
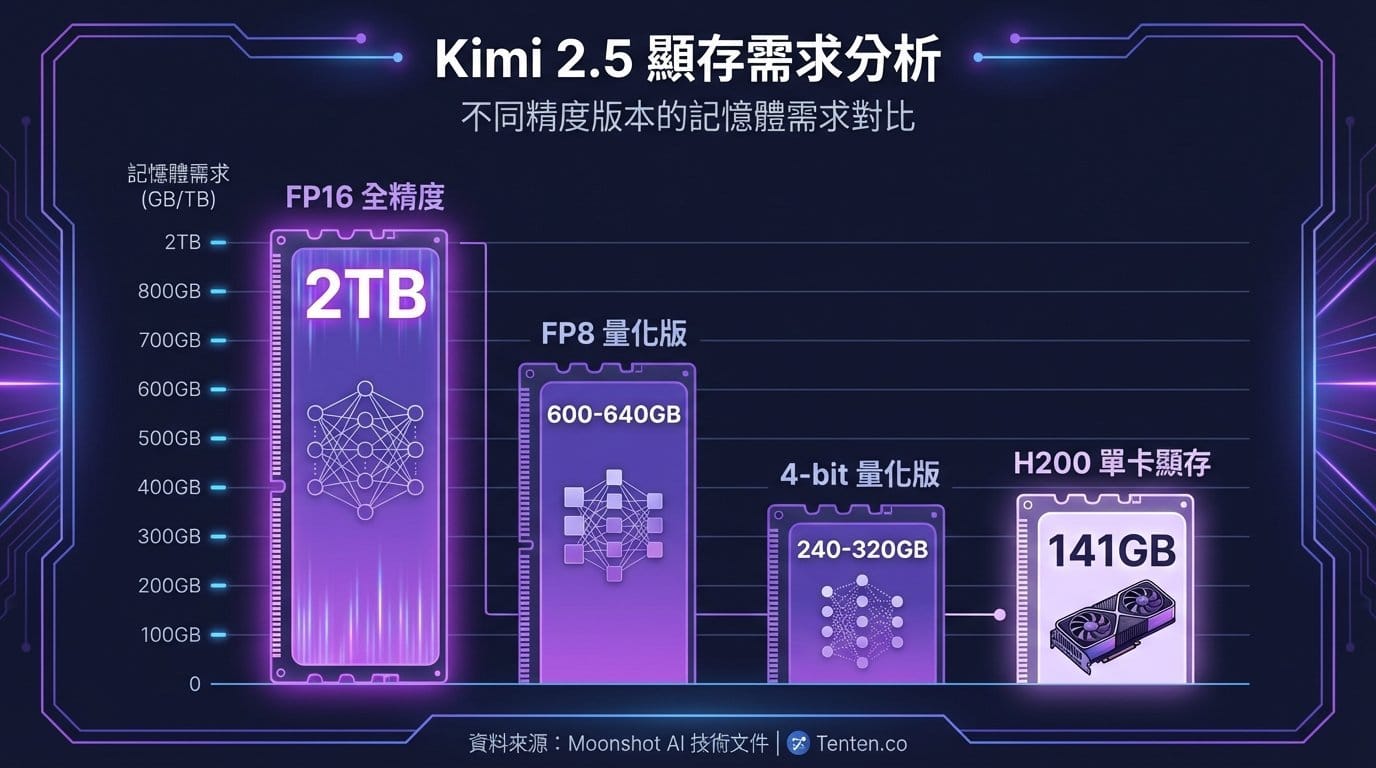
Moonshot AI 於 2026 年 1 月發布 Kimi K2.5,這款一兆參數的混合專家模型(MoE)採用原生 INT4 量化技術,將模型體積從完整精度的 2TB 壓縮至約 600GB。對於擁有 Mac Studio M3 Ultra 512GB 統一記憶體配置的使用者而言,透過適當的量化版本與推論優化策略,確實可在單機環境下運行這款旗艦級開源模型。
硬體需求與記憶體規劃
Mac Studio M3 Ultra 配備 512GB 統一記憶體,理論上可承載 Unsloth 提供的 1.8-bit 動態量化版本(UD-TQ1_0),該版本約需 240GB 磁碟空間。根據 Unsloth 官方指南的建議,運行 Kimi K2.5 的基本條件為「磁碟空間 + RAM + VRAM ≥ 240GB」。512GB 統一記憶體意味著系統能將整個模型載入記憶體,無需依賴磁碟交換,這是獲得合理推論速度的關鍵。
Jeff Geerling 於 2025 年 12 月的實測報告顯示,四台 Mac Studio M3 Ultra 組成的叢集(總計 1.5TB 記憶體)運行 Kimi K2 Thinking 可達約 28 tokens/秒,總功耗低於 500 瓦。這數據為單機配置提供了參考基準:單機 512GB 環境下,預期推論速度約在 5-15 tokens/秒區間,具體表現取決於量化精度與 context 長度。
量化版本選擇策略
Kimi K2.5 採用 DeepSeek V3 架構的改良版本,原生即為 INT4 量化格式。選擇適合 512GB Mac Studio 的量化版本時,需考量以下三個面向:
| 量化類型 | 檔案大小 | 記憶體需求 | 適用場景 |
|---|---|---|---|
| UD-TQ1_0(1.8-bit) | 240GB | 240GB+ | 記憶體受限環境,接受較低精度 |
| UD-Q2_K_XL(2-bit) | 375GB | 380GB+ | 平衡大小與品質的推薦選擇 |
| UD-Q4_K_XL(4-bit) | 約 600GB | 600GB+ | 接近原生 INT4 品質,需 512GB 以上 |
對於 512GB 配置,UD-Q2_K_XL 是兼顧品質與實用性的選項。若接受品質折損,UD-TQ1_0 可釋放更多記憶體供 context window 使用。值得注意的是,由於 Kimi K2.5 原生即為 INT4 格式,使用 Q4_K_XL 或 Q5 量化即等同於接近完整精度運行。
安裝與部署流程
部署 Kimi K2.5 於 Mac Studio 需透過 llama.cpp 框架,這是目前在 Apple Silicon 上運行大型語言模型的主流方案。完整安裝流程如下:
編譯 llama.cpp 時,Mac 環境應停用 CUDA 並啟用 Metal 加速:
git clone https://github.com/ggml-org/llama.cpp
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_METAL=ON
cmake --build llama.cpp/build --config Release -j --clean-first \
--target llama-cli llama-server
cp llama.cpp/build/bin/llama-* llama.cpp
下載模型時,建議使用 Hugging Face CLI 工具並指定量化版本:
pip install -U huggingface_hub hf_transfer
hf download unsloth/Kimi-K2.5-GGUF \
--local-dir ~/models/kimi-k2.5 \
--include "*UD-Q2_K_XL*"
