 Workspace、雲端與資料治理等需求。 |
| AI Mode in Search 中版本 | 搜尋中的 Gemini 3,提供互動式答案與小工具,面向大眾用戶。 |
| Google Antigravity | 基於 Gemini 3 的 agentic 開發平台,用來打造 AI Agent 與自動化工作流程。 |
這些版本背後共通的核心就是同一代 Google Gemini 3 架構,只是在速度、成本、功能限制和安全保護層上做不同配置,以便服務從一般用戶到企業與開發者的不同情境。
一起登場的其他 AI 工具與平台
這次不只是丟出一個模型,Google 也把整個 AI 產品線往前推了一大步,包括 Search、企業雲和開發平台。AI Mode in Search 直接綁定 Gemini 3,新增更豐富的互動 UI,例如可以動態產生計算工具、模擬器或教學情境。這讓搜尋不再只是「給你十個連結」,而是「直接給你會動的答案」。這種轉變也呼應了從 SEO 到 GEO 的搜尋引擎優化新趨勢。
Google Antigravity 則被描述成一個「agentic development platform」,核心概念是讓開發者用 Gemini 3 來編排多個工具與流程,打造能主動幫你完成任務的 AI Agent,例如自動查資料、寫程式、調用內外部 API 等。這呼應了業界 AI Agent 趨勢,也讓 Gemini 3 不只是聊天,而是能做事。
另外,在研究線上,Google DeepMind 先前發表了 Genie 3 這個 world model,可以產生互動式的虛擬環境,用於教育、訓練和模擬,雖然跟 Gemini 3 是不同產品線,但一起透露出 Google 想要用各種模型組成「AI 系統群」的策略。未來這些世界模型與通用語言模型之間的整合,值得持續關注。
開發者視角:Gemini API 最新進展
對工程師來說,Google Gemini 3 的重要性不只是模型本身,而是整條 API 與工具鏈的升級。Google 最近在 Gemini API 的 release notes 中,釋出 File Search API(可以讓模型對你的私有文件做檢索與回答)、multi-tool use(在同一個請求中組合 search、code execution 等工具)、以及 Live API 的非同步 function 呼叫等能力。這些都讓基於 Gemini 的應用更像一個「會工作」的 AI 助理。
此外,Google 也持續推出像 Gemini 2.0 Flash、Gemini 2.0 Flash Thinking、以及開源系的 Gemma 3 系列,讓開發者可以在不同成本與延遲需求下選擇合適模型。這些更新雖然不是 Gemini 3 本體的一部分,但在實際專案中往往會與 Gemini 3 一起搭配使用。這代表 Google 正把整個模型家族打造成一個完整的技術平台。
對於已經在用 Vertex AI 或 Gemini API 的團隊來說,升級到 Gemini 3 意味著可以在不大改架構的情況下,直接享受推理與程式能力的提升,同時還能利用新的工具組合設計更複雜的 workflow。
AI 戰局:Google 為何這麼拼 Gemini 3?
多家財經與科技媒體都把 Gemini 3 的發佈解讀成「Google 對 OpenAI 及其他競爭對手的一次正面迎戰」。這次 Google 沒有先藏在實驗室或小範圍測試,而是直接把最新模型放進 Search、App 和企業雲,顯然是要告訴市場:它在生成式 AI 戰場上還是很有競爭力。
CNBC、Bloomberg 等報導都提到,Google 把 Gemini 3 的戰略定位在「一次性滲透所有主要產品線」,好比把同一顆新引擎拆成不同版本裝進 Search、Workspace、Cloud 和消費級 App 裡。這種打法,一方面是回應投資人對 AI 變現的期待,一方面也是要避免被競品搶走預算和開發者心智。
Fortune 等媒體則指出,這次 Gemini 3 上線前有一波社群預熱與「半公開」的測試與爆料,讓期待值被慢慢堆高,正式發表時又搭配訂閱制與企業方案的升級,整體看起來就是一場精心安排的商業與行銷操作。
實際影響是什麼?
