
2026 年初,Apple 在 macOS Tahoe 26.2 中引入了 RDMA over Thunderbolt 5 功能,讓多台 Mac 能夠透過高速連接共享記憶體資源。這項技術突破意味著:配備 512GB 統一記憶體的兩台 Mac Studio M4 Ultra,總計可提供 1TB 的記憶體池,足以運行 Moonshot AI 推出的兆參數級開源模型 Kimi K2.5。
本文將詳細說明硬體需求、軟體配置流程,以及實際部署時需注意的效能調校要點。
為什麼選擇 Mac Studio 集群運行大型語言模型
傳統上,運行兆參數規模的 大型語言模型需要昂貴的 NVIDIA GPU 伺服器。一組能夠運行 Kimi K2.5 完整版本的 GPU 集群,硬體成本動輒超過 USD 100,000,且耗電量驚人。
Mac Studio M4 Ultra 採用 Apple Silicon 統一記憶體架構,單機最高可配置 512GB 記憶體。兩台機器透過 Thunderbolt 5 連接後,RDMA 技術讓記憶體存取延遲從傳統 TCP 的約 300 微秒降至 5-9 微秒。這種低延遲特性對於分散式推論至關重要——模型權重分布在多台機器時,節點間的通訊效率直接決定了 token 生成速度。
Jeff Geerling 在 2025 年 12 月的測試中,使用四台 Mac Studio M3 Ultra 組成的集群(總計 1.5TB 記憶體),運行 Kimi K2 Thinking 模型達到約 28 tokens/秒的生成速度,整體功耗不到 500 瓦。相較之下,同等規模的 NVIDIA GPU 集群功耗可能達到 5,000 瓦以上。

硬體需求與配置規劃
最低配置:兩台 Mac Studio M4 Ultra
| 項目 | 規格要求 |
|---|---|
| 機型 | Mac Studio M4 Ultra × 2 |
| 記憶體 | 每台 512GB 統一記憶體(總計 1TB) |
| 儲存空間 | 每台至少 500GB 可用空間 |
| 連接埠 | Thunderbolt 5 × 2(用於 RDMA 連接) |
| 作業系統 | macOS Tahoe 26.2 或更新版本 |
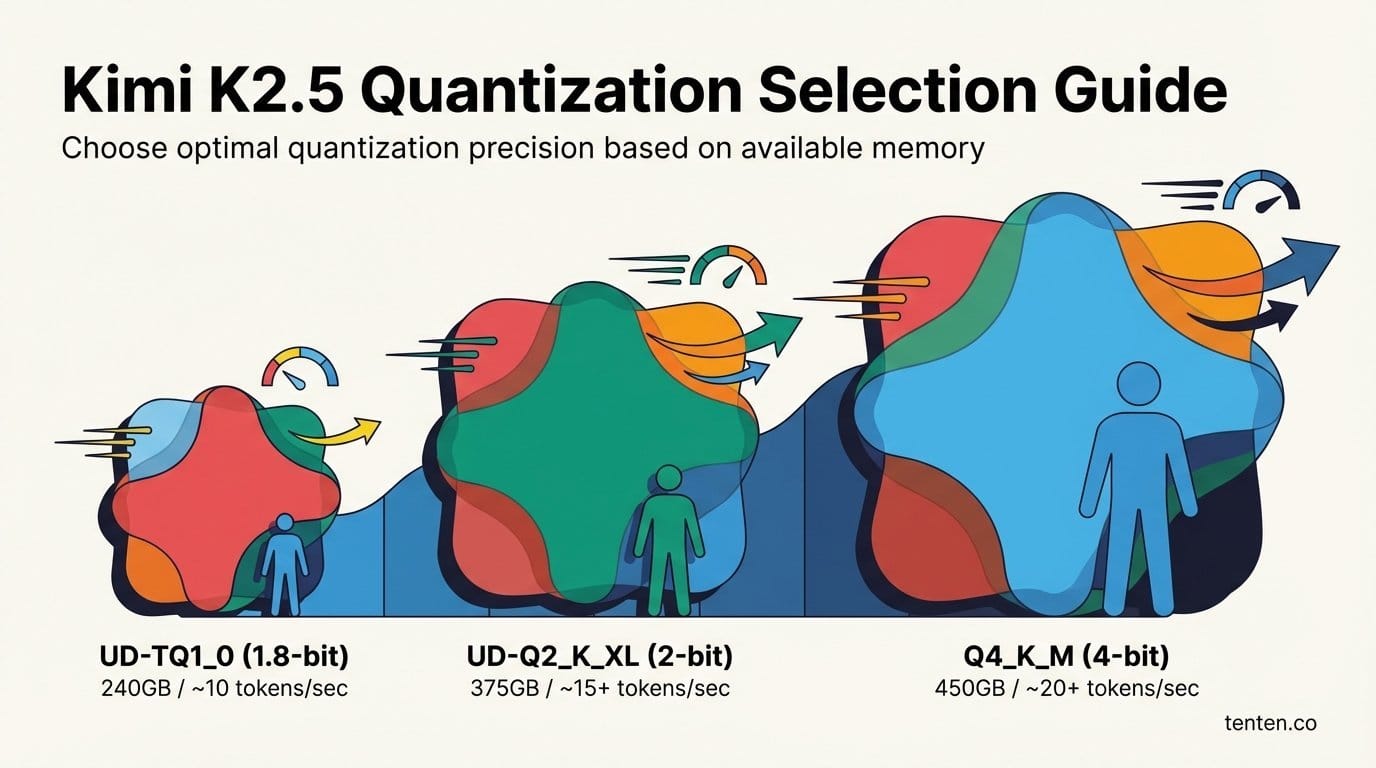