啟動推論時,針對 MoE 架構的特性進行優化配置:
LLAMA_SET_ROWS=1 ./llama.cpp/llama-cli \
--model ~/models/kimi-k2.5/Kimi-K2.5-UD-Q2_K_XL-00001-of-00008.gguf \
--temp 0.6 \
--min-p 0.01 \
--top-p 0.95 \
--ctx-size 16384 \
--fit on \
--jinja
--fit on 參數讓 llama.cpp 自動分配 GPU 與 CPU 資源。LLAMA_SET_ROWS=1 環境變數可小幅提升推論效能。
MoE 層卸載策略
Kimi K2.5 的 MoE 架構在每次推論時僅激活部分專家網路。針對記憶體受限環境,可透過 -ot 參數將 MoE 層卸載至 CPU,保留 GPU 記憶體給 attention 層與共享專家:
# 將所有 MoE 層卸載至 CPU
-ot ".ffn_.*_exps.=CPU"
# 僅卸載 up 與 down projection 層
-ot ".ffn_(up|down)_exps.=CPU"
# 僅卸載 up projection 層(保留更多 GPU 資源)
-ot ".ffn_(up)_exps.=CPU"
卸載程度與推論速度呈反向關係:卸載越多,GPU 壓力越低但速度越慢。512GB 配置下,使用 Q2_K_XL 量化並適度卸載 MoE 層,可在維持可用速度的前提下預留足夠記憶體。
Context 長度與記憶體消耗
Kimi K2.5 支援最高 256K tokens 的 context 長度,但實際記憶體消耗隨 context 線性成長。Unsloth 文件建議從較小的 context 開始測試系統穩定性:
| Context 長度 | 預估額外記憶體消耗 |
|---|---|
| 16,384 tokens | 基準 |
| 32,768 tokens | +8-12GB |
| 65,536 tokens | +20-30GB |
| 98,304 tokens(建議值) | +35-50GB |
對於 512GB 配置搭配 Q2_K_XL 量化(約 380GB),剩餘約 130GB 可供 KV cache 與系統使用。實務上,將 context 設定在 32K-64K 區間是較穩妥的選擇。
作為 API 伺服器運行
若需將 Kimi K2.5 整合至現有工作流程或應用程式,可啟動 OpenAI 相容的 API 伺服器:
LLAMA_SET_ROWS=1 ./llama.cpp/llama-server \
--model ~/models/kimi-k2.5/Kimi-K2.5-UD-Q2_K_XL-00001-of-00008.gguf \
--alias "kimi-k2.5" \
--min-p 0.01 \
--ctx-size 16384 \
--port 8001 \
--fit on \
--jinja \
--kv-unified
--kv-unified 參數在 llama.cpp 中可提升推論效能。伺服器啟動後,可透過 Python 的 OpenAI 套件呼叫:
from openai import OpenAI
client = OpenAI(
base_url="http://127.0.0.1:8001/v1",
api_key="sk-no-key-required"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "說明 MoE 架構的優勢"}]
)
print(response.choices[0].message.content)
效能預期與實際限制
根據社群回報與官方數據,單台 Mac Studio M3 Ultra 512GB 運行 Kimi K2.5 的效能預期:
| 配置 | 推論速度 | 備註 |
|---|---|---|