如果你只是一般 Search 和 Gemini App 使用者,最直覺的變化就是:AI 回答會變得更「會想」,也更「會互動」。在 Search 的 AI Mode 裡,你可能會看到可以直接操作的介面(例如試算、模擬、拆解步驟),而不是一大段純文字摘要。這會讓搜尋更像是在跟一個家教或顧問對話。
對工程師與創作者來說,Gemini 3 更強的程式能力與多模態理解,可能代表你可以更放心地丟給它複雜的專案架構、數學推導或多格式資料,讓它協助設計、除錯和生成內容。許多媒體也提到,這一代模型在生成程式碼的正確性與可維護性上有明顯提升。就像我們在AI 開發工具比較中看到的,好的 AI 編碼助手能大幅提升開發效率。
當然,能力提升也伴隨風險增加。Newsweek 報導中提到,Google 高層在談 Gemini 3 時仍然強調安全與濫用風險,提醒大家對高度自動化的 AI Agent 和深度推理模型要保持警覺,尤其是在金融、醫療或高風險決策領域。簡單講,Gemini 3 可以做更多事,但也更需要負責任地使用。
你該繼續關注什麼?
Gemini 3 的發佈只是一個起點,接下來還有很多值得觀察的面向:
首先是 Google 能不能真的讓 Gemini 3 成為開發者首選。畢竟模型再強,也要搭配好用的 API、穩定的服務和合理的價格,才能讓更多團隊願意從其他平台轉過來。這次 Google 主打 API 工具鏈與企業方案的升級,就是想建立一個「黏著度」更高的生態系。
其次是實際落地後的用戶體驗。現在 Gemini 3 還在預覽階段,真正大規模應用後會不會遇到穩定性問題、幻覺率是否降低、對長上下文的處理有沒有達到預期,這些都需要時間驗證。社群的實測與回饋會是很重要的參考指標。
最後,是競爭對手的反應。OpenAI、Anthropic、xAI 等公司肯定不會坐視不管,接下來幾個月內可能會有一波新的模型或功能更新,讓整個大型語言模型市場進入更激烈的軍備競賽。對使用者來說,這是好事——選擇更多,技術進步更快,價格也可能因為競爭而下降。
Gemini 3 Pro 與其他頂尖模型的完整比較
說到 Gemini 3 Pro 的 benchmark 表現,很多人第一個想知道的就是:它跟目前市面上最強的其他模型比起來到底如何?尤其是跟 GPT-5.1、Claude Sonnet 4.5、Grok 4.1 和 Kimi K2 Thinking 這幾個「一線選手」擺在一起,誰會是真正的王者?
這個問題沒有絕對答案,因為不同模型在不同任務和情境下都有各自的優勢。不過,我們可以從幾個最重要的 benchmark 來看出大致的實力分佈。
當前頂尖模型的戰力輪廓
先從整體格局來看。目前在推理、程式碼生成和多模態理解這三大核心能力上,公認的第一梯隊包含:
- Gemini 3 Pro:Google 最新旗艦,主打推理與多模態
- GPT-5.1 Thinking:OpenAI 的最新迭代,強調動態推理
- Claude Sonnet 4.5:Anthropic 的實戰派,特別擅長 coding 與電腦操作
- Grok 4.1:xAI 的聊天與推理模型,情感理解能力突出
- Kimi K2 Thinking:Moonshot AI 的深度推理模型,長鏈推理與工具使用極強
這五個模型各有千秋,沒有誰能在所有維度都壓倒性勝出。實際選型時,更重要的是看你的使用場景與需求。
關鍵 Benchmark
在學術型推理測試中,例如 Humanity's Last Exam 這種「超高難度考試」,目前的排名大致是:
Kimi K2 Thinking 在某些設定下可以拿到 44.9% 的驚人成績,展現出強大的長鏈推理能力。Grok 4.1 在 text-only subset 約有 38.6%,Gemini 3 Pro 則在完整 HLE 測試中達到 37.5%。GPT-5.1 Thinking 和 Claude Sonnet 4.5 在這項測試上的表現相對保守,但這不代表它們整體實力較弱,只是側重點不同。
在實戰 coding benchmark 方面,特別是 SWE-bench Verified 這種「真實 GitHub issue 修復」的測試,目前最穩的王者是 Claude Sonnet 4.5,標準模式達 77.2%,平行推理模式更可衝到 82.0%。GPT-5.1 Thinking 緊追在後約 76.3%。這兩個模型在軟體開發與 DevOps 場景特別吃香。
Gemini 3 Pro、Grok 4.1 和 Kimi K2 Thinking 在這個基準上的公開數據還不夠密集,所以如果你主要是做軟體開發,現階段可能還是優先考慮 Claude 或 GPT-5.1。