Kimi K2.5 的量化版本有多種選擇。根據 Unsloth 團隊的測試數據:
| 量化版本 | 檔案大小 | 最低記憶體需求 | 預期速度 |
|---|---|---|---|
| UD-TQ1_0(1.8-bit) | 約 240GB | 240GB+ | 約 10 tokens/秒 |
| UD-Q2_K_XL(2-bit) | 約 375GB | 375GB+ | 約 15+ tokens/秒 |
| Q4_K_M(4-bit) | 約 450GB | 450GB+ | 約 20+ tokens/秒 |
對於 1TB 總記憶體的配置,建議選擇 UD-Q2_K_XL 或 Q4_K_M 量化版本,以獲得品質與速度的最佳平衡。
連接拓撲
兩台 Mac Studio 之間使用單條 Thunderbolt 5 線材直接連接即可。Thunderbolt 5 提供最高 80Gb/s 的雙向頻寬,足以支撐 RDMA 通訊需求。
注意事項:Mac Studio 上靠近乙太網路埠的 Thunderbolt 5 連接埠無法用於 RDMA,請使用其他四個 Thunderbolt 5 埠。
軟體環境建置
步驟一:升級至 macOS Tahoe 26.2
RDMA over Thunderbolt 功能僅在 macOS Tahoe 26.2 及更新版本中提供。在「系統設定」→「一般」→「軟體更新」中確認系統版本。
步驟二:啟用 RDMA 功能
RDMA 功能預設為關閉狀態,需透過恢復模式啟用。在兩台 Mac Studio 上分別執行以下步驟:
- 關閉 Mac
- 按住電源按鈕約 10 秒,直到出現開機選單
- 選擇「選項」進入恢復模式
- 恢復模式載入後,從「工具程式」選單開啟「終端機」
- 執行以下指令:
bputil -a rdma
- 重新啟動 Mac
步驟三:安裝 Exo 集群軟體
Exo 是一款開源的 AI 集群管理工具,支援 RDMA over Thunderbolt,能夠自動偵測並協調多台設備的運算資源。
方法一:安裝 macOS App
從 Exo 官方 GitHub 下載最新的 EXO-latest.dmg,安裝後 App 會在背景運行並自動設定網路配置。
方法二:從原始碼安裝
git clone https://github.com/exo-explore/exo.git
cd exo
pip install -e .
