
RAG 管道的結構性、數學性與經濟性限制
過去兩年間,AI 社群悄然形成一個特殊的信念:智能的未來在於建構 Agent。放眼望去,工程師們正在打造 RAG 管道、串接各種工具、用編排框架包裝大型語言模型,然後將成果稱為「AI 系統」。
這看起來很厲害,感覺很有生產力,也滿足了工程師想要動手做的本能。
然而,有個令人不安的事實:多數 AI Agent 並非進步,而是裝飾。它們無法有意義地擴展智能,無法創造新的經濟價值,且往往撐不過下一代基礎模型的更新。在大多數情況下,建構 AI Agent 並非邁向智能未來的一步,而是暫時偏離了對智能本質的理解。
這不是技術論點,而是結構性論點。

數學現實的簡單說明
大型語言模型本質上是一個函數近似器。LLM 產出的所有內容,都是輸入訊號與其學習到的內部表徵的轉換。當我們在 LLM 之上堆疊 RAG 管道、工具呼叫或多代理編排時,實際上是在做兩件事:將額外的上下文注入輸入,以及將輸出路由到外部系統。
關鍵問題在於:這些操作中,沒有任何一項擴展了模型的推理能力。它們只是在模型周圍移動資料,讓輸出看起來更有用。模型本身的智能並未因此提升。
根據 Qodo 的產業分析,87% 的企業 RAG 部署未能達到預期的投資報酬率。主要原因包括固定的檢索邏輯、靜態的分塊策略,以及處理非結構化或分散資料的困難。這個數字揭示了一個殘酷的現實:多數 AI Agent 專案在原型階段看起來很美好,但進入生產環境後就會崩解。
基礎模型的快速演進問題
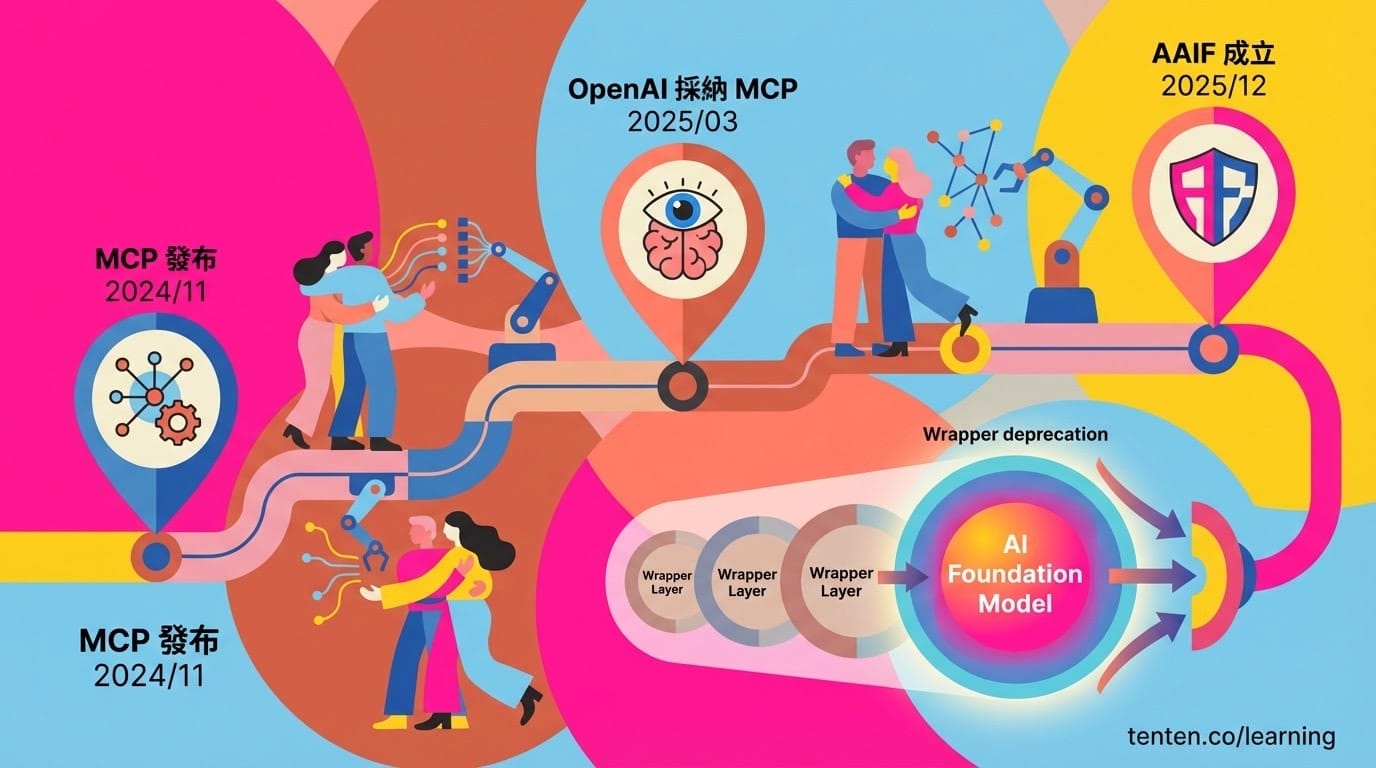
2024 年底,Anthropic 發布了 Model Context Protocol (MCP),讓開發者能以標準化方式將大型語言模型連接到外部工具。2025 年 3 月,OpenAI 正式採納 MCP,並將其整合至 Agents SDK、Responses API 和 ChatGPT 桌面版。這個決策的背後邏輯很清楚:維護專有整合介面的摩擦成本,已經無法與快速擴張的開放生態系統抗衡。
Foundation Capital 的分析指出,「護城河不再是模型本身,因為模型正逐漸商品化。真正的護城河在於整合:將 AI 連接到你特定的資料、特定的工具、特定的工作流程。」
這意味著什麼?當你花費數月建構一個精緻的 AI Agent 系統時,下一代基礎模型可能已經將你的「創新」功能內建為標準配備。你的 wrapper 層、你的編排邏輯、你引以為傲的 prompt engineering,都可能在一夜之間變得多餘。
「思維模式」的轉變
UC San Diego 的機器學習教授 Misha Belkin 在接受 IBM Think 採訪時指出:「如果要我用一句話總結 2025 年的 AI 發展,那就是我們停止讓模型變得更大,開始讓它們變得更聰明。」
這個轉變的核心是「推理時計算」(test-time compute)的崛起。與其在訓練階段堆疊更多參數,新一代模型選擇在推論時花費更多計算資源:生成中間步驟、探索替代方案、驗證自己的輸出。