| UD-TQ1_0 + 全 MoE 卸載 | 5-10 tokens/秒 | 最省記憶體配置 |
| UD-Q2_K_XL + 部分卸載 | 8-15 tokens/秒 | 平衡配置 |
| UD-Q4_K_XL + 最小卸載 | 10-21 tokens/秒 | 接近完整品質,需謹慎管理記憶體 |
DEV Community 的測試報告指出,雙 Mac Studio M3 Ultra(各 512GB)的組合約可達 21 tokens/秒。這數據暗示單機配置在最佳情況下可能接近此數值的一半至三分之二。
實際限制包含:目前 llama.cpp 的 Kimi K2.5 支援尚未完整涵蓋視覺功能,因此多模態應用需等待後續更新。此外,長時間高負載運行時,建議監控系統溫度與記憶體壓力。
與雲端 API 的成本比較
Moonshot AI 官方 API 定價為輸入 USD 0.60/百萬 tokens、輸出 USD 3.00/百萬 tokens。對於持續性的研究或開發需求,本機部署的攤提成本可能更具優勢:
| 方案 | 初期投資 | 月營運成本 | 適用情境 |
|---|---|---|---|
| Mac Studio M3 Ultra 512GB | 約 USD 10,000 | 電費約 USD 30-50 | 高頻使用、隱私敏感、離線需求 |
| 官方 API | 無 | 依用量計費 | 偶發性使用、需要最新版本 |
對於每月使用量超過數十億 tokens 的情境,本機部署的邊際成本優勢明顯。反之,輕度使用者採用 API 方案更為經濟。
延伸閱讀
本機運行大型語言模型涉及多項技術細節,以下資源可作為進一步學習的起點:
- 適合在 Mac 上運行的最佳 LLM 推薦指南
- DeepSeek:開源模型與蒸餾技術驅動的 AI 革命
- 運行 DeepSeek R1: Mac Studio M3 Ultra, DGX, RTX 5090, A6000 Ada 深度評測
- 最佳 LLM API 比較:OpenAI、Llama、Gemini、Sonar、Claude
- Apple Mac 購買指南:該選擇哪款晶片?
引用來源
- Unsloth Documentation. "Kimi K2.5: How to Run Locally Guide." https://unsloth.ai/docs/models/kimi-k2.5
- Jeff Geerling. "1.5 TB of VRAM on Mac Studio - RDMA over Thunderbolt 5." December 2025. https://www.jeffgeerling.com/blog/2025/15-tb-vram-on-mac-studio-rdma-over-thunderbolt-5/
- Hugging Face. "unsloth/Kimi-K2.5-GGUF." https://huggingface.co/unsloth/Kimi-K2.5-GGUF
- Moonshot AI. "Kimi K2.5 Official Repository." https://huggingface.co/moonshotai/Kimi-K2.5
作者觀點
Kimi K2.5 代表開源 AI 模型的重要里程碑,其原生 INT4 量化設計顯示 Moonshot AI 從訓練階段即考量部署效率。對於已投資高階 Apple Silicon 工作站的開發者與研究者,本機運行一兆參數模型不再是遙不可及的想像,而是具體可行的方案。然而,我觀察到社群對於極端量化(如 1.8-bit)在程式碼生成任務上的品質降低有所顧慮,選擇量化版本時需根據實際應用場景權衡。
— Ewan Mak, Tenten.co
若您正評估本機 AI 部署的硬體與軟體架構,或希望將大型語言模型整合至現有業務流程,歡迎與 Tenten 團隊預約諮詢,我們可協助規劃符合您需求的解決方案。