確保 Python 版本為 3.12.0 或更新,舊版 Python 的 asyncio 實作存在已知問題。
步驟四:下載 Kimi K2.5 模型
安裝 Hugging Face CLI 工具後下載模型:
pip install huggingface_hub hf_transfer
python -c "
from huggingface_hub import snapshot_download
snapshot_download(
repo_id='unsloth/Kimi-K2.5-GGUF',
local_dir='unsloth/Kimi-K2.5-GGUF',
allow_patterns=['*UD-Q2_K_XL*']
)
"
下載過程可能需要數小時,視網路頻寬而定。375GB 的模型檔案會分成多個 shard 儲存。
使用 Exo 運行 Kimi K2.5
啟動集群
在兩台 Mac Studio 上分別執行:
exo
Exo 會自動透過 RDMA 偵測對方節點並建立連接。無需額外配置——這正是 Exo 的設計哲學:零配置的分散式運算。
啟動後,Exo 會在 http://localhost:52415 提供 Web UI 介面,同時在相同位址提供 OpenAI 相容的 API 端點。
透過 API 發送請求
curl http://localhost:52415/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "kimi-k2.5",
"messages": [{"role": "user", "content": "解釋量子糾纏的基本原理"}],
"temperature": 0.6
}'
推薦的推論參數
根據 Moonshot AI 官方建議:
| 模式 | 溫度 | top_p | min_p |
|---|---|---|---|
| 即時模式(Instant) | 0.6 | 0.95 | 0.01 |
| 思考模式(Thinking) | 1.0 | 0.95 | 0.01 |
建議將 repeat penalty 設為 1.0(即關閉),以避免生成時出現不自然的重複迴避行為。
使用 llama.cpp 作為替代方案
若不使用 Exo,也可以直接透過 llama.cpp 運行模型。llama.cpp 目前尚未支援 RDMA,但透過 RPC 機制仍可實現分散式推論,只是效能會有所折損。
編譯 llama.cpp(Apple Silicon)
git clone https://github.com/ggml-org/llama.cpp
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_METAL=ON
cmake --build llama.cpp/build --config Release -j \
--target llama-cli llama-server
cp llama.cpp/build/bin/llama-* llama.cpp/
運行模型
LLAMA_SET_ROWS=1 ./llama.cpp/llama-cli \
--model unsloth/Kimi-K2.5-GGUF/UD-Q2_K_XL/Kimi-K2.5-UD-Q2_K_XL-00001-of-00008.gguf \
--temp 0.6 \
--min-p 0.01 \
--top-p 0.95 \
--ctx-size 16384 \
--fit on \
--jinja
--fit on 參數讓 llama.cpp 自動將模型分配到可用的 GPU 和 CPU 資源。LLAMA_SET_ROWS=1 環境變數可略微提升效能。
效能調校建議
記憶體分配策略
Kimi K2.5 採用 Mixture-of-Experts(MoE)架構,每次推論僅啟用部分專家網路。可透過 -ot 參數將 MoE 層卸載至 CPU,將 GPU 記憶體保留給注意力層和共享專家:
# 將所有 MoE 層卸載至 CPU
-ot ".ffn_.*_exps.=CPU"
# 僅卸載 up 和 down 投影層
-ot ".ffn_(up|down)_exps.=CPU"
上下文長度與記憶體消耗
Kimi K2.5 支援最高 256K token 的上下文長度。實際使用時,上下文長度會顯著影響記憶體消耗:
| 上下文長度 | 額外記憶體消耗 |
|---|---|
| 16K tokens | 約 8GB |
| 64K tokens | 約 32GB |
| 128K tokens | 約 64GB |