IBM Think 的報告進一步指出,2025 年的主導主題是「透過限制實現能力」。閃亮的效能指標正在讓位給可靠性指標。這對 AI Agent 開發者來說是個警訊:當基礎模型本身變得更擅長自我驗證和多步推理時,你在外層堆疊的那些「增強」邏輯,可能反而成為系統的弱點。
RAG 管道的結構性困境
讓我們具體看看 RAG 管道在生產環境中面臨的問題。
Salesforce 的技術團隊在一篇深度文章中坦承:「突破性的多跳推理研究論文,在你的 API 閘道於並發負載下返回 503 Service Unavailable 時毫無意義。Agentic 和 RAG 系統首先是分散式軟體系統,其次才是 AI 模型。」
這段話點出了一個核心問題:多數所謂的「AI 工程」,實際上還停留在原型階段——不過是在標準 ChromaDB 實例上運行一個 ReAct 迴圈。要讓 RAG 系統真正可靠,你需要:
- 精密的資料擷取與分塊管道:固定大小的分塊策略不夠。進階策略需要語義分塊、基於文件結構的遞歸分塊,以及針對 PDF 和 HTML 等異質資料類型的客製解析。
- 混合檢索:單純依賴稠密向量搜尋是致命錯誤。最先進的檢索需要結合稠密搜尋(使用如 e5-large-v2 等微調過的嵌入模型)與稀疏的關鍵字搜尋(如 BM25 或 SPLADE)。
- 重排序與評估:初始檢索的 top-k 結果必須經過更強大但較慢的模型重新排序。此外,檢索品質必須透過 Precision@k、Mean Reciprocal Rank (MRR) 和 Normalized Discounted Cumulative Gain (nDCG) 等指標進行系統性評估。
多數 RAG 失敗是「靜默的檢索失敗」——被 LLM 看似合理的幻覺所掩蓋。這比明顯的錯誤更危險,因為使用者無法察覺系統正在給出錯誤的答案。
「檔案優先」方法的啟示
有一個值得注意的觀點來自實際的開發經驗。一位開發者在 Medium 上分享:「如果你複雜的 RAG 管道無法打敗一個簡單地直接讀取檔案的 Agent,那就是一個強烈的訊號——所有那些複雜性根本不值得。」
這個觀點挑戰了我們對 AI 系統複雜性的預設假設。Claude Code 在 2025 年 2 月推出時,採用的是 grep 和檔案 globbing 進行程式碼導航,完全不需要向量搜尋。這與其他如 Cursor 這樣為檢索建立索引的 AI 程式碼工具形成鮮明對比。
LightOn 的技術深度分析指出:「長上下文並沒有殺死檢索。更大的上下文視窗增加成本和雜訊;檢索則將注意力聚焦在重要的地方。此外,對於典型工作負載,RAG 比長上下文方法便宜 8-82 倍,延遲也更低。」
關鍵洞察在於:2025 年的 RAG 應該是模組化且條件式的。系統應該決定「是否」檢索、「檢索什麼」、「從哪裡」檢索、「如何」檢索,而不是盲目地檢索一切。
Wrapper 層的生存危機
傳統基礎模型提供商——OpenAI、Anthropic、Google——正在從原始模型擴展到整合的 AI Agent 和應用程式。這種垂直整合正在商品化基礎模型,並佔據更高價值的編排層。