Gemini 3 Pro benchmark 對照表(跟 GPT-5.1、Claude 4.5、Grok 4.1、Kimi K2)
說在前面:不同團隊的 benchmark 設定(full set vs text-only、有沒有用工具)都不完全一樣,所以這張表比較適合作為「戰力大方向」參考,而不是嚴格的排行榜。
| 模型 / Benchmark | Humanity's Last Exam (HLE) (no tools, %) | SWE-bench Verified (%) | OSWorld (%) | MMMU / MMMU-Pro (%) | MathArena Apex (%) | 其他公開亮點 |
|---|---|---|---|---|---|---|
| Gemini 3 Pro | 37.5(full HLE,無工具;Google 自報) | 未見明確官方數字 / 第三方尚少 | 暫無公開明確分數 | 81.0(MMMU-Pro,多模態推理) | 23.4(MathArena Apex,高難數學) | LMArena Elo 1501,目前 text arena 頂端之一;GPQA Diamond 91.9%;SimpleQA Verified 72.1% 等多項 SOTA。 |
| GPT-5.1 Thinking | 約 26.5(社群依據 Scale / HLE 結果整理,具體設定可能略異) | 76.3(OpenAI 公布,Thinking 模式 SWE-bench Verified) | 暫無官方 OSWorld 分數;多以 GDPval、內部任務為主 | GPT-5 系列在 MMMU 約 84.2%,5.1 預期略高,但 5.1 嚴格數字尚未統一公布 | 未公開 MathArena Apex;主打 AIME 2025 等數學 benchmark 破 94% 水準 | SWE-bench、IOI 等 coding benchmark 表現頂尖,同時強調「Adaptive / Dynamic reasoning」在 Thinking 模式降低成本、提升複雜任務正確率。 |
| Claude Sonnet 4.5 (Thinking) | 13.7(Scale HLE full set,Thinking 設定) | 77.2%(標準)/82.0%(平行 test-time compute) | 61.4%(OSWorld,電腦操作 benchmark,目前公開最高之一) | 未見官方公布 MMMU-Pro 明確數字;多項 reasoning / math benchmark 顯著提升 | 部分內部 math / AIME 類基準有公開提升幅度但未列出絕對值 | 在 SWE-bench、OSWorld、Terminal-Bench 等實戰任務表現極強,對「工具使用+長時間 Agent」特別友善。 |
| Grok 4.1(reasoning 模式) | Grok-4 系列在 HLE text-only subset 約 38.6%;發表時曾引用 ~41% 成績作為亮點 | 尚未看到權威的 SWE-bench Verified 百分比,只知在多項 coding / reasoning benchmark 表現一線 | 未見公開 OSWorld 百分比;但在 EQ-Bench3(情緒與角色扮演)拿到頂尖表現 | MMMU / 多模態推理成績多在「第一梯隊」但缺乏統一表格 | 暫無公開 MathArena Apex 数字 | LMArena text arena 名次非常前面,EQ-Bench3 中情感/共感表現被特別拿出來強調,適合聊天、情境角色與創意任務。 |
| Kimi K2 Thinking | 44.9%(Moonshot 對 HLE 的完整評測,常被稱為 SOTA) | Vals.ai 評測指出其在 SWE-bench 屬「強勢」一線,但並未在公開頁明列百分比 | 暫無 OSWorld 官方數字;但在瀏覽+工具 benchmark BrowseComp 拿到 60.2% 左右高分 | Humanity's Last Exam、BrowseComp 等「多步推理+工具」基準中展現非常穩定的長鏈推理能力 | 未公開 MathArena Apex;主打 INT4 量化下仍維持高推理表現 | 被設計成「thinking agent」,可以在 200–300 次連續 tool call 下維持穩定目標導向行為,在代理人場景非常吃香。 |
怎麼解讀這張 Gemini 3 Pro benchmark 對照?