建議從較小的上下文長度(如 16384)開始測試,確認系統穩定後再逐步增加。
散熱管理
持續運行大型模型會產生顯著熱量。Mac Studio 的散熱設計雖然優秀,但在高負載情況下仍建議:
- 確保通風良好,避免將機器放置在密閉空間
- 監控系統溫度,可使用
sudo powermetrics --samplers smc查看 - 考慮外部散熱方案,如桌面風扇或散熱底座
Kimi K2.5 的技術特點
Kimi K2.5 是 Moonshot AI 在 Kimi K2 基礎上的重大升級,具備以下特性:
原生多模態能力:經過約 15 兆個視覺與文字混合 token 的持續預訓練,K2.5 能夠處理圖像輸入並進行跨模態推理。目前 llama.cpp 的視覺支援尚在開發中。
強化的代理能力:K2.5 針對工具呼叫和自主問題解決進行了專門優化,在 SWE-Bench、BrowseComp 等代理任務基準測試中達到領先水準。
原生 INT4 量化:模型在後訓練階段採用量化感知訓練(QAT),使 4-bit 量化版本幾乎不損失品質,同時大幅降低記憶體需求。
根據官方基準測試數據,Kimi K2.5 在多項任務上與 GPT-5.2、Claude 4.5 Opus 等頂級閉源模型競爭:
| 基準測試 | Kimi K2.5 | GPT-5.2 | Claude 4.5 Opus |
|---|---|---|---|
| HLE(含工具) | 50.2 | 45.5 | 43.2 |
| AIME 2025 | 96.1 | 100 | 92.8 |
| SWE-Bench Verified | 76.8 | 80.0 | 80.9 |
成本效益分析
兩台 Mac Studio M4 Ultra(512GB 配置)的總成本約為 USD 20,000-24,000,視具體配置而定。相較於同等能力的 GPU 伺服器方案:
| 方案 | 硬體成本 | 年度電費(估計) | 維護複雜度 |
|---|---|---|---|
| 2× Mac Studio M4 Ultra | USD 約 22,000 | 約 USD 300 | 低 |
| 4× NVIDIA H100 伺服器 | USD 100,000+ | USD 約 5,000+ | 高 |
| 雲端 GPU 租用(年) | N/A | USD 約 50,000+ | 中 |
對於需要本地部署大型語言模型的企業研究團隊或獨立開發者而言,Mac Studio 集群提供了一個在成本、效能、與維護負擔之間取得平衡的可行選項。

常見問題排除
問題:Exo 無法偵測到另一台 Mac
確認兩台機器都已啟用 RDMA,且 Thunderbolt 線材正確連接。可使用 networksetup -listallhardwareports 檢查 Thunderbolt 網路介面是否出現。
問題:模型載入時記憶體不足
嘗試使用較低的量化版本(如 UD-TQ1_0),或減少上下文長度。也可以關閉其他佔用記憶體的應用程式。
問題:生成速度過慢
檢查 RDMA 是否正確啟用。若使用 llama.cpp,確認已使用 --fit on 或適當的 -ot 參數配置 GPU/CPU 負載分配。
問題:系統在運行時當機
RDMA over Thunderbolt 仍是相對新的技術,穩定性可能不如成熟方案。建議設定自動化腳本以便快速重啟集群,並保持系統更新至最新版本。
延伸應用
掌握了 Mac Studio 集群的基礎部署後,可以進一步探索:
- 本地 AI 代理開發:利用 Kimi K2.5 的工具呼叫能力,建構能夠自主執行任務的 AI 系統
- 私有化企業 LLM 部署:在不將資料傳送至雲端的前提下,為企業內部提供大型語言模型服務
- 模型微調實驗:結合 Unsloth 等工具,在本地進行針對特定領域的模型微調
參考資源
- Unsloth Kimi K2.5 部署指南
- Exo GitHub Repository
- Jeff Geerling: 1.5 TB VRAM on Mac Studio
- Apple MLX Framework
- Hugging Face: Kimi K2.5 GGUF
關於作者
Erik Chen 是 Tenten 的 Founder,專注於 AI 基礎設施與企業數位轉型策略。他認為本地 LLM 部署不僅是技術選擇,更是數據主權與營運彈性的戰略考量。隨著開源模型能力逐漸接近閉源服務,企業應積極評估混合部署架構的可行性。
若您正在評估大型語言模型的本地部署方案,或希望了解如何將 AI 能力整合至現有業務流程,歡迎與 Tenten 團隊預約諮詢,探討最適合您需求的解決方案。