一位產業觀察者在 Medium 上分析:「我也思考了 AI 的併購視窗如何移動,並吞噬那些實際上只是薄薄 wrapper 層的產品。它們僅有的少量智慧財產,很容易被模型提供商不斷擴展的標準服務所吸納。」
這對建構 AI Agent 的新創公司來說是個嚴峻的警訊。你今天視為差異化優勢的功能,可能明天就會成為 Claude 或 GPT 的內建功能。根據 Bain & Company 的 Technology Report 2025,agentic AI 正帶來「企業技術的結構性轉變,有可能完全重新定義工作的完成方式」。這不是漸進式改進,而是根本性的典範轉移。
Agentic AI Foundation 的成立意味著什麼
2025 年 12 月,Anthropic 將 MCP 捐贈給新成立的 Agentic AI Foundation (AAIF),這是 Linux Foundation 轄下的專項基金。OpenAI 和 Block 作為共同創辦人加入,AWS、Google、Microsoft、Cloudflare 和 Bloomberg 作為支持成員。
這個發展的意義深遠。當 Anthropic、OpenAI 和 Block 共同將專案貢獻給一個中立基金會,並獲得 AWS、Google、Microsoft 和 Cloudflare 的支持時,這傳達了一個訊號:AI Agent 的基礎設施層將是開放、可互通且供應商中立的。
The Conversation 的分析指出:「另一個值得關注的發展是治理。2025 年底,Linux Foundation 宣布成立 Agentic AI Foundation,這標誌著建立共享標準和最佳實踐的努力。如果成功,它可能扮演類似 World Wide Web Consortium 的角色,塑造一個開放、可互通的 Agent 生態系統。」
這對個別開發者和小型團隊意味著什麼?你花費數月開發的專有整合方案,可能很快就會被開放標準取代。這不一定是壞事——但它確實意味著你的「創新」可能比你想像的更短命。
何時 Agent 確實有價值
並非所有 Agent 開發都是浪費時間。Anthropic 在其官方研究中明確指出了 AI Agent 最能發揮價值的場景:
- 需要對話與行動並重的任務:客戶支援是典型例子。支援互動自然遵循對話流程,同時需要存取外部資訊和執行操作。
- 具有明確成功標準的任務:例如軟體開發。程式碼解決方案可以透過自動化測試驗證;Agent 可以使用測試結果作為回饋來迭代解決方案;問題空間是良好定義且結構化的。
- 能夠建立回饋迴圈的任務:系統可以學習並改進的場景。
- 整合有意義的人類監督的任務:完全自主的 Agent 往往不如人機協作的系統可靠。
Anthropic 的建議很直接:「當需要更多複雜性時,workflow 為定義良好的任務提供可預測性和一致性,而 Agent 在需要靈活性和模型驅動決策時是更好的選擇。然而,對於許多應用程式,優化單一 LLM 呼叫加上檢索和上下文範例通常就足夠了。」
2026 年的現實檢驗