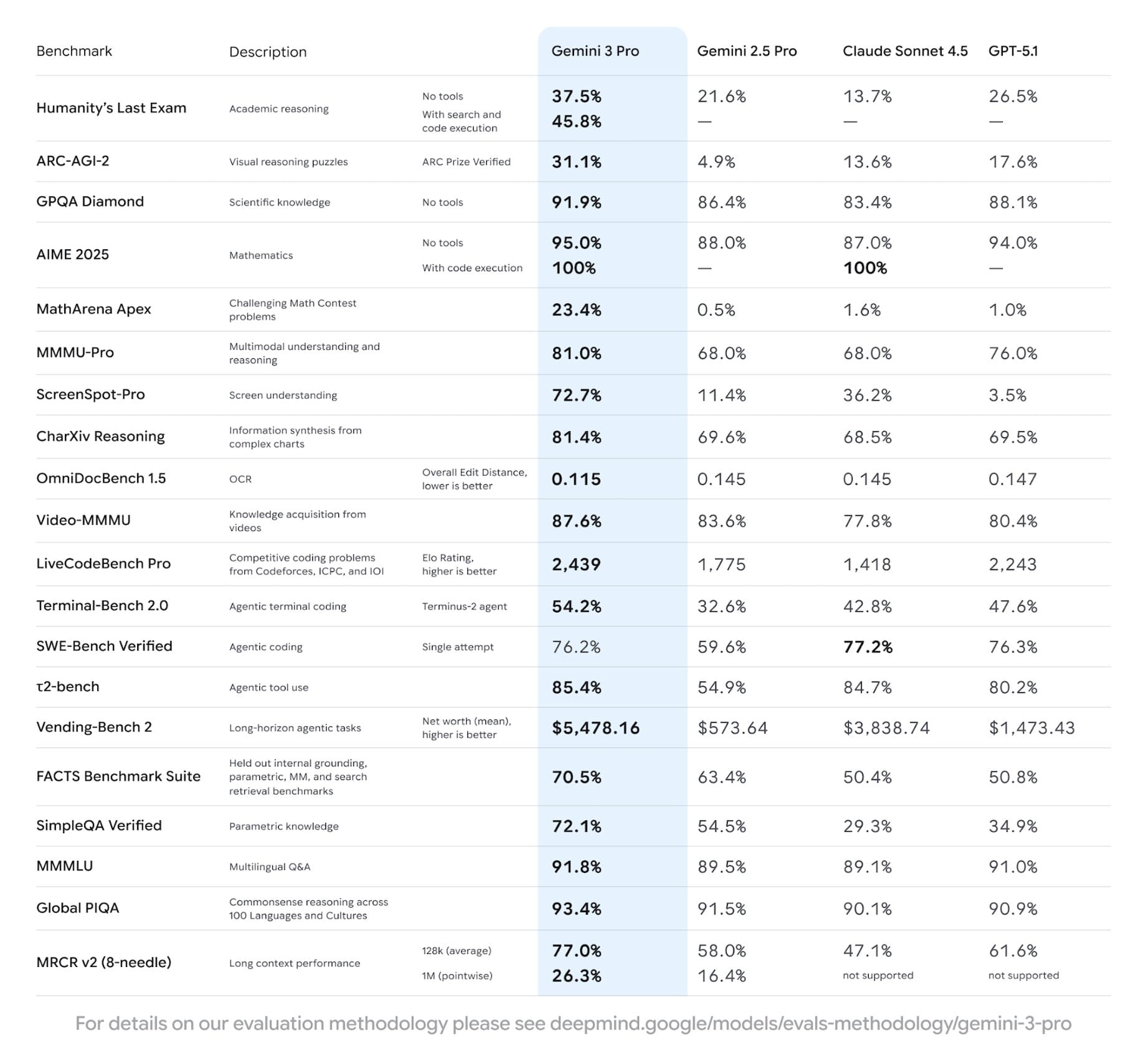
首先,如果只看 Humanity's Last Exam 這種「超硬考試」,你可以粗略把現在前沿模型排成:Kimi K2 Thinking ≳ Grok 4.x ≳ Gemini 3 Pro ≳ GPT-5.1 Thinking ≳ Claude Sonnet 4.5,不過這裡牽涉到 full set、text-only subset、有無用工具等差異,所以只能當成「哪幾家在超高難度學術題上特別強」的方位感。
再看 SWE-bench Verified 這類真實 GitHub issue 修 bug 的 coding benchmark,目前最穩的王者是 Claude Sonnet 4.5,GPT-5.1 Thinking 緊追在後,這兩個如果你主要是做軟體開發或 DevOps,自然是優先考慮的選項;反過來說,Gemini 3 Pro、Grok 4.1、Kimi K2 Thinking 雖然在推理/多模態很強,但在 SWE-bench 的公開數據還不夠密集,選型時就需要多靠自己實測。
最後,把 多模態+agent 能力 也算進來的話,Gemini 3 Pro 在 MMMU-Pro、Video-MMMU 這些視覺+影片推理 benchmark 上確實很有優勢,Claude Sonnet 4.5 則在 OSWorld / 電腦操作類任務衝在最前面,而 Kimi K2 Thinking 則可以看成「長鏈推理+tool orchestration 專精」的選手,特別適合當成 multi-step agent 的核心大腦。