根據產業分析,到 2026 年,約 40% 的企業應用程式預計將利用任務特定的 AI Agent,而 2025 年這個比例還不到 5%。近四分之一的企業已經在擴展 agentic 系統。
但這裡有個關鍵的警告:Agent 會放大一切。當定義清晰且資料基礎穩固時,它們能帶來顯著的效率提升。但當結構不一致、業務邏輯不清楚時,它們會成為「規模化的自動混亂產生器」。
Metadata Weekly 的分析一針見血:「如果你的基礎不穩固,Agent 只會加速你的問題。」
Foundation Capital 的觀點更為直接:「過去兩年,企業 AI 總感覺『即將到來』。障礙不是模型能力,而是 AI 無法看到公司內部工作實際發生的方式——分散在不連接的工具中、被權限控制、由未記錄的例外情況塑造,並由從未進入記錄系統的人類判斷的軟邏輯維繫。」
結論:建構還是等待?
回到最初的問題:建構 AI Agent 是否浪費時間?
答案取決於你的目標和時間框架。如果你正在建構一個能在未來六個月內被基礎模型更新淘汰的 wrapper 層,那確實是浪費時間。如果你正在投資深層的系統整合、獨特的資料管道和真正解決特定領域問題的能力,那可能是值得的。
但請記住這個數字:87% 的企業 RAG 部署未能達到預期 ROI。這不是因為技術不行,而是因為多數團隊低估了從原型到生產的距離。
對於正在考慮 AI Agent 專案的團隊,我的建議是:先建立基準測試。用最簡單的方法解決問題,然後證明你的複雜系統確實帶來改進。如果一個直接讀取檔案的簡單 Agent 就能打敗你精心設計的 RAG 管道,那就是一個強烈的訊號——也許你應該重新思考整個方法。
參考來源
- Anthropic Research: Building Effective Agents
- McKinsey 配置 25,000 個 AI 代理,管顧產業面臨生存戰
- McKinsey 配置 25,000 個 AI 代理,管顧產業面臨生存戰
- Claude Cowork 正式登場:Anthropic 將 AI Agent 帶入每個人的桌面
- 史丹佛 AI 極客的「個人全景監控」系統:當 Claude Code 成為人生營運總部
- Claude 變身超級助理!6 步驟打造自動化工作流,效率狂飆 10 倍
- Manus AI Browser Operator:讓瀏覽器成為你的超級助理
- 重磅發現!Gemini 3.0 Pro 悄然上線,專為「Agent」打造,AI 即將學會自己「工作」!
關於作者
Tenten.co 編輯團隊
Tenten 專注於 AI 和科技新創產業,提供第一手的產業資訊和分析,協助企業在 AI 時代做出明智的技術決策。我們的觀點:與其追逐每一個 AI Agent 的熱潮,不如專注於建立真正可持續的競爭優勢——深層的資料整合、獨特的領域知識,以及經過驗證的使用者價值。
若您希望深入了解如何在不浪費資源的情況下有效導入 AI 技術,歡迎與 Tenten 團隊預約諮詢,我們將協助您評估真正適合企業現況的 AI 策略。