如果你想多了解這些 benchmark 在實際產品、行銷自動化或數位產品設計上的應用,可以搭配一些專門談生成式 AI 的教學內容來看,會更容易把這些「分數」轉成實際可以落地的策略。
讓 AI 為你的業務創造價值
看完 Google Gemini 3 的完整解析,你是否也感受到 AI 正在重塑整個數位世界? 從搜尋引擎到企業應用,從內容創作到程式開發,AI 的影響力已經滲透到每一個角落。
我們的團隊深耕 AI 應用、數位轉型和商業策略多年,已協助眾多企業成功導入 AI 解決方案,實現效率提升與成本優化。從策略規劃到技術實施,從團隊培訓到持續優化,我們提供端到端的專業服務。
準備好讓 AI 為你的業務創造價值了嗎? 立即預約諮詢,讓我們一起探索 AI 如何加速你的業務成長。
權威資料來源
本文參考了以下權威機構與研究單位的資料:
作者簡介
我是一位專注於 AI 技術與數位轉型的研究者,長期關注大型語言模型的發展與應用。在觀察 Gemini 3 的發布過程中,我深刻體會到 AI 競爭已經進入白熱化階段。每家公司都在試圖找到自己的定位——Google 選擇了全產品線滲透策略,OpenAI 專注於開發者生態,Anthropic 則強調安全性與實用性。
對於企業來說,重要的不是追逐最新的模型,而是找到最適合自己業務場景的解決方案。Gemini 3 的多模態能力確實令人印象深刻,但它能否在你的實際應用中發揮價值,還需要透過實測與評估來驗證。我始終相信,AI 的真正價值在於解決實際問題,而不是追求 benchmark 分數。這也是我在 Tenten 工作時,始終秉持的理念——用技術創造真實的商業價值。










